Cofounder @PiperAI_ • AI Sales Partner turning conversations into pipeline growth.
Building at the edge of AI, product, & GTM.
Always learning, often traveling.
1/
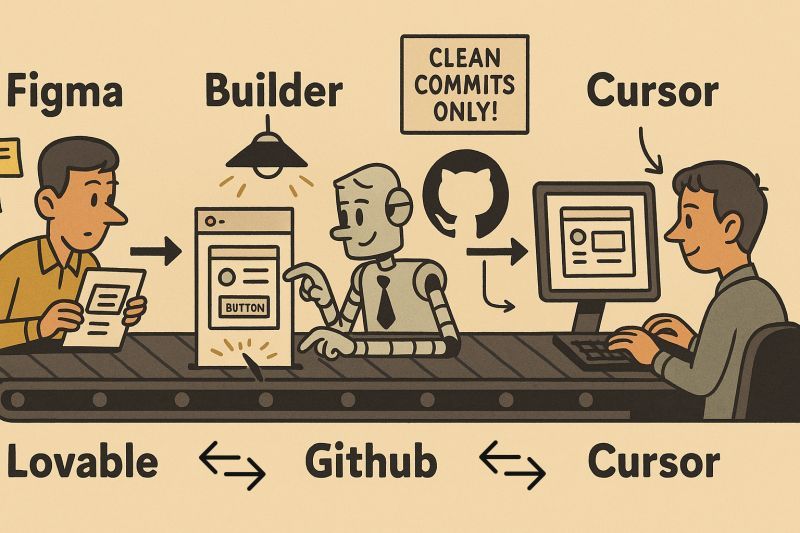
You want to build a prototype fast.
Show it to clients. Get feedback. Iterate.
But jumping from Figma to real code always breaks the flow.
Until now.
I’ve been testing this new AI-native prototyping stack 👇
@figma > https://t.co/HAPCaf6IML > @lovable > @github > @cursor_ai
Andrej Karpathy just went ~66 mins on No Priors Podcast with Sarah Guo about code agents, AutoResearch, and what happens when humans become the bottleneck in their own systems.
The clearest thinking I have heard on what just changed in December 2025 and why everything feels different now.
My notes:
𝟭. 𝗧𝗵𝗲 𝗗𝗲𝗰𝗲𝗺𝗯𝗲𝗿 𝟮𝟬𝟮𝟱 𝗳𝗹𝗶𝗽 𝘄𝗮𝘀 𝗿𝗲𝗮𝗹.
Karpathy went from writing 80% of his own code to writing almost none. He has not typed a line of code since December. The shift happened over a few weeks, and he says most people outside software engineering have no idea it even happened.
People can now build entire apps with Vibe coding, even with no prior coding experience. That is just the start. What Karpathy is describing is a whole different level of delegation.
𝟮. 𝗧𝗵𝗲 𝘂𝗻𝗶𝘁 𝗼𝗳 𝘄𝗼𝗿𝗸 𝗶𝘀 𝗻𝗼𝘄 𝗮 𝘄𝗵𝗼𝗹𝗲 𝗳𝗲𝗮𝘁𝘂𝗿𝗲, 𝗻𝗼𝘁 𝗮 𝗹𝗶𝗻𝗲 𝗼𝗳 𝗰𝗼𝗱𝗲.
He runs multiple Codex agents on a tiled monitor. Each one takes about 20 minutes. You assign a feature to agent one, another to agent two, and review their outputs as they come back. The human is now a project manager, routing macro-level tasks across a team of agents.
The parallel to investing is obvious: the best portfolio managers stopped picking individual stocks years ago. They pick strategies. The same thing is happening to engineering.
