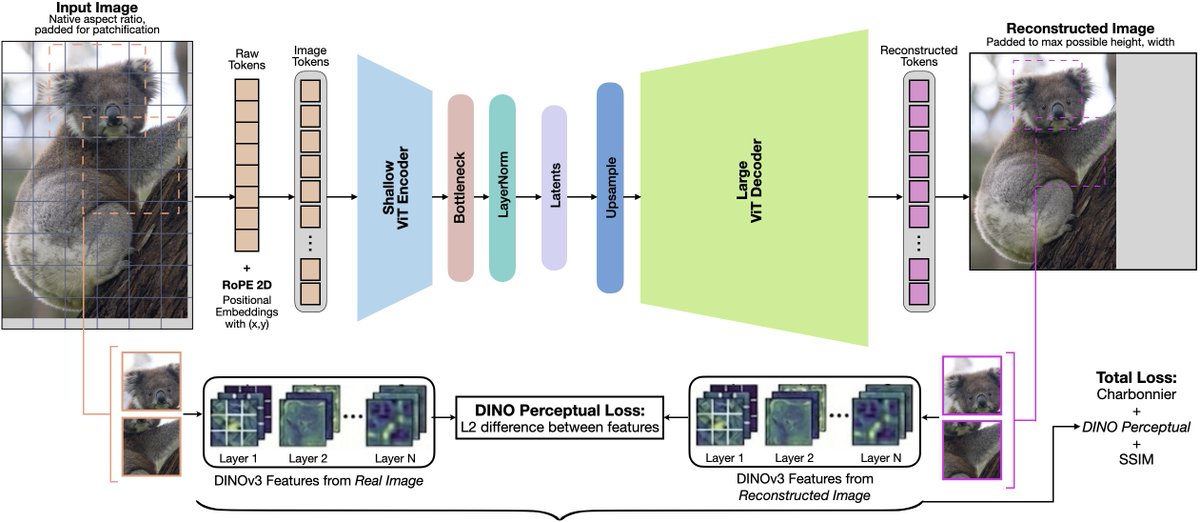
Releasing ViTok-v2: open-source ViT auto-encoder codebase + pretrained weights
Train your own ViT auto-encoder on any streamed (hf://) or local webdataset. NaFlex pipeline handles any resolution and aspect ratio
Includes reproduced 350M and 4.5B models weights competitive at 256p, SOTA at high-res (512p+)
@fl0ct0 Honestly if you can autoresearch well then that's a win for everyone. Only a problem when people think autoresearch is sufficient, or it gives them illusion of productivity because they're using a lot tokens but not achieving much
It's also a miss to describe Agent-1 as a uniform 50% research multiplier? It really speeds you up a lot on the sort of side tasks but the hard core loop really hasn't sped up that much. ChatGPT 5.5 is nice but ... not 50% probably?
Very depressed today because of other reasons.
Money does not buy happiness. I assure you it does not.
Every year I have vacation with old college friends. Always richest. Always most unhappy.
Amusingly this year my wealth > all them combined.
Its just money. It's made up.
@TexasOncologist@CamaradeRea@Rebecca98869736 imo avgo just showed the move in semis was too fast. Def more buyable and im plenty bullish, but Jesus the movement was crazy from March 30th
For the past years my research focus was on unifying models and training paradigms across modalities. Today I'm excited that we're releasing our latest model aligned with this theme:
Gemma 4 12B, a dense encoder-free model which processes raw text, image, and audio inputs!
1/