We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a solid 1M-token context. GLM-5.2's new capabilities include:
Solid 1M Context: A solid 1M-token context that stably sustains long-horizon work
Advanced Coding with Flexible Effort: Stronger coding capabilities with multiple thinking effort levels to balance performance and latency
Improved Architecture: We propose IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. We also improve GLM-5.2’s MTP layer for speculative decoding, increasing the acceptance length by up to 20%
Pure Open: An MIT open-source license — no regional limits, technical access without borders
Supporting long-horizon tasks starts with making long context engineering-usable: the model must maintain quality across long, messy coding-agent trajectories, not just accept more tokens. A 1M context is easy to claim, but much harder to keep reliable under real engineering pressure. To this end, we substantially expanded 1M-context training for coding-agent scenarios, covering large-scale implementation, automated research, performance optimization, and complex debugging. The result is a long-context system that is not only wide in scope, but solid in execution: a practical substrate for sustained engineering work.
This capability is reflected in GLM-5.2's performance on three long-horizon coding benchmarks. FrontierSWE measures whether an agent can complete open-ended technical projects at the scale of hours to tens of hours, spanning systems optimization, large-scale code construction, and applied ML research. On this benchmark, GLM-5.2 trails Opus 4.8 by only 1%, while edging out GPT-5.5 by 1% and Opus 4.7 by 11%. On PostTrainBench, where each agent is given an H100 GPU and evaluated by how much it can improve small models through post-training, GLM-5.2 outperforms both Opus 4.7 and GPT-5.5, ranking second only to Opus 4.8. On SWE-Marathon, an ultra-long-horizon software engineering benchmark covering tasks such as building compilers, optimizing kernels, and developing production-grade services, GLM-5.2 still has room to grow, trailing Opus 4.8 by 13% while remaining second only to the Opus series. Across all three benchmarks, GLM-5.2 is the highest-ranked open-source model, showing that its 1M context has translated into practical long-horizon delivery capability.
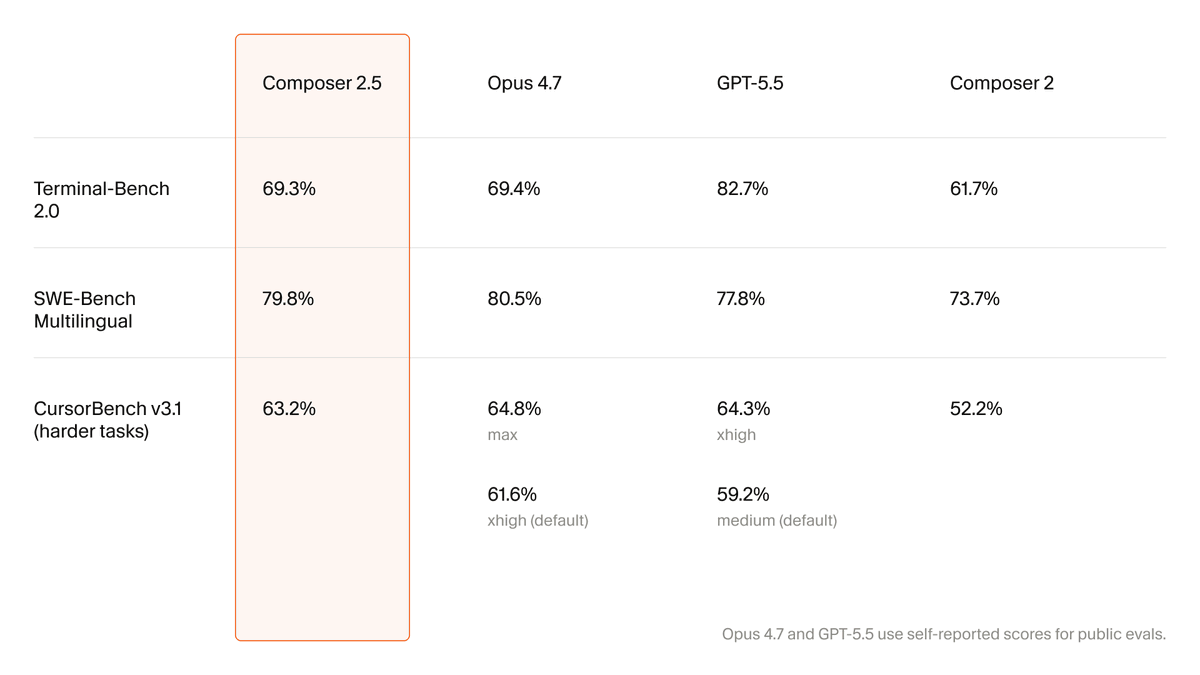
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
OpenClaw 2026.4.5 🦞
🎬 Built-in video + music generation
🧠 /dreaming is now real
🔀 Structured task progress
⚡ Better prompt-cache reuse
🌍 Control UI + Docs now speak 12 more languages
Anthropic cut us off. GPT-5.4 got better. We moved on. https://t.co/T3LaSJYOvU
You can now enable Claude to use your computer to complete tasks.
It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk.
Research preview in Claude Cowork and Claude Code, macOS only.