Introducing Magenta RealTime 2, a new open model musicians can play as an instrument!
Run low-latency, live music synthesis natively on your MacBook using MIDI, text, and audio. 🎶
We love seeing Google’s open model ecosystem grow!
The new @OpenAI gpt-realtime-translate model is absolutely mind-blowing!! After playing w/ the API extensively, I can assure you that this demo was not faked or embellished in any way. https://t.co/KCJt6oKPNz
@juberti@pbbakkum@OpenAIDevs The new gpt-realtime-translate model is absolutely amazing!! Nearly everything works, but hitting some issues w/ bidirectional realtime translation in speakerphone mode. Is this a supported use case? Details here: https://t.co/QmMRFlGCDv
@SamMorrowDrums@github@moraes_c_ 1. file issue
2. get maintainer approval, denial, or “break into epic”
3. if approved, open prompt only pr
4. if that’s approved, kick off agents in a multiplayer vibe coding session with OP and maintainers.
Who pays token costs though?
@photomatt@lennysan@screenpipe Dayflow is another one you might check out. You can switch between hosted and local models depending on your privacy comfort level
This is a the future
"Littlebird is a desktop app that remembers everything you’ve been working on – meetings, messages, docs, browsing - and helps you stay focused, prioritize, recall, and move projects forward. It uses screen reading to understand all the text on screen, for all applications, and uses that context to build a rich understanding of your life: who matters to you, what you're working on, and what you care about this week and this year."
NVIDIA just removed one of the biggest friction points in Voice AI.
PersonaPlex-7B is an open-source, full-duplex conversational model.
Free, open source (MIT), with open model weights on @huggingface 🤗
Links to repo and weights in 🧵↓
The traditional ASR → LLM → TTS pipeline forces rigid turn-taking.
It’s efficient, but it never feels natural.
PersonaPlex-7B changes that.
This @nvidia model can listen and speak at the same time.
It runs directly on continuous audio tokens with a dual-stream transformer, generating text and audio in parallel instead of passing control between components.
That unlocks:
→ instant back-channel responses
→ interruptions that feel human
→ real conversational rhythm
Persona control is fully zero-shot!
If you’re building low-latency assistants or support agents, this is a big step forward 🔥
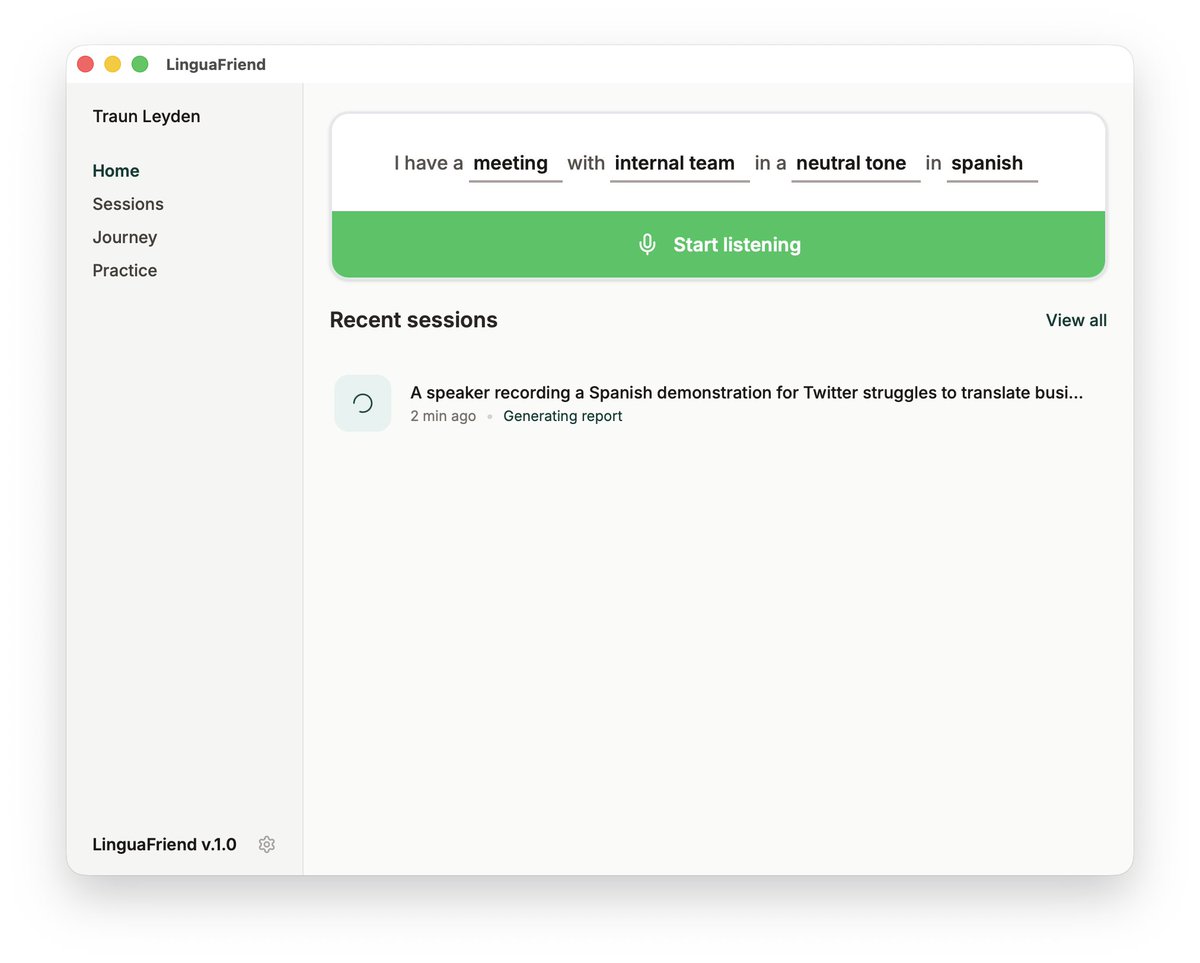
@_lhermann Building LinguaFriend: helping C1+ speakers reach native level by showing how they actually sound.
Records meetings, gives targeted reports and drills. (granola meets duolingo)
ChatGPT kind of has a built-in churn mechanism. They cut me off from using too much Deep Research this week, so now I'm checking out the Gemini Deep Research ..
I've integrated @gethuxe into my daily biking commute:
1) Queue Hacker News auto-generated podcast
2) Listen and ride, and enjoy the amazing engaging dialog
I think they use Gemini for the voices. It's very easy to listen to, and great content summary, including comments