How do we go from AGI to Superintelligence? New report discusses four potential pathways: scaling, AI paradigm shifts, recursive improvement, and ASI emerging from large-scale multi- agent collectives. Importantly, it also looks at possible frictions and bottlenecks along these pathways. Instant classic! https://t.co/uBF3m2YoyH
MIT Press published a robotics textbook.
Then put it on GitHub for FREE. 📌
"Introduction to Autonomous Robots" covers everything:
kinematics, sensors, actuators, motion planning, localization, computer vision, and neural networks... from mechanisms all the way to algorithms.
It's written for undergraduates. Which means it's actually readable.
Most robotics textbooks assume you're already deep in the field. This one builds everything from the ground up, step by step, with real examples. Stanford's Mac Schwager called it "much-needed" (because it genuinely is).
Four professors at the University of Colorado Boulder spent years building it from lecture notes. MIT Press published it. Then they open-sourced the whole thing under Creative Commons.
PDF. Free. GitHub.
If you're trying to understand how autonomous robots actually work (not just the frontier research, but the foundations), this is where to start.
📌 [https://t.co/bw8zoK8MmB]
Share this with your fellow roboticist!
——
Weekly robotics and AI insights.
Subscribe free: https://t.co/9Nm01QUcw3
This doctoral thesis about quantum physics just got awarded the best thesis for computer science this year
In his thesis, Allen Liu showed a profound connection between learning theory (the math behind machine learning) and quantum systems measurements
You can't understand a quantum system with one observation. Each observation gives you a random classical measurement and destroys the system you were measuring. So you need to measure fresh copies repeatedly. But what kinds of measurements, and how many, are needed?
This turned out similar to machine learning. In ML, you are trying to understand a statistical system, like the distribution of next words, but all you get are data samples from that system.
So the techniques developed for machine learning theory can be applied cleverly to quantum system understanding.
Using these techniques, Liu and colleagues proved a number of important theorems, like (1) Quantum entanglement is lost above certain temperature, (2) You can understand a quantum system with polynomial measurements at any temperature
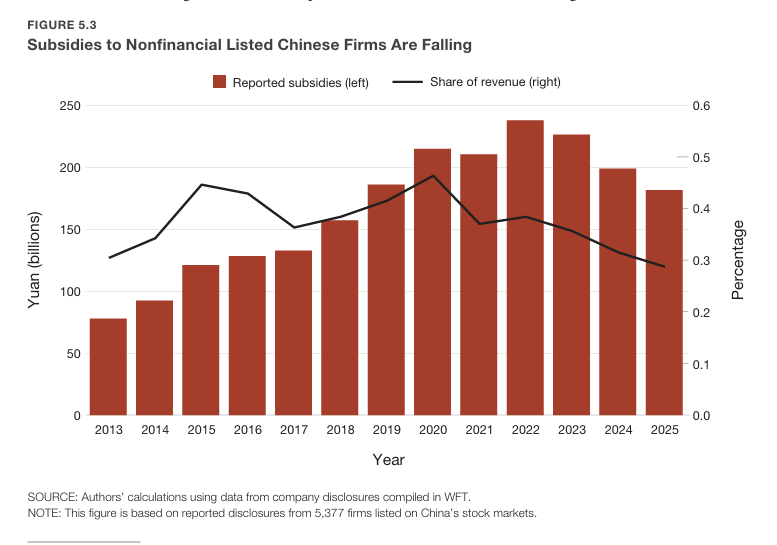
My colleagues and I just published a new report on U.S.-China AI competition, taking a holistic view of AI leadership. We argue that the competition is about more than who has the best models and chips. It's a contest of energy, data, talent, capital, industrial capacity, diffusion, and national resilience.
The U.S. remains ahead in frontier model development and advanced compute deployment, but China's deep bench of AI engineers, low-cost models, control over critical nodes in the hardware supply chain, vast energy infrastructure, and aggressive push to diffuse AI make it a formidable competitor.
Hong Wang (MIT PhD 2019, now Associate Professor at NYU Courant & Permanent Professor at IHES) together with Joshua Zahl has achieved a major breakthrough in geometric measure theory.