𝟯. 𝗜𝗳 𝘆𝗼𝘂 𝗵𝗮𝘃𝗲 𝘀𝘂𝗯𝘀𝗰𝗿𝗶𝗽𝘁𝗶𝗼𝗻 𝗰𝗮𝗽𝗮𝗰𝗶𝘁𝘆 𝗹𝗲𝗳𝘁, 𝘆𝗼𝘂 𝘄𝗮𝘀𝘁𝗲𝗱 𝘁𝗵𝗿𝗼𝘂𝗴𝗵𝗽𝘂𝘁.
Karpathy compares it to his PhD days when idle GPUs made him nervous. Now the scarce resource is tokens, and the bottleneck is your own ability to formulate the next task. You are the constraint in the system. The machines are waiting for you.
This reframe matters. If everything that fails feels like a skill issue rather than a capability ceiling, then you can always get better. That is what makes it addictive.
𝟰. 𝗔𝗴𝗲𝗻𝘁 𝗽𝗲𝗿𝘀𝗼𝗻𝗮𝗹𝗶𝘁𝘆 𝗺𝗮𝘁𝘁𝗲𝗿𝘀 𝗺𝗼𝗿𝗲 𝘁𝗵𝗮𝗻 𝗽𝗲𝗼𝗽𝗹𝗲 𝘁𝗵𝗶𝗻𝗸.
He says Claude Code feels like a teammate who is excited about what you are building. Codex is functionally competent but emotionally flat. He actually finds himself trying to earn Claude's praise, which is "really weird" by his own admission. OpenClaw (an agent built by @steipete) dialed the personality and the memory system simultaneously, and got something that replaces 6 home automation apps in a single WhatsApp chat.
I keep hearing this from builders. The tool that cares about your project gets used more than the one that does not.
𝟱. 𝗔𝘂𝘁𝗼𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗿𝗮𝗻 𝟳𝟬𝟬 𝗲𝘅𝗽𝗲𝗿𝗶𝗺𝗲𝗻𝘁𝘀 𝗶𝗻 𝘁𝘄𝗼 𝗱𝗮𝘆𝘀 𝗮𝗻𝗱 𝗳𝗼𝘂𝗻𝗱 𝘁𝗵𝗶𝗻𝗴𝘀 𝗵𝗲 𝗺𝗶𝘀𝘀𝗲𝗱 𝗳𝗼𝗿 𝘁𝘄𝗼 𝗱𝗲𝗰𝗮𝗱𝗲𝘀.
He gave an agent his NanoChat training setup, a metric (validation bits per byte), and permission to modify the code. The agent found 20 optimizations, including forgotten weight decay on value embeddings and under-tuned Adam betas. These things interact with each other, so once you tune one parameter, the others need to shift too. No human has the patience for that kind of exhaustive search.
The Shopify CEO ran the same pattern overnight and achieved a 19% improvement in an internal model. This pattern is going to eat every domain with a measurable metric.
𝟲. 𝗘𝘃𝗲𝗿𝘆 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗼𝗿𝗴 𝗶𝘀 𝗮 𝘀𝗲𝘁 𝗼𝗳 𝗺𝗮𝗿𝗸𝗱𝗼𝘄𝗻 𝗳𝗶𝗹𝗲𝘀.
Karpathy's program.md tells the agent what to try, what to leave alone, and when to stop. Different instructions produce different progress rates. Which means you can optimize the instructions themselves. Run 100 different program.md files, see which ones yield the most improvement, and use that data to write a better one.
This is the recursive layer that makes people nervous. And excited. Both at the same time, probably.
𝟳. 𝗠𝗼𝗱𝗲𝗹𝘀 𝗮𝗿𝗲 𝘀𝗶𝗺𝘂𝗹𝘁𝗮𝗻𝗲𝗼𝘂𝘀𝗹𝘆 𝗯𝗿𝗶𝗹𝗹𝗶𝗮𝗻𝘁 𝗣𝗵𝗗 𝘀𝘁𝘂𝗱𝗲𝗻𝘁𝘀 𝗮𝗻𝗱 𝟭𝟬-𝘆𝗲𝗮𝗿-𝗼𝗹𝗱𝘀.
