Scaling laws for (self) supervised learning predict:
Increase parameter count -> performance goes brrrr.
(loosely speaking)
Can we get scaling laws for Deep Reinforcement Learning?
In this work, we pave the way towards scaling laws for Deep Reinforcement Learning. We show that using Mixture of Experts is a viable path towards scaling DRL whilst improving performance.
I contributed to this paper as part of my internship @GoogleDeepMind
📢Mixtures of Experts unlock parameter scaling for deep RL!
Adding MoEs, and in particular Soft MoEs, to value-based deep RL agents results in more parameter-scalable models.
Performance keeps increasing as we increase number of experts (green line below)!
1/9
Mean Field Games provide a framework for modelling large populations.
ICML26 Spotlight: Introducing Recurrent Structural Policy Gradient for partially observable MFGs with common noise, benefitting from faster convergence than model-free RL, but remaining tractable, unlike DP.
Hindsight Experience Replay has become the ubiquitous method for goal-conditioned reinforcement learning, but leaves open the question of which goal to relabel with.
In this work, accepted at ICML, we propose instead simply Learning Everything All at Once (LEO).
1/
CV has CNNs, NLP has transformers - what inductive bias does RL have? How can policies generalise to regions of the dataset suffering from poor transitions?
We motivate hierarchy by enabling distinct state-representations at different levels of the hierarchy @FLAIR_Ox@j_foerst
Seeing a lot recently about whether info theory explains modern AI. This is *exactly* what our epiplexity paper is about. It shows how to resolve paradoxes around DPI, synthetic data, and emergence, by considering computation and structural info: https://t.co/IYNGcLCAqx
Introducing Hyperagents: an AI system that not only improves at solving tasks, but also improves how it improves itself.
The Darwin Gödel Machine (DGM) demonstrated that open-ended self-improvement is possible by iteratively generating and evaluating improved agents, yet it relies on a key assumption: that improvements in task performance (e.g., coding ability) translate into improvements in the self-improvement process itself. This alignment holds in coding, where both evaluation and modification are expressed in the same domain, but breaks down more generally. As a result, prior systems remain constrained by fixed, handcrafted meta-level procedures that do not themselves evolve.
We introduce Hyperagents – self-referential agents that can modify both their task-solving behavior and the process that generates future improvements. This enables what we call metacognitive self-modification: learning not just to perform better, but to improve at improving.
We instantiate this framework as DGM-Hyperagents (DGM-H), an extension of the DGM in which both task-solving behavior and the self-improvement procedure are editable and subject to evolution. Across diverse domains (coding, paper review, robotics reward design, and Olympiad-level math solution grading), hyperagents enable continuous performance improvements over time and outperform baselines without self-improvement or open-ended exploration, as well as prior self-improving systems (including DGM). DGM-H also improves the process by which new agents are generated (e.g. persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs.
This work was done during my internship at Meta (@AIatMeta), in collaboration with Bingchen Zhao (@BingchenZhao), Wannan Yang (@winnieyangwn), Jakob Foerster (@j_foerst), Jeff Clune (@jeffclune), Minqi Jiang (@MinqiJiang), Sam Devlin (@smdvln), and Tatiana Shavrina (@rybolos).
📣 Our recent work at Meta: Rethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks
Rubric-based judging and reward modeling are powerful for open-ended tasks, but scaling requires controlled generation, not just free-form lists from an LLM.
In case you missed it over the holidays, we @AIatMeta released: Training AI Co-Scientists using Rubric Rewards.
- RL training, we open-source the training and eval datasets!
- Human study, finding 70% win-rate
- GPT-5's lead in science? Our eval quantifies the anecdotes!
🚨New paper: Training AI Co-Scientists using Rubric Rewards
In my recent internship at Meta Superintelligence Labs, I pursued an opinionated research bet: a general, scalable training recipe to improve AI at helping scientists achieve their research goals.
Motivation
Existing work on training AI for Science optimizes pre-defined, narrow scientific objectives with execution feedback in specially constructed environments (e.g. RLVR).
However, it's infeasible to learn from trial and error in many sciences. For e.g. medical research is hard to simulate digitally, and it is unethical to run clinical trials with suboptimal approaches proposed in early training.😬
Moreover, when pursuing a novel research goal, the primary intellectual challenge often lies in defining the experiment setup and objective itself. In the past year, I have increasingly used AI assistance for this (especially GPT-5) in my own research.
Of course, models often fail to follow some explicitly stated requirements, and sometimes propose bad design choices, but that is fine! The generated plans are still useful for brainstorming, and I can implement them with further refinement.
Method
This made us wonder🤔: how can we train models to be better at this task of generating research plans, given an open-ended research goal? For training, we need to collect a large number of research goals, and obtain fast verification signals. Human experts are expensive to access, and that wouldn't scale.
