@GoodAtBingo@hausfath No, but you can correctly accuse them of cherry-picking the trend line, the point comparisons, and the series with the smallest trend and biggest record of errors.
@ChrisMehl7@TheDemocrats@GOP There's kind of a false balance here. Fixing both is good, but Trump's buddies stole more from markets via insider trading on tariff Liberation Day than the Minnesota frauds stole ever. The current admin's corruption of all kinds is unprecedented.
@BruceSkarin@BernieSanders Tinbergen's rule: you need one independent instrument per policy target. Carbon taxes will fix carbon, but I think it's unlikely you can fix wealth distribution via the same mechanism.
@BruceSkarin@BernieSanders OTOH if you don't raise the top marginal tax rate somehow, the federal debt is going to sink the economy anyway. Also, oligarchs aren't necessarily golden geese - many have switched from value-creation mode to value-appropriation mode. The real golden geese are further down.
I keep trying to explain to people, but America doesn’t have a viable 3D printer company because we don’t have any of the underlying architecture.
Shocking how many people think a complex product is some singular thing you build at a “factory.”
A 3D printer is really just a featherweight CNC mill, so much so that they speak yeh same language (G-Code). You need:
- micron accurate linear rails
- Sub micron bearings for those linear rails.
- High resolution servo/stepper motors.
- Motion control chips and boards and stuff.
- Sheet metal, injection molding, various coatings.
America has *no* industrial base for *any* of this at consumer product scale. We invented or definitively innovated everything above, then the McKinsey set came in and convinced us to ship it all to China for the last 40 years.
So yea, sure… you can screw a 3D printer together in America, at great expense… but you are doing so with primarily Chinese components.
What we need is a bunch of uninvestible (by venture funds) businesses that are boring and competently supply a bunch of even more boring, medium margin, no-moat components.
@akwellerfiction@KellyKortum "Won't subvert." It's also not as simple as the mechanics in Article IV.3 - they aren't the only applicable portion of the constitution. Other features like the Declaration of Rights matter too.
@akwellerfiction@KellyKortum Also, if you read the article, you'd know that this was not the MT Supreme Court; it was a district court. Also, it's not a final ruling, it's a preliminary injunction.
Physics-based weather models still beat AI when it matters most. Not on average. On the most extreme days.
This is the opposite of what we've been hearing...
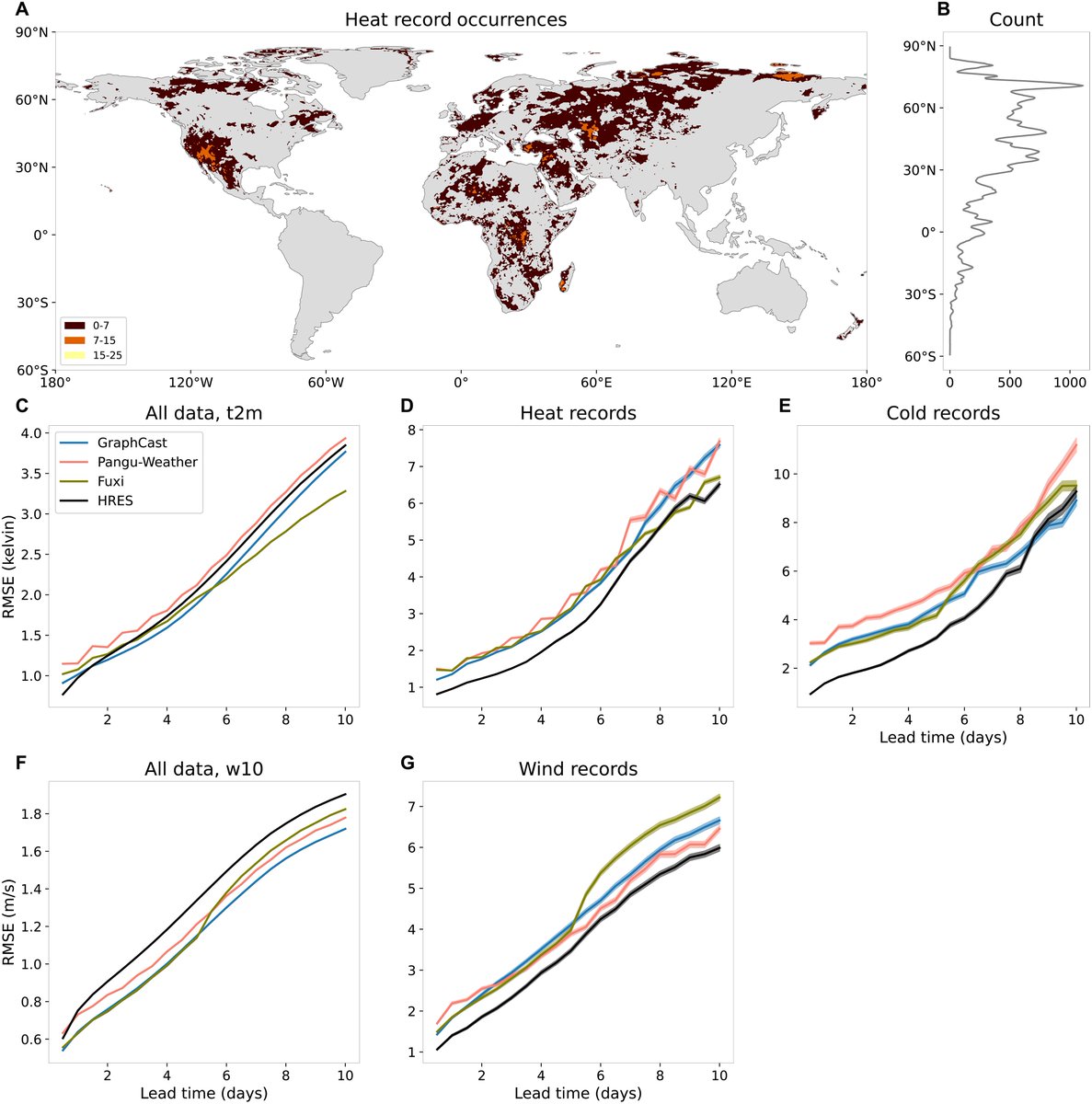
A new paper in Science Advances ran every major AI weather model: GraphCast, Pangu-Weather, Fuxi, against ECMWF's HRES across 162,751 record-breaking heat events, 32,991 cold records, and 53,345 wind records in 2020.
