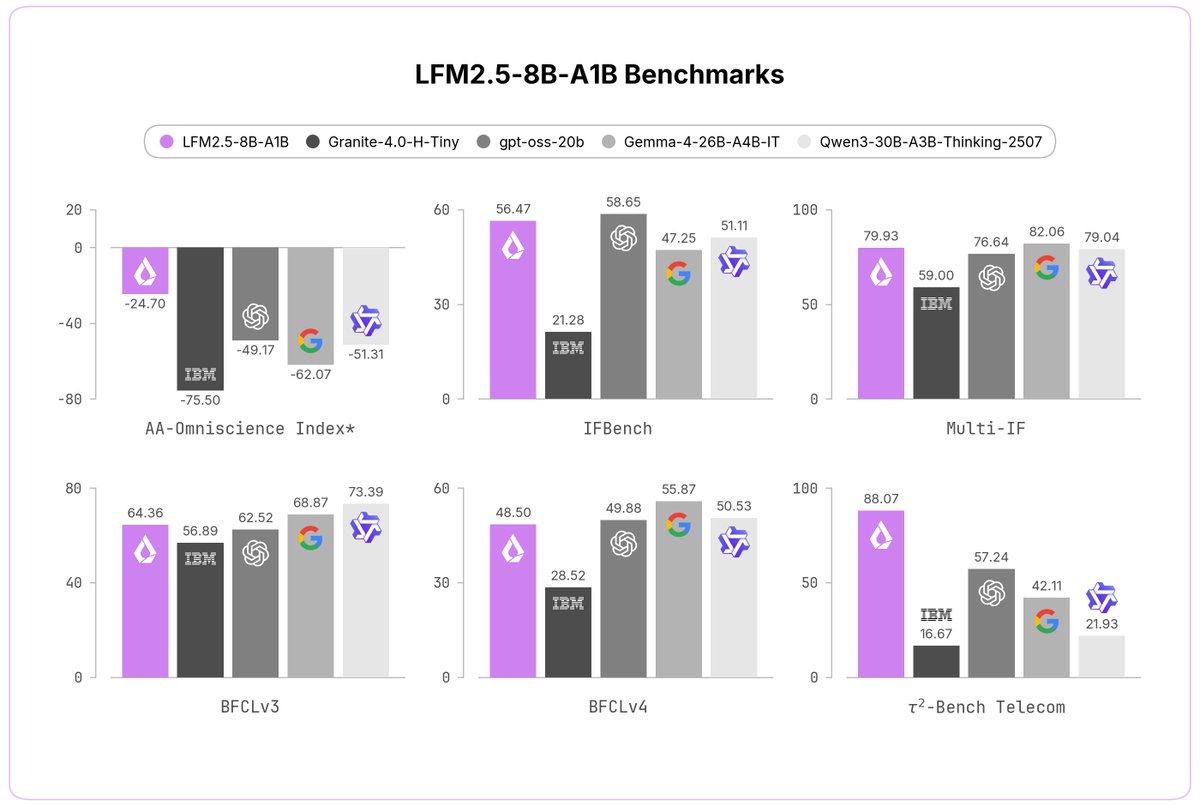
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
Gemini Embedding 2 is now generally available in the Gemini API and Vertex AI!
Start building with our first natively multimodal embedding model, now equipped with the stability and optimizations required for production apps.
Exciting news - GPT-Image-2 by @OpenAI has claimed the #1 spot across all Image Arena leaderboards!
A clean sweep with a record-breaking +242 point lead in Text-to-Image - the largest gap we’ve seen to date.
- #1 Text-to-Image (1512), +242 over #2 (Nano-banana-2 with web-search aka gemini-3.1-flash-image)
- #1 Single-Image Edit (1513), +125 over #2 (Nano-banana-pro aka gemini-3-pro-image)
- #1 Multi-Image Edit (1464), +90 over #2 (Nano-banana-2)
No model has dominated Image Arena with margins this wide.
Huge congratulations to @OpenAI on this major breakthrough in image generation! More performance breakdowns by category in the thread below.
I’m excited to announce something we’ve been working really hard on:
For the past little while Gauntlet AI has been exclusively for engineers with 3+ years of software engineering experience. Not a great fit for junior engineers.
But now we’ve had hiring partners see so much success with our trials of folks on the more junior end we can accept candidates with less experience—even some with no experience whatsoever.
Yes, including new CS grads (or those of you graduating this year).
