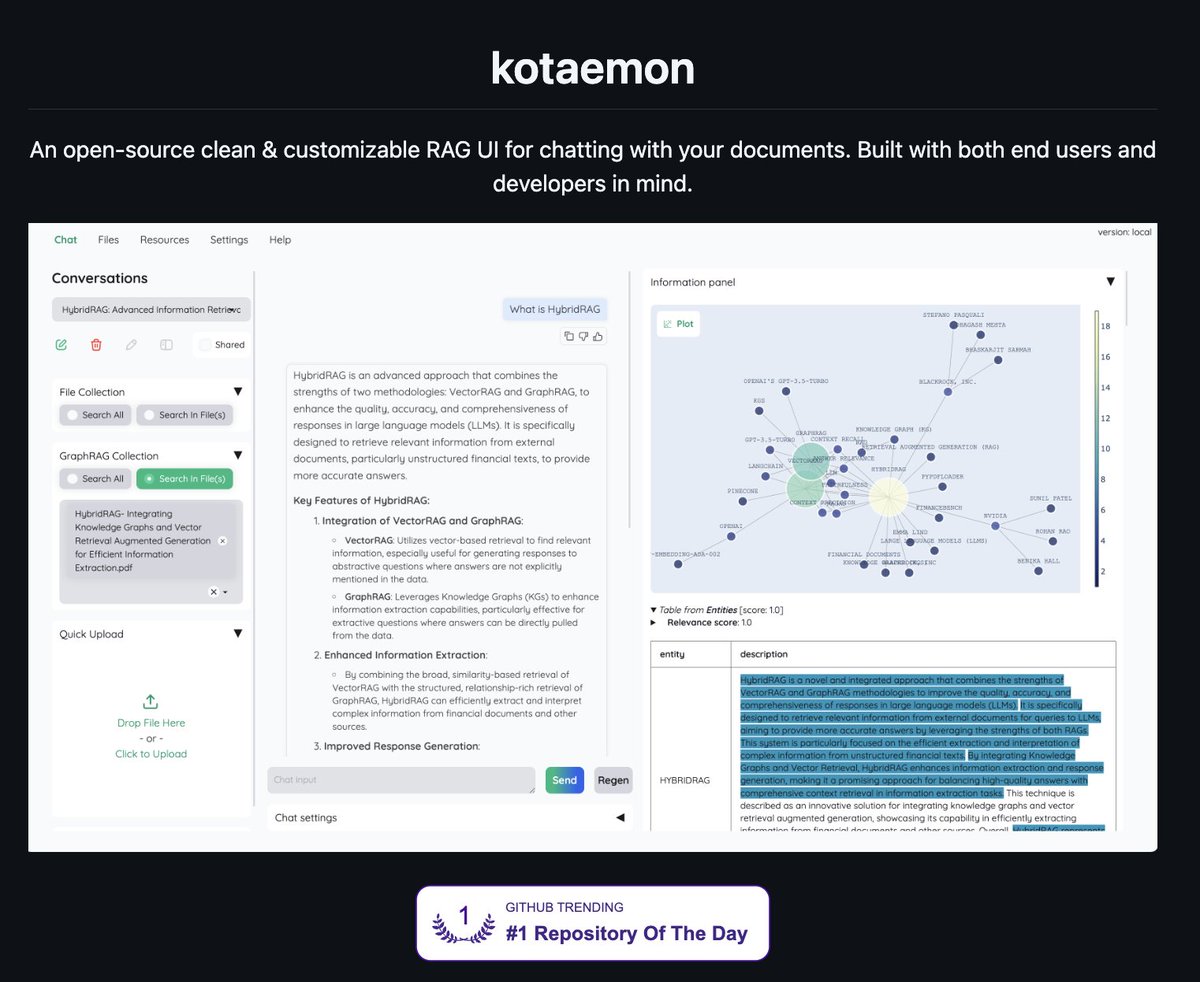
INSID3 segments objects across domains using ONLY ONE annotated example
it works entirely without a segmentation decoder, task-specific fine-tuning, or external mask generators like SAM
CVPR 2026 paper with enormous practical potential
Another cool stuff from NVIDIA.
LocateAnything - high-speed visual search engine. You provide a text prompt and it instantly pinpoints that object's exact location in an image.