On average conditions, the AI models win. GraphCast, Fuxi, and the rest outperform HRES on standard temperature and wind benchmarks across most lead times. This matches what every prior benchmark study has shown. AI weather forecasting is genuinely impressive.
Then the researchers asked a different question. What happens when the event is unprecedented? Not extreme. Not the 95th percentile. Actually beyond anything in the training data.
HRES won every single category. Heat records. Cold records. Wind records. Nearly every lead time. The performance gap was largest at short lead times, where AI models should have the most information and the least uncertainty.
The bias pattern is pretty massive. The AI models systematically underestimated how extreme the events were. The bigger the record exceedance, the larger the underprediction. The researchers describe it as an implicit 'soft cap': the models behave as if they can't forecast values much beyond the most extreme thing in their training data. The bias grows almost linearly with how far the event exceeded the record. HRES showed no such pattern.
This isn't a fluke. The same result held in 2018 and 2020, which had opposite ENSO conditions. It held across the tropics, subtropics, mid-latitudes, and high latitudes. It held for all three variables. It held when the researchers ran an alternative evaluation specifically designed to avoid the forecaster's dilemma.
The mechanism is pretty straightforward. AI weather models are trained on ERA5 reanalysis data from 1979 to 2017. They learn to interpolate between historical weather patterns. When a new initial condition arrives, they find the nearest analogues in training and produce something in between. Record-breaking events, by definition, have no close analogues. The model has never seen anything quite like this, so it regresses toward the most extreme things it has.
Physics-based models like HRES don't work this way. They solve partial differential equations describing atmospheric dynamics. They don't need a historical analogue for a 48°C heatwave in Siberia. The physics doesn't care whether it's happened before.
The authors are careful about what this means. AI models remain faster, cheaper, and competitive on average conditions. Probabilistic AI forecasting is developing rapidly. Data augmentation with simulated extreme events and hybrid physics-AI architectures are plausible paths forward. This isn't a verdict on AI weather forecasting broadly.
But the policy implication is quite important. The events where AI models fail hardest are exactly the events where accurate forecasting matters most. Record-shattering heat. Unprecedented wind storms. The scenarios that overwhelm emergency response, strain infrastructure, and kill people because no one expected them to be that bad.
The authors wrote it plainly: it remains vital to fund and run physics-based NWP and AI weather models in parallel. I find it an unusually direct recommendation in a methods paper.
Climate change means record-breaking events are becoming more frequent, not less. The training distribution is shifting. AI models trained on 1979 to 2017 data will see more and more out-of-distribution events as the climate diverges from that baseline. The extrapolation problem the researchers identified isn't going away. It's getting harder.
The models that can't forecast records are being asked to forecast a world that's setting them constantly.
Link to full paper: https://t.co/KYvUreAhgt
LLMs work best where they can be verified easily - that's why vibe coding is productive. If you use it to get a logical algorithm (say, sorting) it's easy to write unit tests and verify the result, and the agent can write its own tests and iterate to get it right.
Terence Tao is answering a fundamental question regarding the safety and reliability of modern AI: "How can we use a tool that is powerful, but unreliable?"
W = ∑(wᵢ ⋅ xᵢ) + b
AI isn’t just about “smart”; it’s about the probability of *looking* right. We’ve built systems where the weights (wᵢ) are optimized for plausibility, not veracity.
This creates a “convincing mirror” that confidently serves dangerous advice in medicine or finance. The gap between “convincing” and “correct” is the most critical variable we need to solve for.
If the problem is unstructured, data-poor, or difficult to test, the self-correction loop doesn't exist and a model is able to foist off plausible BS delivered with confidence as a real solution.
If we build #systemdynamics models with LLMs, the importance of testing increases, because our problems are ill-structured and data-sparse. Model specification, Reality Check® (@Vensim), calibration and manual experimentation will take up a bigger fraction of modeler time.