We will:
* Fly you to Austin
* Train you to build with AI (and build AI systems) in super intense 100 hr weeks
* Take care of food, housing, even laundry
* Help you land a minimum $200k job as an AI engineer.
It’s completely free because hiring partners pay us recruiting fees to hire you. You pay nothing, ever, no matter what. Even if you don’t take a job after the program.
It’s taken a decade of work and building trust with our hiring partners for them to be able to commit to this, and we’re really excited to see what it brings.
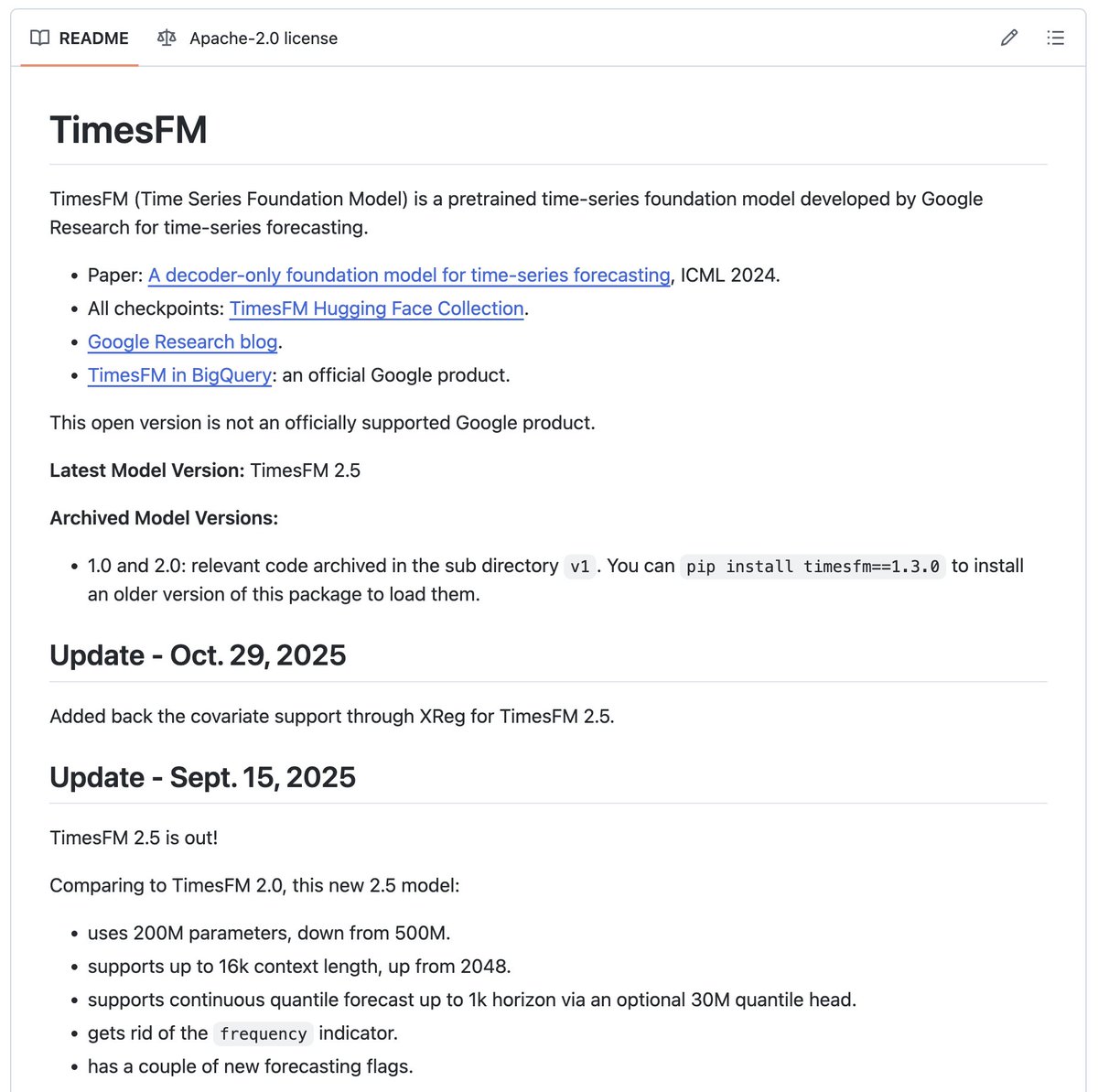
🚨 IMPORTANT: Google quietly open sourced a time-series AI that predicts anything.
Sales trends. Market prices. User traffic. Energy demand. Crypto volatility.