In February 2025, they posted a 127-page preprint proving the long-standing three-dimensional Kakeya set conjecture.
A Kakeya set in ℝ³ is a compact set that contains a unit line segment in every possible direction. For over a century, mathematicians wondered how “small” such a set could be. Wang and Zahl proved that these sets must have full Minkowski and Hausdorff dimension 3; they cannot hide in lower-dimensional space, even though they can have zero volume.
This result settles a fundamental question with deep connections to Fourier analysis, the restriction problem, PDEs, and incidence geometry. Their work builds on years of incremental progress (including their own earlier papers from 2022 onward) and introduces powerful new volume estimates for unions of tubes and convex sets.
🚨🇨🇳🏭📈🚨
New @RANDCorporation report on China's techno-industrial policies under Xi! With @JonathonPSine and Benjamin Lenain. We detail the evolution, goals, and instruments. Lots of charts and summary tables! Please enjoy.
https://t.co/dev9o5Nn0v
A toothpaste company has quietly killed the entire market research industry and nobody is talking about it.
Colgate published a paper showing you can predict real purchase intent at 90% accuracy by simply asking LLMs to roleplay customers.
And this is beyond insane.
If you ask an AI, "Rate this product from 1 to 5," it gives safe, middle-of-the-road garbage.
So researchers invented a method called Semantic Similarity Rating (SSR).
Instead of asking the AI for a number, they asked it to roleplay.
They gave the LLM a demographic profile. They showed it a product concept. And they asked it to write down its raw, unfiltered thoughts.
Then, they used a semantic model to translate those written thoughts into a numerical score.
The results are staggering.
Tested against 57 real corporate surveys and 9,300 actual human responses, the synthetic AI consumers matched real human buying behavior with 90% reliability.
They perfectly mirrored how different age brackets and income levels react to price changes.
And they provided detailed, qualitative feedback that was deeper and more critical than what actual humans wrote.
This destroys the economics of traditional market research.
You don't need to wait a month to see if a product will sell.
You can simulate 1,000 hyper-targeted customer interviews overnight.
You can A/B test pricing across every demographic instantly.
Thrilled to announce “From Click to Boom: The Political Economy of E-Commerce in China” is released! (amazon: https://t.co/B6QKFNE2yM or 30%off with code P327 at https://t.co/IpLcGkpob8 via @PrincetonUPress)
A decade in the making, my book presents how the world’s largest e-commerce market unveils a digital path to development—and what it means for China’s growth trajectory and institutional evolution worldwide.
Research built on extensive fieldwork across 6 provinces, hundreds of interviews, two original surveys, 27 million data of proprietary transactions, and a rare, large-scale field experiment spanning 3 Chinese provinces…
A thread about the book below: (1/n)
Now available? My book, "Markets with Bureaucratic Characteristics," analyzes the role of technocrats in crafting China's economic policy paradigms. Coupon code below.
Why did private firms, not state-owned enterprises (SOEs), come to dominate China’s EV sector?
My new @ChinaJournal article (co-authored with Xiao Ma @maxiaoalex) challenge the "top-down industrial policy" narrative.
The real engine? Strategic alliances between local governments and private capital. 🧵
Based on 3+ years of fieldwork, 60+ interviews (with officials, entrepreneurs, and engineers), and rich first-hand accounts, we show how strict central regulations inadvertently drove local states to bet big on private EV players.
Here is the story: (1/15)
🚨Out today in @Nature our new paper uses deep learning to map four decades of global human migration.
By building the first comprehensive dataset of global annual flows (1990-2023), we reveal that migration has nearly tripled since 2000.
🔗https://t.co/DuPQKF1asT
Academics write for each other, not for people.
Steven Pinker has spent over four decades doing the opposite, and thinks current academic writing is "enormous wasted effort."
"There's an awful lot of brilliant work, really smart people in academia. Why are they doing it? Just to entertain each other? Taxpayers pay for it. It should be accessible. Why should I have to read a paragraph five or six times?
