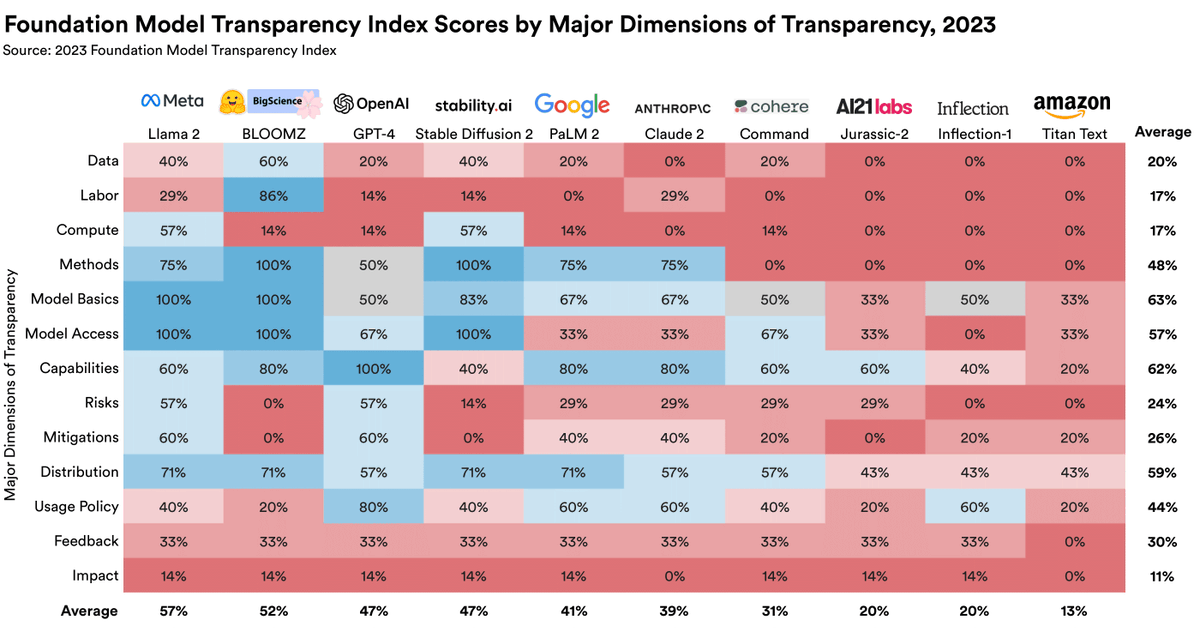
As capabilities of foundation models are waxing, *transparency* is waning. How do we quantify transparency? We introduce the Foundation Models Transparency Index (FMTI), evaluating 10 foundation model developers on 100 indicators.
https://t.co/SANOsu4bm4
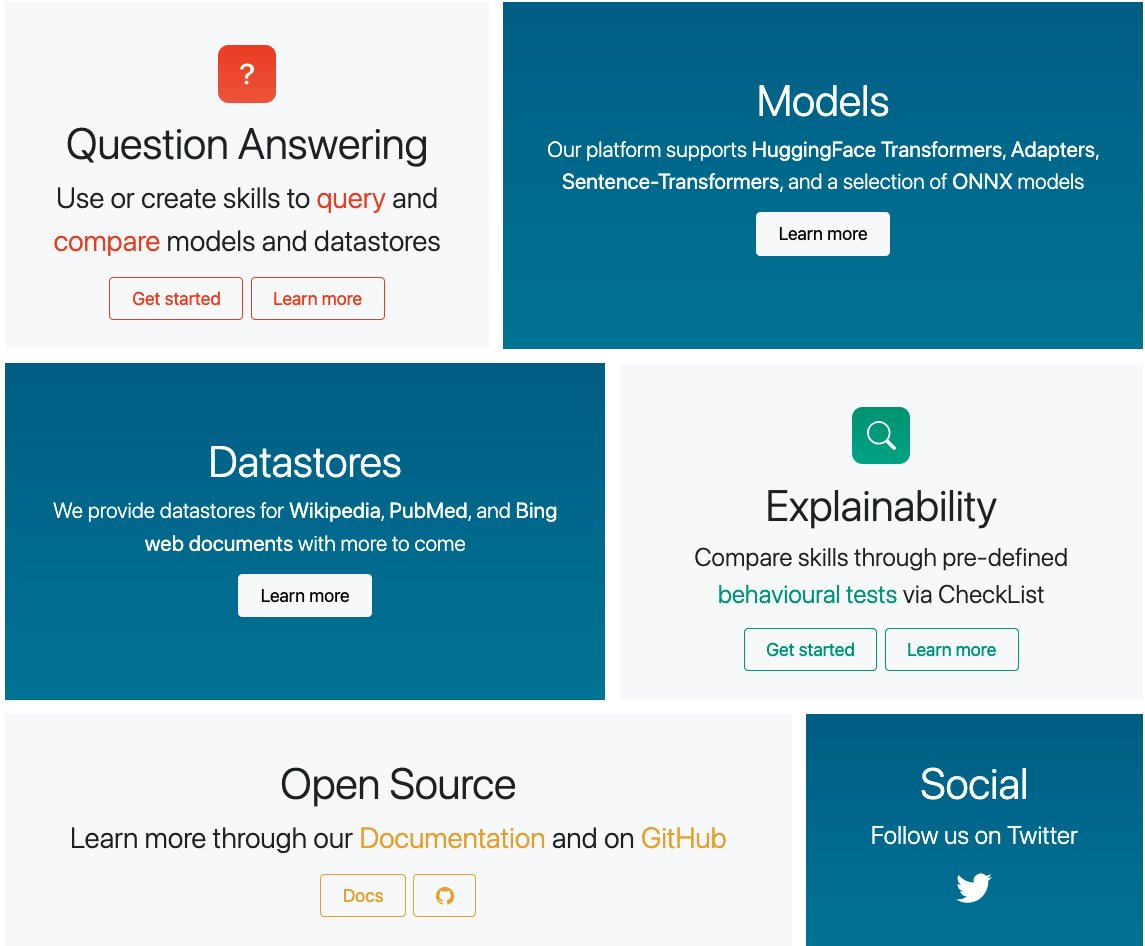
We are excited to announce the public beta of the @UKPLab SQuARE platform for Question Answering research https://t.co/8DQeXXdVli. Run, deploy, and compare QA Skills online without writing code! 🚀
Check out our ACL 2022 paper 📜 https://t.co/LGLZAlMKdC for more details!
Contrastive learning aims to learn representation such that similar samples stay close, while dissimilar ones are far apart. It can be applied to supervised / unsupervised data and has been shown to achieve good results on various tasks.
📚 A long read: https://t.co/TZiaVA0qNS
New work: "Unsupervised speech recognition"
TL;DR: it's possible for a neural network to transcribe speech into text with very strong performance, without being given any labeled data.
Paper: https://t.co/oOZK5Kehbz
Blog: https://t.co/umAqKdpQ1E
Code: https://t.co/0Ml58sPZBA
day1: i have an idea!
day2: i implemented my idea and added it to the NN and it improved 10 points!
day3: oops i had a bug and "my idea" was turned off when i achieved this gain, it was just hyper-param
how many times did this happen to you?
how many times you didn't reach day3?
🚨 New Paper !🚨
Want to measure how different groups (e.g. GOP v Dems) "understand" words differently (e.g."immigration")? check out our "Embedding Regression" paper (w @prodriguezsosa@b_m_stewart). Inference framework + software. Comments welcome! (1/4)
https://t.co/3mf2qf8IPQ
Just one week till the start of MIT's @edXOnline course on Machine Learning for Healthcare - open to the whole world and free to audit! https://t.co/hJEn7qlbGh
The ACL Anthology is looking for a (paid) assistant to help with routine operations. There will also be time during slow periods to help with the implementation of new futures and with future planning. Please share! https://t.co/z41nFKRc5V…
Happy to be giving an #ICML2020 tutorial on Bayesian Deep Learning and Probabilistic Model Construction. This area has made astounding progress in the last year. I'm grateful for the opportunity and thank the organizers for their efforts!