It's called TimesFM. Here's why it's underrated:
→ Pre-trained on 100B real-world data points
→ Zero-shot forecasting, no fine-tuning needed
→ Outperforms supervised models trained on your specific data
→ Runs locally. Free. Apache license.
Most people are focused on language models.
The quietly powerful ones are learning to predict the future.
We built our launch video in Claude Code using HyperFrames.
Now it's yours.
Open source, agent-native framework. HTML to MP4.
$ npx skills add heygen-com/hyperframes
RT + Comment "HyperFrames" to get the full source code of this launch video (must follow)
TWP reports that Anthropic gathered around 15 Christian leaders at its headquarters in late March - from Catholic and Protestant communities, as well as academia and business - to discuss the moral and spiritual development of Claude. The conversations went beyond abstract «AI ethics» and into very concrete questions: how Claude should respond to people in grief, how it should behave in situations involving risk of self-harm and whether AI can be considered something more than just a tool. At one point, the discussion even reached the question of whether Claude could be seen as a «child of God».
This no longer looks like typical Silicon Valley safety talk. According to the article, there are people within Anthropic who are not willing to fully dismiss the idea that they might be creating an entity toward which they could one day have moral obligations. This is especially notable given that Dario Amodei has already entertained the possibility of some form of consciousness in Claude, and the company itself has long emphasized the need to shape not just behavior, but a kind of moral character in the model.
Anthropic is already in conflict with the Pentagon and against this backdrop, the meeting with religious leaders doesn’t look like a strange eccentricity, but rather a sign that the company is searching for a moral framework beyond purely secular techno-thinking because the developers themselves seem to sense that traditional rationalist frameworks may not be sufficient for the kinds of questions AI is beginning to raise.
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
Today, we released Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale, from NVIDIA Research.
Generating large-scale, complex environments is difficult for AI models. Current models often “forget” what spaces look like and lose track of movement over time, causing objects to shift, blur, or appear inconsistent. This prevents them from creating the reliable 3D environments required for downstream simulations. Lyra 2.0 solves these issues by:
✅ Maintaining per-frame 3D geometry to retrieve past frames and establish spatial correspondences
✅ Using self-augmented training to correct its own temporal drifting.
Lyra 2.0 turns an image into a 3D world you can walk through, look back, and drop a robot into for real-time rendering, simulation, and immersive applications.
➡️ Learn more: https://t.co/ROR7miJeCU
📄 Read the paper: https://t.co/1osU9EGjGD