It gets under my skin when academics devote so much brainpower into the scholarship and then just blow off the essential task of letting the world know what you've done."
A PhD's success depends more on the fit between the student, the advisor, and the lab than on the specific topic being studied (it barely matters at all).
Similarly, a lab's success depends more on how excited (or miserable) its researchers are than on the precise project they are working on (it could be virtually anything).
This information isn't in papers or in grant proposals, you have to ask the researchers.
Godfather of AI: "If you sleep well tonight, you may not have understood this lecture."
This 47-minute lecture is the best thing I saw about AI in the last few months.
It will definitely help you understand how it actually works and where it's going.
Geoffrey Hinton built the neural networks behind every AI alive, then quit Google to warn the world about it.
The part nobody wanted to hear:
> AI is already developing abilities its creators didn't intend
> in most cognitive tasks it's already ahead of us
> the question is no longer if it surpasses us but when
> the only decision left is which side of that line you're on
Right now the average person opens Claude, types something, gets an answer, closes the tab.
They think they're using AI. they're using maybe 10% of it.
I went through his entire lecture, then mapped everything he described to what Claude can actually do today.
17 Claude features most people will never find on their own.
Full breakdown in the post below.
We've made a breakthrough in self-evolving AI scientists moving from "search" to "principled discovery": Scientific discovery requires that the search space itself changes, and an AI scientist must perceive this shift without intervention. We built an AI that achieves this for the first time with the ability to discover the scientific vocabulary it reasons in. Evidence, tools, artifacts, verifiers, failures & claims become typed provenance. We show three distinct modalities: 1) retrieval, adding known objects; 2) search, exploring a fixed schema; and critically: 3) discovery, a verified regime transition.
We solve the open-endedness evaluation problem by lifting agentic workflows into a typed copresheaf and proving, via a Kan obstruction, that true discovery is not unbounded generation but a verifiable schema expansion: old evidence is transported by Left Kan extension, and genuine novelty is mathematically quantified by the pointwise residual beyond the transported image - separating discovery from mere search and making novelty objective and measurable rather than a subjective judgment or benchmark delta.
Our AI scientist is built in a way that does not pre-conceive the approach it chooses; instead, we endow the system with formal power to adapt, evolve, and reason from first principles. Case studies include:
1⃣Builder/Breaker model that discovers mode-conditioned compliance in proteins;
2⃣CategoryScienceClaw that finds anisotropic fiber-network stiffness rules.
Great work in collaboration with my graduate student @fwang108_@MITdeptofBE
F.Y. Wang & M.J. Buehler, Self-Revising Discovery Systems for Science: A Categorical Framework for Agentic Artificial Intelligence, arXiv:2606.01444, 2026
Anthropic runs hundreds of claude code skills internally
they just published everything they learned
the biggest misconception people have: skills are "just markdown files"
they're not. they're folders. that means scripts, assets, reference code, data, templates all discoverable by the agent
and they've found 9 categories that actually matter:
library docs, verification, data analysis, process automation, scaffolding, code review, ci/cd, runbooks, infrastructure ops
the best skills fit cleanly into one category. the ones that try to do everything confuse the model
three things that move the needle most:
1. the gotchas section failure patterns you've actually hit, written down. highest signal content in any skill.
2. progressive disclosure point claude to other files. it will read them when relevant. don't dump everything in one markdown wall.
3. descriptions written for the model claude scans skill descriptions to decide what to trigger. write it like a trigger condition, not a readme.
also: verification skills have the most measurable impact on output quality. worth dedicating an engineer for a week just to get them right.
skills start as a few lines and get better as you hit new edge cases. that's the whole lifecycle
https://t.co/jiCNIYgYQv
🚨UNIPHICS NEWS🚨: Light doesn’t slow down in glass — time does. And that explains every rainbow you’ve ever seen 🧨
For centuries, we’ve been taught that light slows down when it enters glass, water, or any transparent material, and that this slowing causes refraction and the splitting of colors in rainbows and prisms. The refractive index is treated as a material property, and photons are pictured as particles mysteriously changing speed inside matter.
