1/ Today we're releasing AttuneBench, the first open EQ benchmark grounded in real multi-turn human-model conversations, scored against what the person actually felt and wanted at each turn.
Built by the research team at @pareto_ai in collaboration with @thoughtfullab.
Most existing EQ benchmarks rely on:
- synthetic prompts
- single-turn interactions
- third-party annotation
None directly measure how a model reads and responds to a real person across a full conversation.
We evaluated 11 leading models from major providers, across 200 conversations and 50,000+ first-person annotations.
We built FrogsGame as a new task for evaluating AI’s posttraining skills! It’s a tool-using RL environment built around a blind-start interaction loop.
Frontier agents get a container with the Qwen3-8B tokenizer, board-generating scaffolding, and @tinkerapi for remote training and inference. We ask them to post-train Qwen3-8B and submit a LoRA checkpoint. The task is still hard:
A startup shut down 9 years ago. Today, its code is in a bidding war.
The founder kept everything: Verilog RTL, a custom compiler toolchain, PCB schematics, full commit and PR history.
Most production-grade chip design stays locked inside major silicon shops.
Two labs have made offers to license the code to build RL training environments. The offers already total seven figures.
Check your hard drives.
@ccmccomb — just saw your new article on ArXiv thought this might be interesting to consider. We will have more detail to share soon but happy to discuss at any point.
model confidence tracks a shared model-agnostic signal for fact recall, not true self-knowledge.
we tested metacognitive confidence across 19 frontier models on a closed-book SQuAD task. f1 scores look reasonable (0.6–0.8), but confidence and accuracy are nearly uncorrelated between models.
the variance traces to a single shared difficulty heuristic learned during training. models differ only in their decision threshold. claude is cautious. gpt is eager.
shifting one steering coefficient on mistral-7b recovers any target model's confidence profile at ~80% agreement.
full breakdown + methods in the article
When is it worth it to hire a team, compared to one competent individual?
📢 NEW PAPER (out this month in Management Science!) by me, @MarkWhiting, @LinneaGandhi, @duncanjwatts, and @amaatouq! 🧵1/20
Baird Howland, an @AnnenbergPenn postdoc working with @WarrenCntrPenn affiliate @duncanjwatts, uses AI models to track narratives in political discourse, learning how and why specific media stories shape American worldviews. https://t.co/SnoskGP9Ag
The next step for autoresearch is that it has to be asynchronously massively collaborative for agents (think: SETI@home style). The goal is not to emulate a single PhD student, it's to emulate a research community of them.
Current code synchronously grows a single thread of commits in a particular research direction. But the original repo is more of a seed, from which could sprout commits contributed by agents on all kinds of different research directions or for different compute platforms. Git(Hub) is *almost* but not really suited for this. It has a softly built in assumption of one "master" branch, which temporarily forks off into PRs just to merge back a bit later.
I tried to prototype something super lightweight that could have a flavor of this, e.g. just a Discussion, written by my agent as a summary of its overnight run:
https://t.co/tmZeqyDY1W
Alternatively, a PR has the benefit of exact commits:
https://t.co/CZIbuJIqlk
but you'd never want to actually merge it... You'd just want to "adopt" and accumulate branches of commits. But even in this lightweight way, you could ask your agent to first read the Discussions/PRs using GitHub CLI for inspiration, and after its research is done, contribute a little "paper" of findings back.
I'm not actually exactly sure what this should look like, but it's a big idea that is more general than just the autoresearch repo specifically. Agents can in principle easily juggle and collaborate on thousands of commits across arbitrary branch structures. Existing abstractions will accumulate stress as intelligence, attention and tenacity cease to be bottlenecks.