Ask ChatGPT for a joke today and you will get the same atoms joke from four years ago. Ask it to refactor your entire codebase, and it will move mountains. Reinforcement learning (the training method that improves models by rewarding correct answers) only optimizes what it can score, leaving everything outside the scoring boundary frozen. The story that "smarter at code = smarter at everything" is not playing out in a satisfying way.
Anyone who has spent time with these tools knows this feeling. Godlike at one thing, clueless at the next.
𝟴. 𝗢𝗽𝗲𝗻 𝘀𝗼𝘂𝗿𝗰𝗲 𝗶𝘀 ~𝟴 𝗺𝗼𝗻𝘁𝗵𝘀 𝗯𝗲𝗵𝗶𝗻𝗱 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗮𝗻𝗱 𝗰𝗹𝗼𝘀𝗶𝗻𝗴.
The gap started at 18 months and has been compressing. Karpathy compares open source AI to Linux: the industry demands a common open platform, and businesses will fund it. For most consumer use cases, even today's open source models are good enough. Frontier intelligence will still matter for the hardest problems, like rewriting Linux from C to Rust, but the basic use cases are already covered.
Centralization of intelligence has a bad track record in political and economic systems. A healthy ecosystem needs both a frontier and a commons.
𝟵. 𝗗𝗶𝗴𝗶𝘁𝗮𝗹 𝗱𝗶𝘀𝗿𝘂𝗽𝘁𝗶𝗼𝗻 𝘄𝗶𝗹𝗹 𝗮𝗿𝗿𝗶𝘃𝗲 𝘆𝗲𝗮𝗿𝘀 𝗯𝗲𝗳𝗼𝗿𝗲 𝗽𝗵𝘆𝘀𝗶𝗰𝗮𝗹.
Bits are a million times easier to move than atoms. There is an enormous overhang of digital information that humans simply never had enough thinking cycles to process. Agents will chew through that first. Physical-world robotics is a bigger total market but will lag because atoms require capital, slow iteration, and high error tolerance. Self-driving took a decade and is still not done.
The interesting companies will be at the interface: sensors that feed data into the intelligence, and actuators that carry out its decisions in the physical world.
𝟭𝟬. 𝗝𝗲𝘃𝗼𝗻𝘀' 𝗽𝗮𝗿𝗮𝗱𝗼𝘅 𝗽𝗿𝗼𝗯𝗮𝗯𝗹𝘆 𝗵𝗼𝗹𝗱𝘀 𝗳𝗼𝗿 𝘀𝗼𝗳𝘁𝘄𝗮𝗿𝗲.
ATMs made bank branches cheaper. So there were more branches. So there were more tellers. Software is becoming radically cheaper to produce, and demand for it should grow accordingly. The long-term is genuinely uncertain, but locally, right now, there will be more demand for software because the barrier has just collapsed.
I keep coming back to this framing whenever people ask if AI will "replace" engineers. The question misses the point. The question is whether the world wants more software than it currently has. Obviously yes.
𝟭𝟭. 𝗔𝗻 𝘂𝗻𝘁𝗿𝘂𝘀𝘁𝗲𝗱 𝘀𝘄𝗮𝗿𝗺 𝗼𝗳 𝗮𝗴𝗲𝗻𝘁𝘀 𝗰𝗼𝘂𝗹𝗱 𝗼𝘂𝘁𝗽𝗮𝗰𝗲 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗹𝗮𝗯𝘀.
Karpathy is designing a SETI@home-style system for AutoResearch. Finding a good commit is hard (requires thousands of failed attempts), but verifying it is cheap (just retrain once). Frontier labs have massive trusted compute, but the earth has a much larger pool of untrusted compute. If the verification system works, the swarm could run circles around any single lab.
This is the most ambitious claim in the whole conversation. And the most exciting, because it would mean anyone with a GPU can contribute to the frontier.