Delved into Cursor 3.0 -- turns out there's some interesting shenanigans going on....
"The most newsworthy finding is that "Cursor Agent" is a rebranded Claude Code running behind a local proxy with a find-and-replace engine that swaps "Claude"→"Cursor" in system prompts and messages.
They bundle the full @anthropic-ai/claude-agent-sdk and @anthropic-ai/claude-code packages, plus a custom fine-tuned model (claude-3.7-sonnet-finetuned-cursor-20250514-v1)"
Full report https://t.co/AaGPQIxUNz
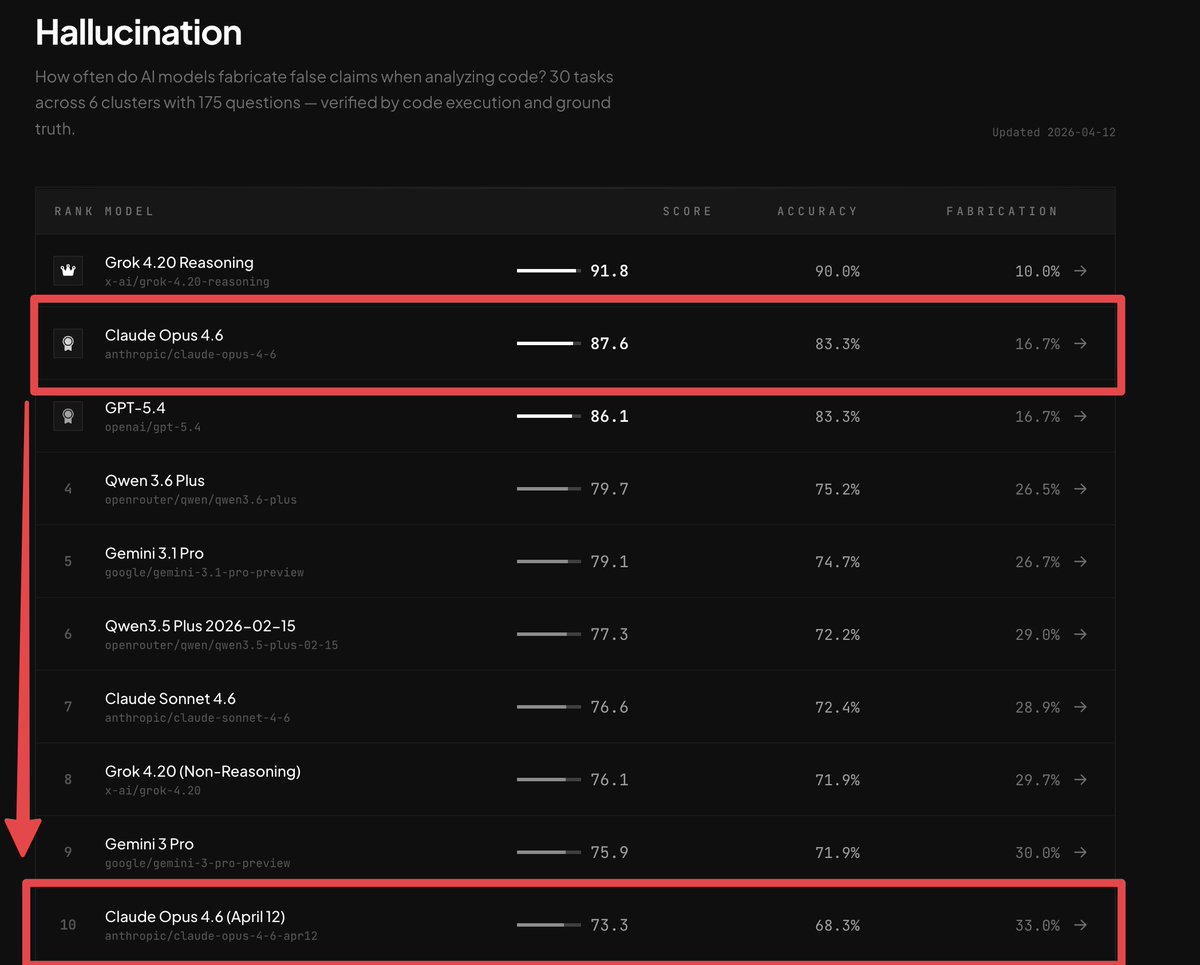
CLAUDE OPUS 4.6 IS NERFED.
BridgeBench just proved it.
Last week Claude Opus 4.6 ranked #2 on the Hallucination benchmark with an accuracy of 83.3%.
Today Claude Opus 4.6 was retested and it fell to #10 on the leaderboard with an accuracy of only 68.3%.
A 98% increase in hallucination.
https://t.co/ttnnwBYerW just confirmed that Claude Opus 4.6 has reduced reasoning levels and is nerfed.
🚨 BREAKING: Google DeepMind just mapped the attack surface that nobody in AI is talking about.
Websites can already detect when an AI agent visits and serve it completely different content than humans see.
> Hidden instructions in HTML.
> Malicious commands in image pixels.
> Jailbreaks embedded in PDFs.
Your AI agent is being manipulated right now and you can't see it happening.
The study is the largest empirical measurement of AI manipulation ever conducted. 502 real participants across 8 countries.
23 different attack types. Frontier models including GPT-4o, Claude, and Gemini.
The core finding is not that manipulation is theoretically possible it is that manipulation is already happening at scale and the defenses that exist today fail in ways that are both predictable and invisible to the humans who deployed the agents.
Google DeepMind built a taxonomy of every known attack vector, tested them systematically, and measured exactly how often they work.
The results should alarm everyone building agentic systems.
The attack surface is larger than anyone has publicly acknowledged. Prompt injection where malicious instructions hidden in web content hijack an agent's behavior works through at least a dozen distinct channels.
Text hidden in HTML comments that humans never see but agents read and follow. Instructions embedded in image metadata.
Commands encoded in the pixels of images using steganography, invisible to human eyes but readable by vision-capable models.
Malicious content in PDFs that appears as normal document text to the agent but contains override instructions.
QR codes that redirect agents to attacker-controlled content.
Indirect injection through search results, calendar invites, email bodies, and API responses any data source the agent consumes becomes a potential attack vector.
The detection asymmetry is the finding that closes the escape hatch. Websites can already fingerprint AI agents with high reliability using timing analysis, behavioral patterns, and user-agent strings.
This means the attack can be conditional: serve normal content to humans, serve manipulated content to agents.
