@littmath "clearly the marginal impact of such work is low" - surely true with regard to scientific progress overall, but not irrelevant to how academic credit usually gets assigned, no? Or are you saying researchers are wrong to worry about "getting scooped"?
@Noahpinion That Rhodium chart showing that US tariffs "do appear to be doing something" to China's share of US imports ends in 2024. Did anything interesting happen after that?
@KeyTryer August 2024: "the AI bubble is close to bursting"
https://t.co/o9dPTLbbk2 (qualified way down in the thread by "I can't tell when the bubble bursts"; such prevaricating seems part of his modus operandi)
Newsletter: the AI bubble is close to bursting, with Big Tech losing $2 trillion in market cap as everybody wakes up to the mediocrity of generative AI. Here’s a comprehensive guide to how everything might fall apart - and how little time OpenAI has left.
https://t.co/1Kq2bo8MOZ
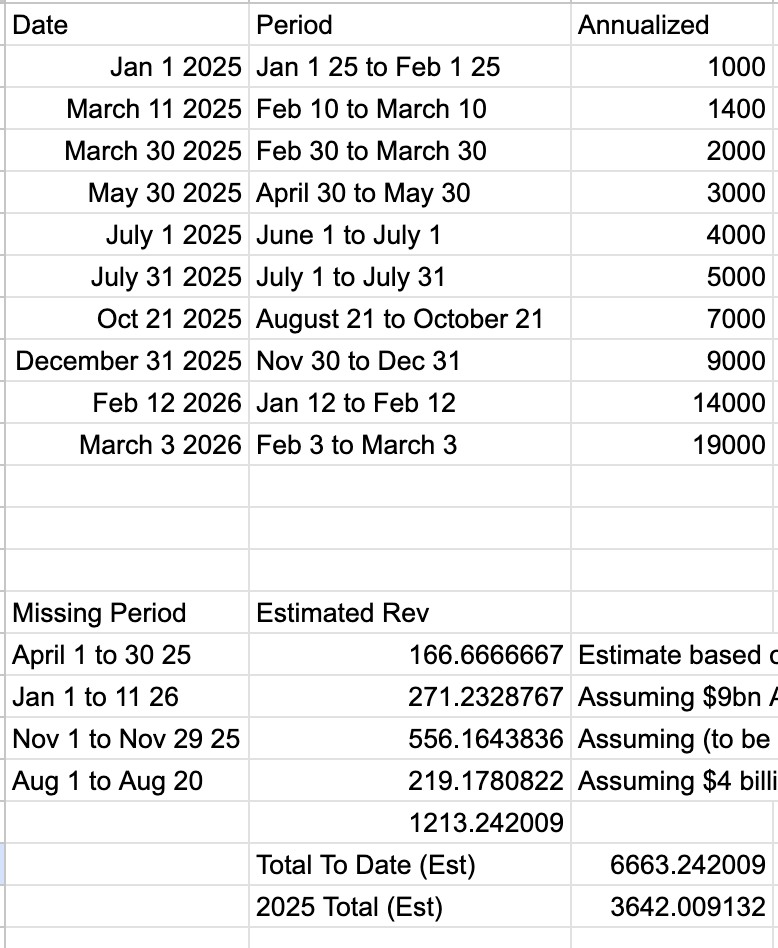
Also, check out this train wreck of a spreadsheet Ed made to estimate Anthropic's revenue for 2025. He doesn't count February 1-10, counts March 1-10 twice, counts August 21-October 21 as one month instead of two, and doesn't count October 21-November 1.
Also, check out this train wreck of a spreadsheet Ed made to estimate Anthropic's revenue for 2025. He doesn't count February 1-10, counts March 1-10 twice, counts August 21-October 21 as one month instead of two, and doesn't count October 21-November 1.
@deanwball I'm impressed! (Also, surely the clip's three characters stand for the three Rhinemaidens, and the ring must be AGI)
So what product announcement are they going to use the Götterdämmerung finale for (with the burning Valhalla)? Maybe @AISafetyMemes has ideas
@Noahpinion There's already some of the spiky stuff on Russian Hill like 2238 Hyde and 1101 Green, from pre height limit times (1928 and 1930, respectively, before the 1960s Fontana Towers controversy helped NIMBYs pull up the ladder, so to speak
https://t.co/JeAYXCtbtQ )
@jayvanbavel By that logic, books and mass media (newspapers, TV, radio) are even more "anti-social".
Yes, I'm reading your tweet here even though you and I never met in person (the horror!). But I can comment on it, or like/retweet it (increasing its likely visibility in my social graph).
@KelseyTuoc (That said, I do find it interesting and encouraging that Sanders' proposal appears to avoid using copyright law with all its problems, and seems to propose redistribution not to the very small group of copyright owners who could realistically benefit but to society as a whole.)
@KelseyTuoc Re "stolen", keep in mind that at least according to the two major US court decisions we have so far, training LLMs on copyrighted content is actually fair use: https://t.co/ED7GZVmjq6 ...
Are you confused about the fair use decisions in Anthropic and Meta cases that came out this week? Created a Table to highlight the differences and agreement. 2 big differences: (1) pirated books treatment and (2) new theory of copyright market dilution. Other parts more aligned
@quantum_geoff Presumably meant in some narrow sense, but "Computing needs can be modeled 50 years ahead" is kind of a funny sentence in 2026.
(The next page briefly gestures at "AI [as] a transformative technology that already plays a crucial role in particle physics", but nothing concrete.)
@patio11 @openwight @paulg And since you were using tabbed browsing around 1997 already, you must have been an early adopter of NetCaptor/SimulBrowse
https://t.co/3fNp2pdOev
@crane_leland@suchenzang overfitting != memorization, see e.g. this other branch of the conversation I linked earlier https://t.co/PJqIjasUUh
(PS: I'm not convinced myself that overfitting is an issue here, just wanted to clarify the debate a bit)
@kjw_chiu@alexolegimas@JohnHolbein1 But these are language models with a very different training objective, it seems? How does one even define memorization for a classification model?
Anyway, it might be interesting to study the "Open Pangram" variants that the company released recently
https://t.co/E01N7DeIbt
@crane_leland@suchenzang I mean I agree that @suchenzang seems a bit too reflexively dismissive here, but a priori it's reasonable to wonder about potential overfitting. See this recent discussion with one of the paper's authors here https://t.co/YeEkPqKpm8
@alexolegimas@JohnHolbein1 If the data are public, it could have overfit to those datapoints. Why shouldn't we be concerned about that standard problem in this case?
























![tilmanbayer's tweet photo. @quantum_geoff Presumably meant in some narrow sense, but "Computing needs can be modeled 50 years ahead" is kind of a funny sentence in 2026.
(The next page briefly gestures at "AI [as] a transformative technology that already plays a crucial role in particle physics", but nothing concrete.) https://t.co/ZpXAOxkPgD](https://pbs.twimg.com/media/HJrmI4lbMAAd9Iy.jpg)




