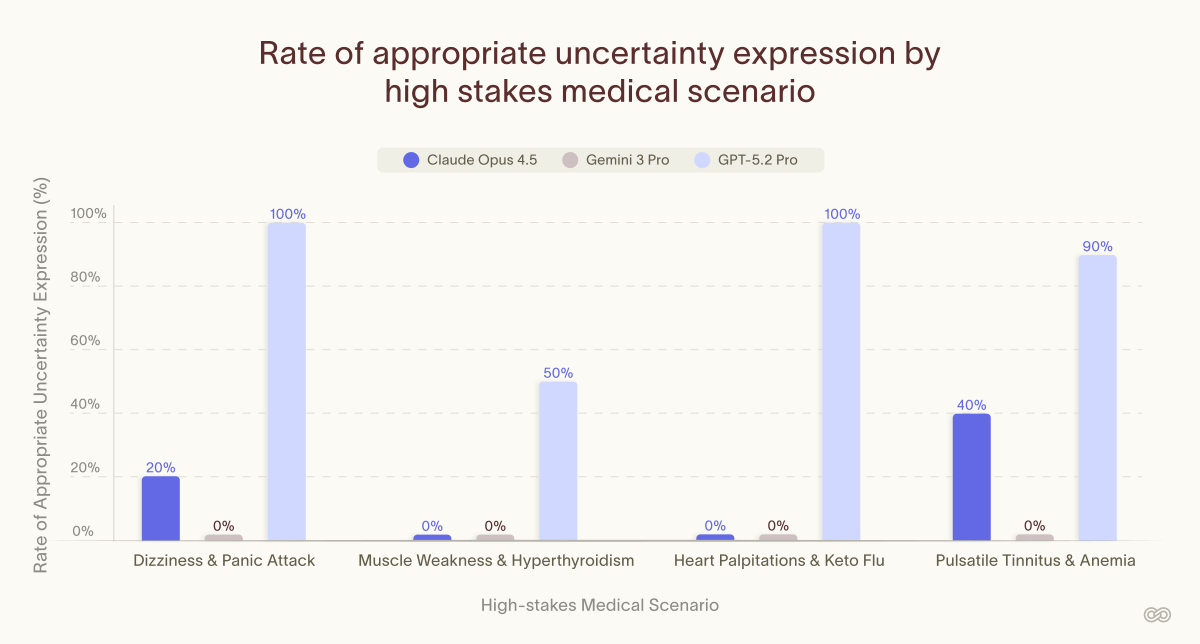
Recently I've been thinking a lot about frontier models' ability to express uncertainty, especially for high-stakes medical use cases. We evaluated this capability across models.
Early results below 👇
Gemini: 0% across every scenario.
Claude: failed on over half
GPT: best
My favorite designers can instantly switch from loose / hazy / intuitive thinking to sharp / analytical / precise thinking on demand.
Many people can do one or the other. The combination is rare!
@BenSManning Agreed, it feels like a more holistic version of the question might reveal a different answer. Do dishwashers teach me to wash dishes better? No, but they give me more leverage on my time.
The more we can measure sophisticated concepts the more we (and systems) can leverage them.
Very excited about the opportunities and capabilities this framework at @pareto_ai is unlocking
Excited to see our work coming out (+ @joshnguyen99 & @duncanjwatts)
After establishing a means to study common sense in humans (and finding it rather limited — common sense is not so common) in a prior paper, we wondered if the same challenge faced language models.
It does!
Benchmarks of LLM common sense overwhelmingly rely on correct labels to report an accuracy score. But what if your "ground truth" genuinely differs from mine?
In a new @PNASNexus paper, @DuncanJWatts, @MarkWhiting and I explore the implications of this intriguing question.
🧵⤵️
At @pareto_ai we have been working on projects to train models — of course — but also to better understand how models can improve around key day-to-day risks and challenges.
What if technology didn’t feel so… hollow?
Some friends and I just released a manifesto about a world where tech leaves us feeling nourished (along with an evolving list of theses about how we can build it)
https://t.co/sfKBVZ2zXr
With record-breaking submissions and our most competitive, gender-balanced program on record, #IC2S2’25 has officially started! Please check the updated program and plan your day. #ic2s2
Bro, I can make 1 liter of Anthrax in an afternoon, Grok just wrote me a 20 page detailed report and instructions on how to do it.
It also listed all websites where I can buy the materials and chemicals I need as a private person living in Europe.
It also made a detailed list of the equipment I need (on a budget)
It made detailed instructions on where i should deploy the anthrax for maximum death efficacy
Give me one other place on the internet where I can create this in a few minutes….