https://t.co/Op24fenEaH
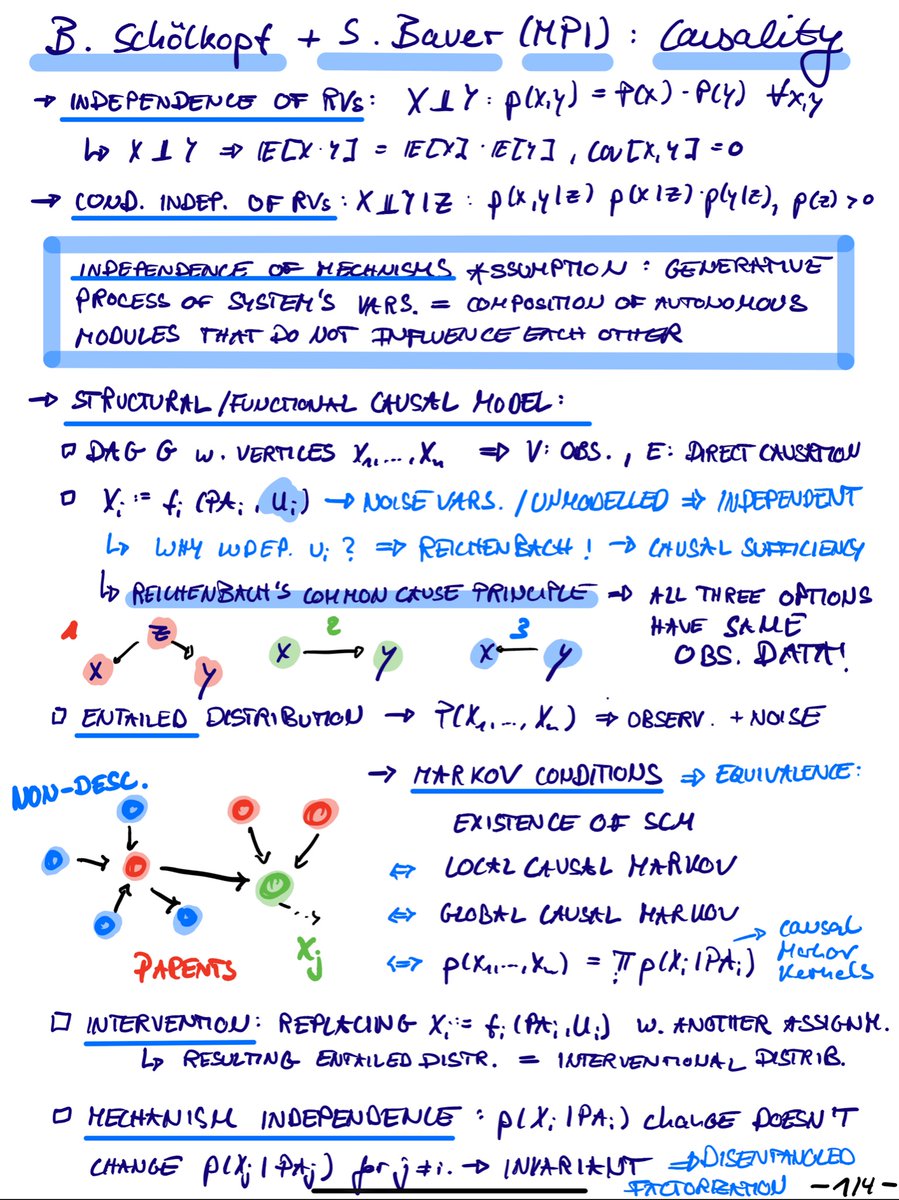
🥳Really excited to be attending #MLSS2020. Great set of talks by @bschoelkopf & Stefan Bauer starting from 101 causality to Representation Learning for Disentanglement 💯! Re-watch them here:
📺 (Part I): https://t.co/tXM5zwPV03
📺 (Part II): https://t.co/sf2S8UBEo6
Exploration strategies in deep RL are such a critical topic. I almost immediately regretted it when I started writing on this big subject because it has so much more content than I expected.
But here it comes, phew:
https://t.co/FUcmM3veog
Is there a formal definition of what it means for a language model to "know" something? E.g. which of the following scenarios counts as knowing that Paris is the capital of France?
As we near the ACL camera-ready deadline, here's a checklist that will help you make sure the paper looks nice and the repo is maintained even after you've graduated and left to pursue a professional surfing career in the Philippines. Did I miss anything?
Given the current situation, @tpilehvar and I have decided to openly release the first draft of our book “Embeddings in Natural Language Processing”. We also thank @MorganClaypool for agreeing to this early draft release.
Link: https://t.co/9PqHSw7a3H
Efficient BERT models from Google Research, now available at https://t.co/81x49Frvka!
We hope our 24 BERT models with fewer layers and/or hidden sizes will enable research in resource-constrained institutions and encourage building more compact models.
https://t.co/DU0TozBzIu
2020 edition of CMU CS11-747 "Neural Networks for NLP", is starting tomorrow! We (co-teacher @stefan_fee and 6 wonderful TAs) restructured it a bit to be more focused on "core concepts" used across a wide variety of applications. https://t.co/bNhJyLivO0 1/2
I completed my 1st data science project ~30 years ago. Since then I've been continuously developing a questionnaire I use for all new data projects, to ensure the right info is available from the start.
I'm sharing it publicly today for the first time.
https://t.co/fwUobkPvvp