I will be speaking at #Current in 30 minutes about "Fixing the hard bits of event-driven apps with #Kafka and #Restate".
If you ever wrote an event driven app, struggled with head-of-the-line waiting, poison records, Dual-Weite problems, or observability, this talk is for you!
I need to share some news both exciting and sad:
After 12 years of building what became @ApacheFlink and @VervericaData, I decided that it is time to pass the scepter to the next generation and to move on to new endeavors.
I put down some thoughts here: https://t.co/0m3SFvWgGC
#ApacheFlink 1.14.3 is released. This release includes 163 bug fixes and minor improvements including another upgrade of Log4j (to 2.17.1).
Thanks to @thweise and @MartijnVisser82 for managing the release.
Release Notes: https://t.co/BERYp66XfQ
Tomorrow I will present "A Year in @ApacheFlink: The most important changes of the last versions" @FlinkForward Global 2021. Register to meet the Flink community, learn about the latest developments, discuss the future direction and see what others do :-)
https://t.co/VWNdePgARK
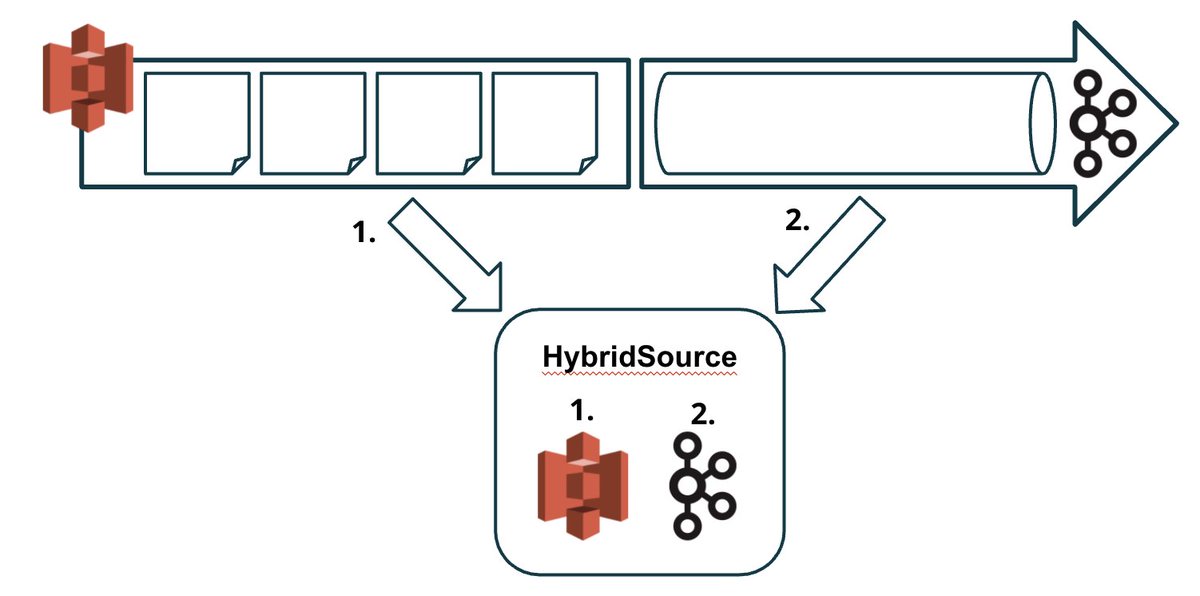
With the new HybridSource @ApacheFlink can now easily bridge the gap between historic and live data. Using this source, you can now easily bootstrap state from cold storage and then continue with live data. Kudos to @thweise! For more details see
https://t.co/k3ndqGFVBK.
✨ Session Highlight ✨
Learn how to jumpstart large window computations with @ApacheFlink and Hybrid Source with @thweise from @Apple at #flinkforward Global 2021.
Register for free: https://t.co/a2R3lkvYia
🚨New on the Flink blog:
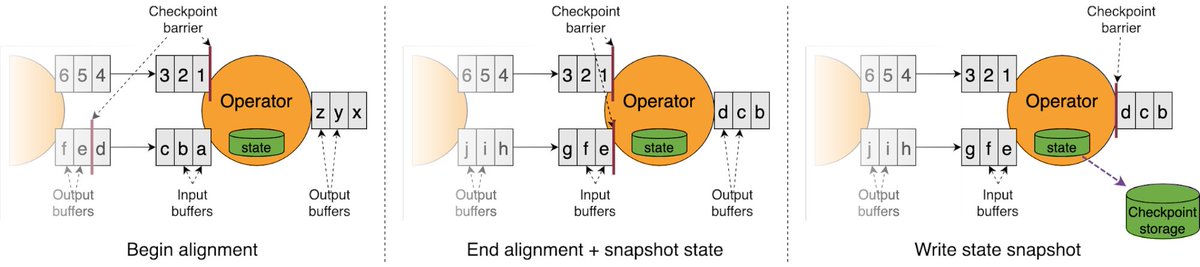
Part 1 of a deep-dive into the evolution of #ApacheFlink’s fault tolerance mechanism, recapping the very basics of checkpointing and the motivation to introduce unaligned checkpoints in Flink 1.11.
https://t.co/03UtjXw8gk
Interesting upcoming feature for @ApacheFlink 1.12: "Native Kubernetes HA for Flink".
This means you can run a highly available Flink on K8s without a Zookeeper dependency:
https://t.co/BsdFjXlcYK
We are happy to announce the next hudi release. 0.5.2 comes with tons of bug fixes and new improvements around indexing/usability. Check it out!
#apachehudi#data#spark#datalake
https://t.co/NTmL5iVA6U
How does the #ApacheFlink runner work on @ApacheBeam and why you would use both frameworks together? This new post has the answers: https://t.co/AylFkqkPQF #streamprocessing