We just released the full course materials of the Iliad Intensive — a month-long, full-time AI alignment course for mathematicians, physicists, and theoretical computer scientists.
~20 contributors, 19 modules, at a depth that doesn't exist elsewhere for most of these topics. 🧵
@atheorist We are unaware many features relevant to our decisions, especially regarding the future w.r.t AI. Unclear if many interventions are robustly better than doing nothing. Better causal models and less going with arbitrary expected value of some intervention would be good.
Benchmarks saturate quickly, but don’t translate well to real-world impact. *Something* is going up very fast, but not clear what it means. Thus the wide range of expert opinion, from “superintelligence in a few years”, to “we’ve already hit a wall”. Our results shed some light:
In this thread I want to share some thoughts about the FrontierMath benchmark, on which, according to OpenAI, some frontier models are scoring ~20%. This is benchmark consisting of difficult math problems with numerical answers. What does it measure, and what doesn't it measure?
After a long collaboration with @36zimmer, @mattecapu and @NathanielVirgo, I’m excited to share the first of (hopefully) many outputs:
“A Bayesian Interpretation of the Internal Model Principle”
https://t.co/des240w5be.
1/
@labenz We could develop and fail to control AISI, and things end up being fine for various reasons for ex:
- AI sufficiently cares about life such that it leaves humans alone while pursuing its goals
- AI wants to credibly establish its ability to cooperate with other value systems
1/ AI is accelerating. But can we ensure that AIs truly share our values and follow our goals? We argue that aligning advanced AI systems requires cracking a core scientific challenge: how data shapes AI's internal structure, and how that structure determines behavior.
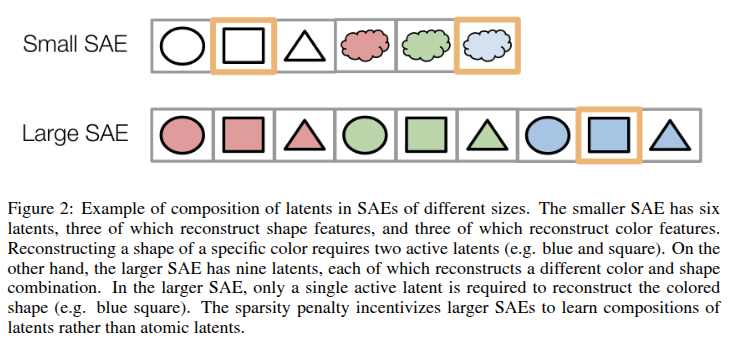
Do SAEs find the ‘true’ features in LLMs? In our ICLR paper w/ @neelnanda5 we argue no
The issue: we must choose the number of concepts learned. Small SAEs miss low-level concepts, but large SAEs miss high-level concepts - it’s sparser to compose them into low-level concepts
🌌🛰️Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
https://t.co/AxgVhVymG6
(1/9)
Our recent paper found Claude sometimes "fakes alignment"—pretending to comply with training while secretly maintaining its preferences. Could we detect this by offering Claude something (e.g. real money) if it reveals its true preferences? Here's what we found 🧵
Today, we are publishing the first-ever International AI Safety Report, backed by 30 countries and the OECD, UN, and EU.
It summarises the state of the science on AI capabilities and risks, and how to mitigate those risks. 🧵
Link to full Report: https://t.co/k9ggxL7i66
1/16
Big new review!
🟦Open Problems in Mechanistic Interpretability🟦
We bring together perspectives from ~30 top researchers to outline the current frontiers of mech interp.
It highlights the open problems that we think the field should prioritize! 🧵
New interpretability paper from Apollo Research!
🟢Attribution-based Parameter Decomposition 🟢
It's a new way to decompose neural network parameters directly into mechanistic components.
It overcomes many of the issues with SAEs! 🧵
Post-mortem after Deepseek-r1's killer open o1 replication.
We had speculated 4 different possibilities of increasing difficulty (G&C, PRM, MCTS, LtS). The answer is the best one! It's just Guess and Check.