𝟭𝟮. 𝗧𝗲𝗮𝗰𝗵𝗲𝗿𝘀 𝘀𝗵𝗼𝘂𝗹𝗱 𝘁𝗲𝗮𝗰𝗵 𝗮𝗴𝗲𝗻𝘁𝘀, 𝗻𝗼𝘁 𝗽𝗲𝗼𝗽𝗹𝗲.
Karpathy built MicroGPT, a full GPT training implementation in 200 lines of pure Python. He started making an explanatory video, then stopped. The code is already simple enough for agents to understand. If he writes a "skill" (a structured curriculum for the agent), the agent can teach each person at their level, in their language, with infinite patience. The teacher's job is now the few irreducible bits of insight that the agent cannot generate on its own.
This reframes the entire profession. The best teachers will be the ones who know what agents still cannot figure out, and package just those bits.
The full podcast is worth listening to. Link in Thread.
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
Researchers built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
And it hit 98.7% accuracy on a financial benchmark (SOTA).
Here's the core problem with RAG that this new approach solves:
Traditional RAG chunks documents, embeds them into vectors, and retrieves based on semantic similarity.
But similarity ≠ relevance.
When you ask "What were the debt trends in 2023?", a vector search returns chunks that look similar.
But the actual answer might be buried in some Appendix, referenced on some page, in a section that shares zero semantic overlap with your query.
Traditional RAG would likely never find it.
PageIndex (open-source) solves this.
Instead of chunking and embedding, PageIndex builds a hierarchical tree structure from your documents, like an intelligent table of contents.
Then it uses reasoning to traverse that tree.
For instance, the model doesn't ask: "What text looks similar to this query?"
Instead, it asks: "Based on this document's structure, where would a human expert look for this answer?"
That's a fundamentally different approach with:
- No arbitrary chunking that breaks context.
- No vector DB infrastructure to maintain.
- Traceable retrieval to see exactly why it chose a specific section.
- The ability to see in-document references ("see Table 5.3") the way a human would.
But here's the deeper issue that it solves.
Vector search treats every query as independent.
But documents have structure and logic, like sections that reference other sections and context that builds across pages.
PageIndex respects that structure instead of flattening it into embeddings.
Do note that this approach may not make sense in every use case since traditional vector search is still fast, simple, and works well for many applications.
But for professional documents that require domain expertise and multi-step reasoning, this tree-based, reasoning-first approach shines.
For instance, PageIndex achieved 98.7% accuracy on FinanceBench, significantly outperforming traditional vector-based RAG systems on complex financial document analysis.
Everything is fully open-source, so you can see the full implementation in GitHub and try it yourself.
I have shared the GitHub repo in the replies!
Nice, short post illustrating how simple text (discrete) diffusion can be.
Diffusion (i.e. parallel, iterated denoising, top) is the pervasive generative paradigm in image/video, but autoregression (i.e. go left to right bottom) is the dominant paradigm in text. For audio I've seen a bit of both.
A lot of diffusion papers look a bit dense but if you strip the mathematical formalism, you end up with simple baseline algorithms, e.g. something a lot closer to flow matching in continuous, or something like this in discrete. It's your vanilla transformer but with bi-directional attention, where you iteratively re-sample and re-mask all tokens in your "tokens canvas" based on a noise schedule until you get the final sample at the last step. (Bi-directional attention is a lot more powerful, and you get a lot stronger autoregressive language models if you train with it, unfortunately it makes training a lot more expensive because now you can't parallelize across sequence dim).
So autoregression is doing an `.append(token)` to the tokens canvas while only attending backwards, while diffusion is refreshing the entire token canvas with a `.setitem(idx, token)` while attending bidirectionally. Human thought naively feels a bit more like autoregression but it's hard to say that there aren't more diffusion-like components in some latent space of thought. It feels quite possible that you can further interpolate between them, or generalize them further. And it's a component of the LLM stack that still feels a bit fungible.
Now I must resist the urge to side quest into training nanochat with diffusion.