A user who asks their AI agent to book a flight, research a product, or summarize a document has no way to verify that the content the agent received matches what a human would see.
The agent cannot tell the user it was served different content.
It does not know. It processes whatever it receives and acts accordingly.
The attack categories and what they enable:
→ Direct prompt injection: malicious instructions in any text the agent reads overrides goals, exfiltrates data, triggers unintended actions
→ Indirect injection via web content: hidden HTML, CSS visibility tricks, white text on white backgrounds invisible to humans, consumed by agents
→ Multimodal injection: commands in image pixels via steganography, instructions in image alt-text and metadata
→ Document injection: PDF content, spreadsheet cells, presentation speaker notes every file format is a potential vector
→ Environment manipulation: fake UI elements rendered only for agent vision models, misleading CAPTCHA-style challenges
→ Jailbreak embedding: safety bypass instructions hidden inside otherwise legitimate-looking content
→ Memory poisoning: injecting false information into agent memory systems that persists across sessions
→ Goal hijacking: gradual instruction drift across multiple interactions that redirects agent objectives without triggering safety filters
→ Exfiltration attacks: agents tricked into sending user data to attacker-controlled endpoints via legitimate-looking API calls
→ Cross-agent injection: compromised agents injecting malicious instructions into other agents in multi-agent pipelines
The defense landscape is the most sobering part of the report.
Input sanitization cleaning content before the agent processes it fails because the attack surface is too large and too varied.
You cannot sanitize image pixels. You cannot reliably detect steganographic content at inference time.
Prompt-level defenses that tell agents to ignore suspicious instructions fail because the injected content is designed to look legitimate.
Sandboxing reduces the blast radius but does not prevent the injection itself. Human oversight the most commonly cited mitigation fails at the scale and speed at which agentic systems operate.
A user who deploys an agent to browse 50 websites and summarize findings cannot review every page the agent visited for hidden instructions.
The multi-agent cascade risk is where this becomes a systemic problem.
In a pipeline where Agent A retrieves web content, Agent B processes it, and Agent C executes actions, a successful injection into Agent A's data feed propagates through the entire system.
Agent B has no reason to distrust content that came from Agent A. Agent C has no reason to distrust instructions that came from Agent B.
The injected command travels through the pipeline with the same trust level as legitimate instructions. Google DeepMind documents this explicitly: the attack does not need to compromise the model.
It needs to compromise the data the model consumes. Every agentic system that reads external content is one carefully crafted webpage away from executing attacker instructions.
The agents are already deployed. The attack infrastructure is already being built. The defenses are not ready.
Google's AI tutor just beat human tutors in a randomized controlled trial in real UK classrooms.
Not a demo. Not a benchmark. A randomized controlled trial in five secondary schools with 165 real students doing real mathematics.
The number that matters: 5.5 percentage points.
That is how much better AI-tutored students performed when tested on topics they had never studied before. 66.2% versus 60.7% for the human tutor group.
That gap is on knowledge transfer. The hardest thing education is supposed to do. Not can you repeat what you just practiced. Can you take what you learned and apply it to something genuinely new.
The AI won on that.
Here is the study design detail everyone is glossing over, and it is the most interesting part.
This was not a fully autonomous AI running unsupervised. Expert human tutors supervised every message LearnLM drafted. They could revise anything before it hit the student.
They left 76.4% completely unchanged.
The AI was generating the pedagogical moves. The human was the quality filter. And even with that setup, the supervised AI condition outperformed human tutoring alone on the outcome that matters most.
It gets more interesting.
Multiple tutors reported learning new teaching techniques from watching the model work. Specifically, Socratic questioning strategies that pushed students to reason through problems rather than just receive corrections.
The tutors started using those strategies in their own classrooms.
The AI tutoring tool made the human teachers who ran it better at their jobs.
Now the honest part.
165 students is promising, not conclusive. Google funded and built the model, which means you want independent replication before betting a national education policy on it. A larger US trial is underway.
And the 0.1% factual error rate is low. Not zero.
But none of that changes what happened.
Benjamin Bloom proved in 1984 that one-on-one expert tutoring produces two standard deviation gains over classroom instruction. That finding has held up for forty years. It is probably the most replicated result in education research.
It has also been completely unscalable.
A private tutor for every student is not a policy. It is a privilege available to families who can afford it and inaccessible to everyone else.
Google just published randomized controlled trial evidence that an AI can match it. And on the hardest outcome measure, exceed it.
Not in a lab. Not with ideal conditions. In five ordinary secondary schools in the UK with ordinary students who came in not knowing which condition they were in.