- 10x speedup for dense object detection
- Qwen2.5-3B + Moon-ViT
- Fast/Slow/Hybrid modes
- trained on 138M samples for UI, docs, generic grounding.
https://t.co/bEvD6pRKaR
@xenovacom Thanks for sharing! I was just trying it but couldn't see selections when clicking on a object of interest. Also processing video doesn't show any selected area. Something i am missing?
I am obsessed with Sparse Autoencoders!
SAEs unpack so much existing value and unlock exciting new capabilities. It's happening in text, images and even proteins.
This is a long thread with lots of links and quote tweets of the projects, articles and code that made me 🤯
Alright finally able to dreambooth myself with Flux for free!
Note that this is actually what @levelsio or services like @FAL or @replicate are monetizing.
Here's how (small 🧵):
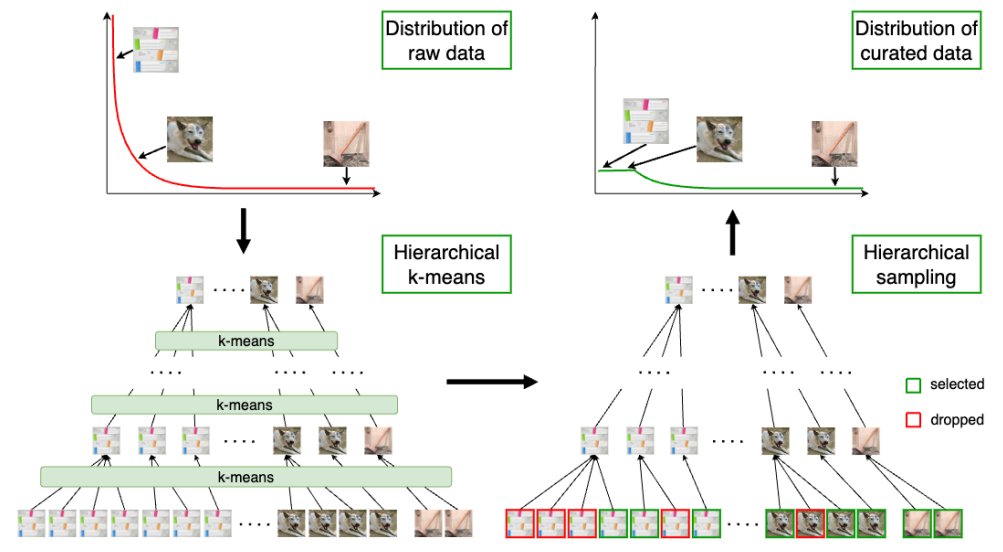
Meta presents Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach
Features trained on their automatically curated datasets outperform ones trained on manually curated data
https://t.co/HBlj7kHMPC
There’s an art to distilling these to the absolute minimal necessary text. The human brain can’t comprehend how stupid these things are without practice.
Analyzing and Improving the Training Dynamics of Diffusion Models
paper page: https://t.co/qzZIA0SxW6
Diffusion models currently dominate the field of data-driven image synthesis with their unparalleled scaling to large datasets. In this paper, we identify and rectify several causes for uneven and ineffective training in the popular ADM diffusion model architecture, without altering its high-level structure. Observing uncontrolled magnitude changes and imbalances in both the network activations and weights over the course of training, we redesign the network layers to preserve activation, weight, and update magnitudes on expectation. We find that systematic application of this philosophy eliminates the observed drifts and imbalances, resulting in considerably better networks at equal computational complexity. Our modifications improve the previous record FID of 2.41 in ImageNet-512 synthesis to 1.81, achieved using fast deterministic sampling. As an independent contribution, we present a method for setting the exponential moving average (EMA) parameters post-hoc, i.e., after completing the training run. This allows precise tuning of EMA length without the cost of performing several training runs, and reveals its surprising interactions with network architecture, training time, and guidance.
Style Aligned Image Generation via Shared Attention
paper page: https://t.co/GsbI3fRShE
Large-scale Text-to-Image (T2I) models have rapidly gained prominence across creative fields, generating visually compelling outputs from textual prompts. However, controlling these models to ensure consistent style remains challenging, with existing methods necessitating fine-tuning and manual intervention to disentangle content and style. In this paper, we introduce StyleAligned, a novel technique designed to establish style alignment among a series of generated images. By employing minimal `attention sharing' during the diffusion process, our method maintains style consistency across images within T2I models. This approach allows for the creation of style-consistent images using a reference style through a straightforward inversion operation. Our method's evaluation across diverse styles and text prompts demonstrates high-quality synthesis and fidelity, underscoring its efficacy in achieving consistent style across various inputs.