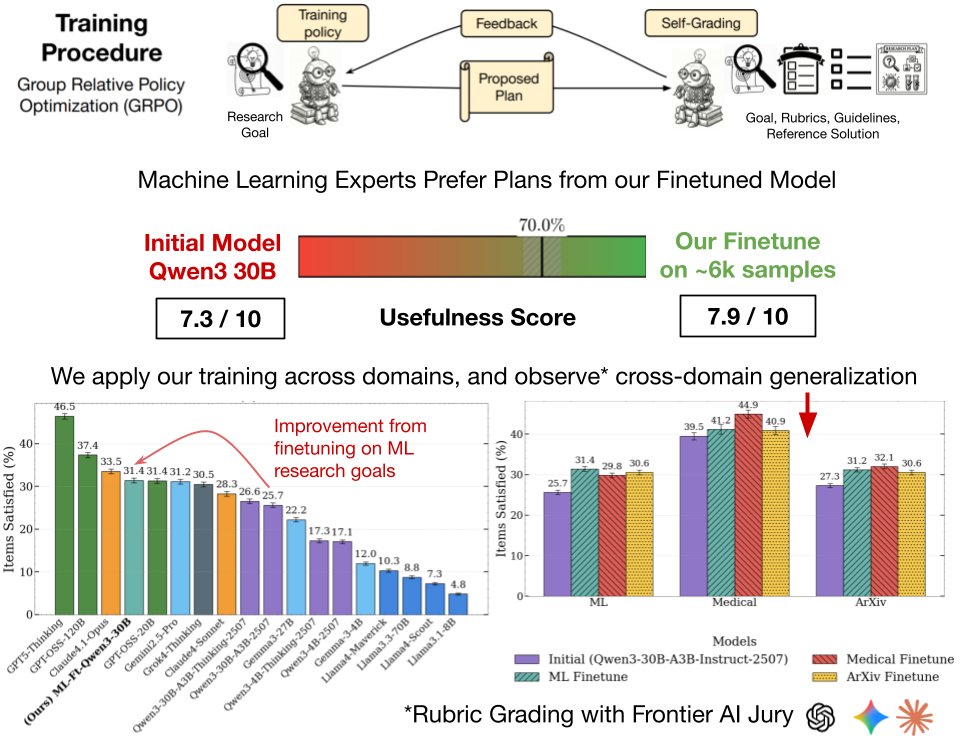
💡Equipped with the vast corpus of openly licensed scientific literature, and the recent success of RL, Synthetic Data Curation, and Rubrics, we propose a scalable recipe: Extract research goals and goal-specific grading rubrics from existing papers with an LLM, and use them for RL training.
Specifically, a frozen copy of the initial model rewards the plans generated during training using the goal-specific rubrics, checking seven general guidelines for parts of the plan relevant to each rubric item.
🤔Won't this lead to reward hacking? It will. At some point. But until then, improvements on the training reward might generalize to better research plans for humans. We are hoping the goal-specific rubrics, provided as privileged information to the grader, create a generator-verifier gap that improves research plan generation without external supervision.
The only way to find out? Perform a human study. We ask Machine Learning experts to compare plans generated by the finetuned vs initial Qwen3-30B model for ML research goals. This is slow and expensive, it required 45 minutes per annotation to carefully analyze plans, so we could only do this once at the end of the project for evaluation.
Results
Individual annotations are still noisy, as evaluating research plans is inherently subjective. But sure enough, there is non-trivial signal. The experts preferred (p < 0.01) our finetuned models plans for 70% research goals extracted from NeurIPS'24 / ICLR'25 Oral papers (top 1%) ✅
But only ML, and finetuned vs initial, is boring. Remember, the goal is generality. So we also finetuned Qwen3-30B on goals extracted from medical research, and new arXiv prerints spanning 8 domains. We use rubric evaluations with a jury of frontier models, which also allows us to compare many frontier models across domains. Notable findings:
1) In-domain finetuning leads to 12-22% relative improvements in scores across the three domains: arXiv, medical, and ML 📈
2) Significant cross-domain generalization, especially with the medical finetune improving on ML and new arXiv research goals. This might be evidence for our "generality" thesis 📊
3) Our 30B finetune matches much larger models like Grok-4-Thinking, but GPT-5-Thinking is a cut above the rest (consistent with my qualitative experience) 🤖
Limitations
Now of course, LLM-based evaluations, even with a jury and rubrics, are imperfect. But while the individual sample scoring is noisy, we hope for directionally correct results in aggregate, as the jury has positive alignment with human majority vote in our human study on ML. We think the grading scheme holds promise, as optimizing against a much weaker grader (30B), led to improvements in human preference.
This work has many such limitations, so treat it more like an early proof-of-concept. We candidly acknowledge them in our paper, and encourage you to scrutinize the details:
📜 https://t.co/eL9bjneqq9
Released Artefacts
The paper has many ablations and analyses:
- our appendix also has sample outputs across domains for vibe-checks, making it 119 pages!
- criteria-wise breakdown of performance evolution during training, thanks to our structured grading
- SFT on long-form plans worsened model performance
- training also improves Gemma, Llama models
🤗We release our train and test data on @huggingface. At a sample-level the data is noisy, and generated by Llama-4-Maverick. Still human experts approved 84% of the rubric items in ML so there's promise, and the same methodology will lead to better quality data as language models improve.