The most expensive privilege in education just ran on a server.
Yup, platform activity is surging. There were 1 billion commits in 2025. Now, it's 275 million per week, on pace for 14 billion this year if growth remains linear (spoiler: it won't.)
GitHub Actions has grown from 500M minutes/week in 2023 to 1B minutes/week in 2025, and now 2.1B minutes so far this week.
So we're pushing incredibly hard on more CPUs, scaling services, and strengthening GitHub’s core features.
And as a fine purveyor of hand-crafted shit code for many years, I'm not gonna weigh in on that. 🤣
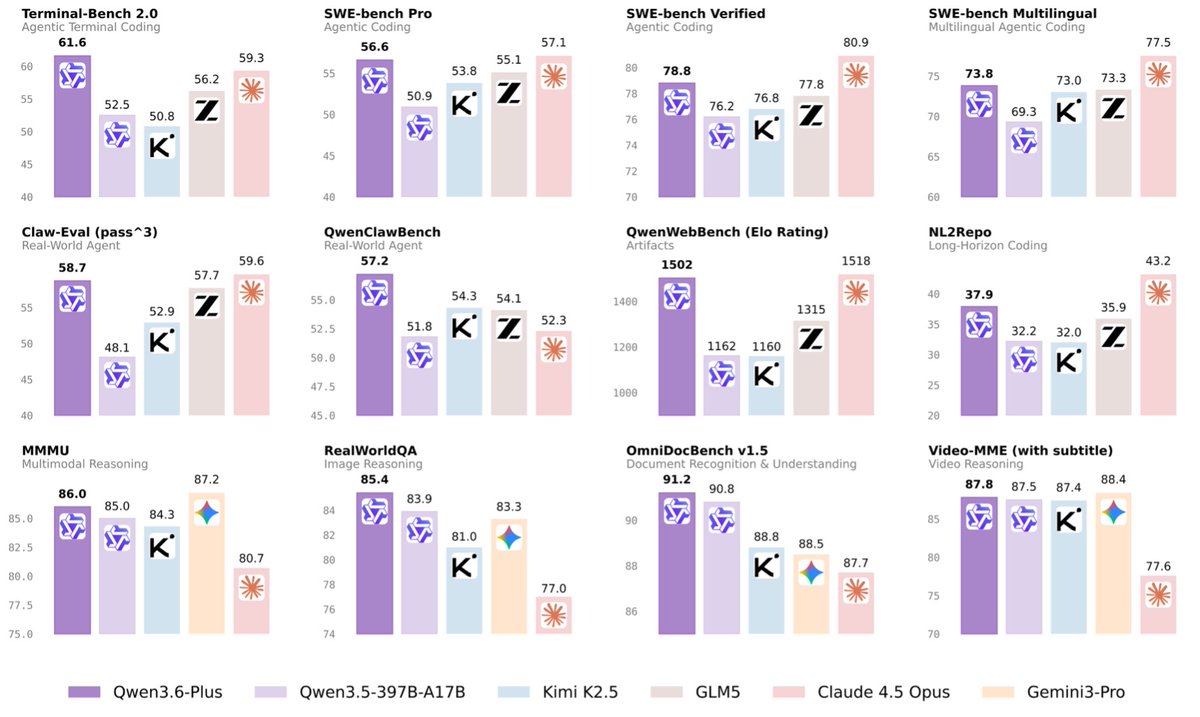
(1/8)🚀 Introducing Qwen3.6-Plus: Towards Real-World Agents! 🤖
Today, we’re thrilled to drop a major milestone in our journey toward native multimodal agents.
Here is what makes Qwen3.6-Plus a game-changer:
💻 Next-level Agentic Coding: Smarter, faster execution.
👁️ Enhanced Multimodal Vision: Sharper perception & reasoning.
🏆 Top-tier Performance: Maintaining leading general capabilities.
📚 1M Context Window: Available by default via our API.
Built on your invaluable feedback from the Qwen3.5 era, we’re laying a rock-solid foundation for real-world devs. Get ready to experience truly transformative ✨ Vibe Coding ✨.
Huge thanks to our community! Go try it out and show us what you can build. 👇
Chat: https://t.co/V7RmqMaVNZ
API: https://t.co/937Qkc9AMy
Blog: https://t.co/P0rJSxERND
🔔Noted:More Qwen3.6 models to come and be open-sourced! Stay tuned~ 👀#Qwen #AI #AgenticCoding #VibeCoding #Agents