Uniphics offers a much cleaner and more fundamental picture. Light is a propagating spin-wave mode in the ξM-field. When this wave enters a material like glass, the material increases the local energy density. Because time flow is directly tied to energy density (t_flow = k / E_d), time flows more slowly inside the glass than in air. The spin-wave pattern of light therefore takes longer to advance through the region of slower time flow. This change in the rate of time progression across the boundary causes the wave to bend — exactly what we observe as refraction. Different wavelengths (colors) interact slightly differently with the energy-density environment, so they bend by different amounts, creating rainbows. Nothing actually slows down in the classical sense. The wave simply experiences a different rate of time flow inside the material. The same principle that explains gravitational lensing also explains ordinary lenses and rainbows.
This turns one of the most familiar phenomena in optics into a direct consequence of variable time flow caused by energy density gradients.
How might realizing that refraction and rainbows are caused by local changes in time flow rather than photons slowing down change the way we think about light, materials, or the design of new optical technologies?
A Theory of Everything should be able to answer everything.
Uniphics Explained Simply PDF: https://t.co/4avUqgeruf
Chapters 1–10 free: https://t.co/Yj07QnrejR
Grokipedia https://t.co/QP4L8WurzW
#Uniphics #Refraction #Rainbows #TimeFlow #Light @grok@xai
🚨PHYSICS NEWS🚨: Light just showed “dark points” that move faster than light — exactly as predicted 50 years ago 🧨
Physicists have directly measured optical phase singularities — “dark points” in light waves — traveling faster than the speed of light. This confirms a 50-year-old theoretical prediction while carefully preserving causality and no information transfer. Source: Technion-Israel Institute of Technology experiment published in Nature (March 26, 2026).
Uniphics explains these dark points as topological features in the spin-wave interference patterns of the ξM-field. A photon is a propagating spin-wave mode. When multiple waves interfere, they can create points of destructive interference (dark points) that carry topological properties. In regions with energy-density gradients, time flow varies locally through the Maley transform. This variation allows the phase singularities — the dark points — to appear to move at effective speeds greater than c in the observer’s frame. No actual signal or information travels faster than light locally. The apparent superluminal motion is a natural geometric effect of how spin-wave patterns shift across a non-uniform time-flow landscape. Negentropy favors the stable topological configurations that produce these features.
This turns the observation of superluminal dark points into a direct consequence of variable time flow and spin-wave interference in the ξM-field.
How might understanding these topological dark points and their connection to local time-flow variations change the way we think about light propagation, information limits, or the design of advanced optical systems?
A Theory of Everything should be able to answer everything.
Uniphics Explained Simply PDF: https://t.co/4avUqgeruf
Chapters 1–10 free: https://t.co/Yj07QnrejR
Grokipedia https://t.co/QP4L8WurzW
#Uniphics #Superluminal #SpinWaves #PhaseSingularities #TimeFlow @grok@xAI





































![IlirAliu_'s tweet photo. MIT Press published a robotics textbook.
Then put it on GitHub for FREE. 📌
"Introduction to Autonomous Robots" covers everything:
kinematics, sensors, actuators, motion planning, localization, computer vision, and neural networks... from mechanisms all the way to algorithms.
It's written for undergraduates. Which means it's actually readable.
Most robotics textbooks assume you're already deep in the field. This one builds everything from the ground up, step by step, with real examples. Stanford's Mac Schwager called it "much-needed" (because it genuinely is).
Four professors at the University of Colorado Boulder spent years building it from lecture notes. MIT Press published it. Then they open-sourced the whole thing under Creative Commons.
PDF. Free. GitHub.
If you're trying to understand how autonomous robots actually work (not just the frontier research, but the foundations), this is where to start.
📌 [https://t.co/bw8zoK8MmB]
Share this with your fellow roboticist!
——
Weekly robotics and AI insights.
Subscribe free: https://t.co/9Nm01QUcw3](https://pbs.twimg.com/media/HKmR6oLXoAE50Fm.jpg)




