Overall, we think the potential of our approach is high: the scientific method is quite general, deep learning benefits from generality (transfer learning), and language models are amazing (better every month!). We hope approaches like this make LMs better at assisting researchers across diverse problem settings and scientific disciplines.
Some cool figures from the paper, and acknowledgements in thread🧵. I'm all ears to feedback on how we could've done things better!
1/3
🪩 So excited to reveal DiscoBench: An Open-Ended Benchmark for Algorithm Discovery! 🪩
It addresses the key issues of current evals with its broad task coverage, modular file system, meta-train/meta-test split and emphasis on open-ended tasks! 🧵
🚨🚨Introducing the FLAIR internship program!🚨🚨
We are looking for two talented students to join us for an internship working in FLAIR for 6 months (5th January to 4th July 2026)!
For details and eligibility criteria, please check: https://t.co/YsOuimzOcI
In an evolving population of models, using model merging as the crossover operation drastically reduces diversity and leads to premature convergence.
To address this, we make models compete for limited resources (training datapoints) which benefit models that have unique skills worth preserving and merging into future generations.
Additionally, we implement an "attraction" heuristic, so models with complementary strengths are more likely to pair up and merge, accelerating performance gains.
Our method evolves MNIST classifiers from scratch, achieving SOTA accuracy among evolutionary approaches at far lower computational cost. The approach scales robustly to both large language models and image diffusion models.
I had a lot of fun working on this with @yujin_tang and @RobertTLange - give it a read!
I recently had a lunch time conversation with a very senior AI researcher about how are multi-agent problems differ from single agent (their starting point was they do not).
One point that made them think: As computers scale, the rest of the world (i.e. no agentic parts) is not going to speed up or get more clever, so compute-scaling methods will succeed (think single agent robotics). In contrast, other agents will also become smarter/faster. So finding successful methods here is not a question of compute alone. No matter how much compute I have for decision making, I will be compute limited if I need to model other agents in the environment with the same budget as part of my inner loop.
As a corollary it follows that in the (long term) future almost all flops will be spend on simulating other agents. Not many know this and you are invited to consider the implications for a second.
Unlock real diversity in your LLM! 🚀
LLM outputs can be boring and repetitive. Today, we release Intent Factored Generation (IFG) to:
- Sample conceptually diverse outputs💡
- Improve performance on math and code reasoning tasks🤔
- Get more engaging conversational agents 🤖
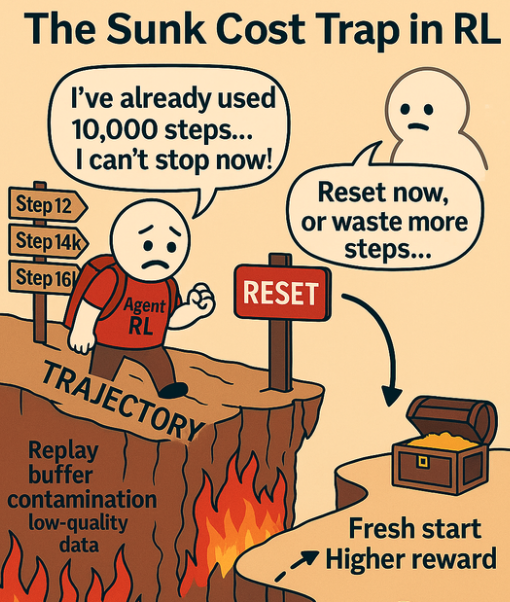
🚨 Excited to share our #ICML2025 paper: "The Courage to Stop: Overcoming Sunk Cost Fallacy in Deep RL"
We train RL agents to know when to quit, cutting wasted effort and improving efficiency with our method LEAST.
📄Paper: https://t.co/9ED3FubIPc
🧵Check the thread below👇🏾
Since 1990, we have worked on artificial curiosity & measuring „interestingness.“ Our new ICML paper uses "Prediction of Hidden Units" loss to quantify in-context computational complexity in sequence models. It can tell boring from interesting tasks and predict correct reasoning.
Antiviral therapy design is myopic 🦠🙈 optimised only for the current strain. That's why you need a different Flu vaccine every year!
Our #ICML2025 paper ADIOS proposes "shaper therapies" that steer viral evolution in our favour & remain effective. Work done @FLAIR_Ox
🧵👇
Antiviral therapy design is myopic 🦠🙈 optimised only for the current strain. That's why you need a different Flu vaccine every year!
Our #ICML2025 paper ADIOS proposes "shaper therapies" that steer viral evolution in our favour & remain effective. Work done @FLAIR_Ox
🧵👇
The AI Scientist is far from perfect. Occasionally it makes embarrassing citation errors. Here, it incorrectly attributed “an LSTM-based neural network” to Goodfellow (2016) rather than to the correct authors, Hochreiter & Schmidhuber (1997).
We documented these errors in own (human) reviews with our assessment and critiques of the AI-generated papers, listing issues we found in each paper and suggestions for improvement: https://t.co/xfFwL3yaya