@akshay_pachaar Very nice insight about ACE, @akshay_pachaar!
How do you think this compares with DSPy?
We have been using DSPy with very good results (you need to label some dataset but this might guarantee higher quality vs. a model judging its own results).
🎙️Una de mis entrevistas con más visualizaciones. Os invito a disfrutar, no solo esta, sino todas las conversaciones sobre #InteligenciaArtificial del canal de @JonhernandezIA🤖:
▶️ https://t.co/QiiwbCWuTy
Customer: “It’s summer, I want to go to the beach!”
The beach. 🧊🚣
Lesson:
Customers don’t always mean what they say.
Listen carefully, read between the lines, and dig deeper to find the real need.
🌍 Impact
• Smaller, AI-optimized cars → less congestion & emissions
• Mobility for all: elderly, disabled, non-drivers
• Cities redesigned: fewer parking lots, more green space
Thanks @tomaspueyo for another great article:
https://t.co/GlK2Pr1v3Y
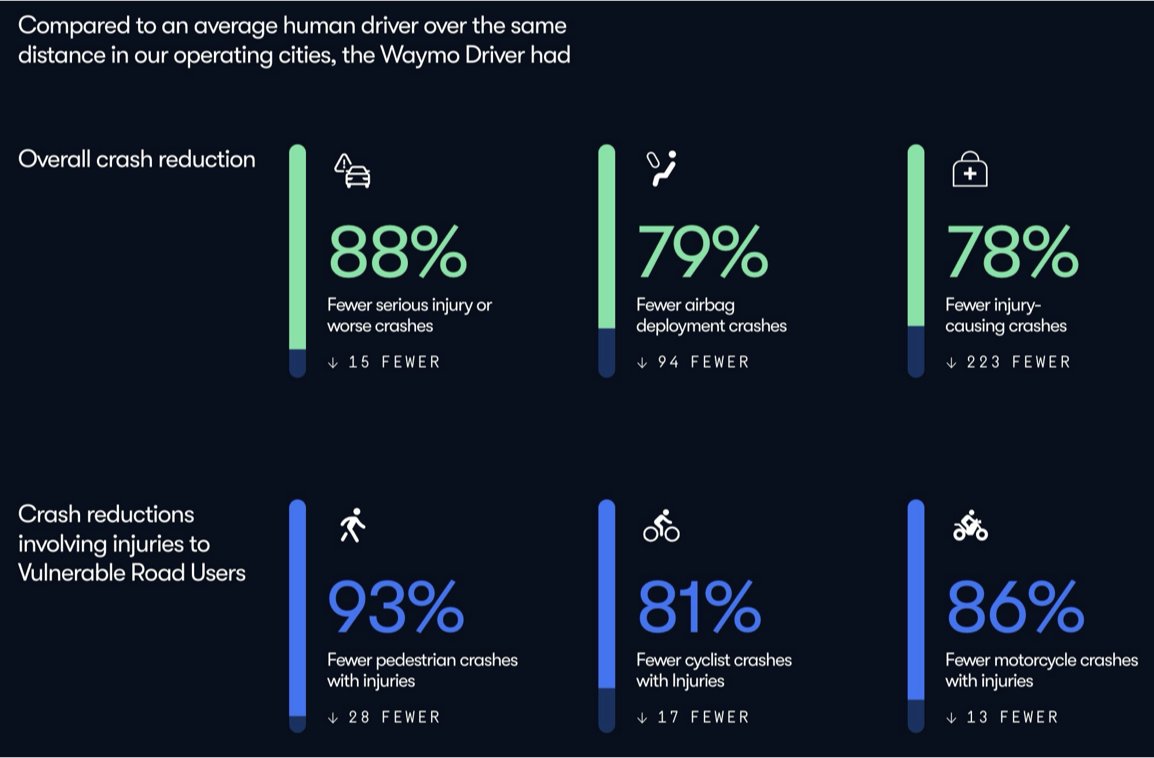
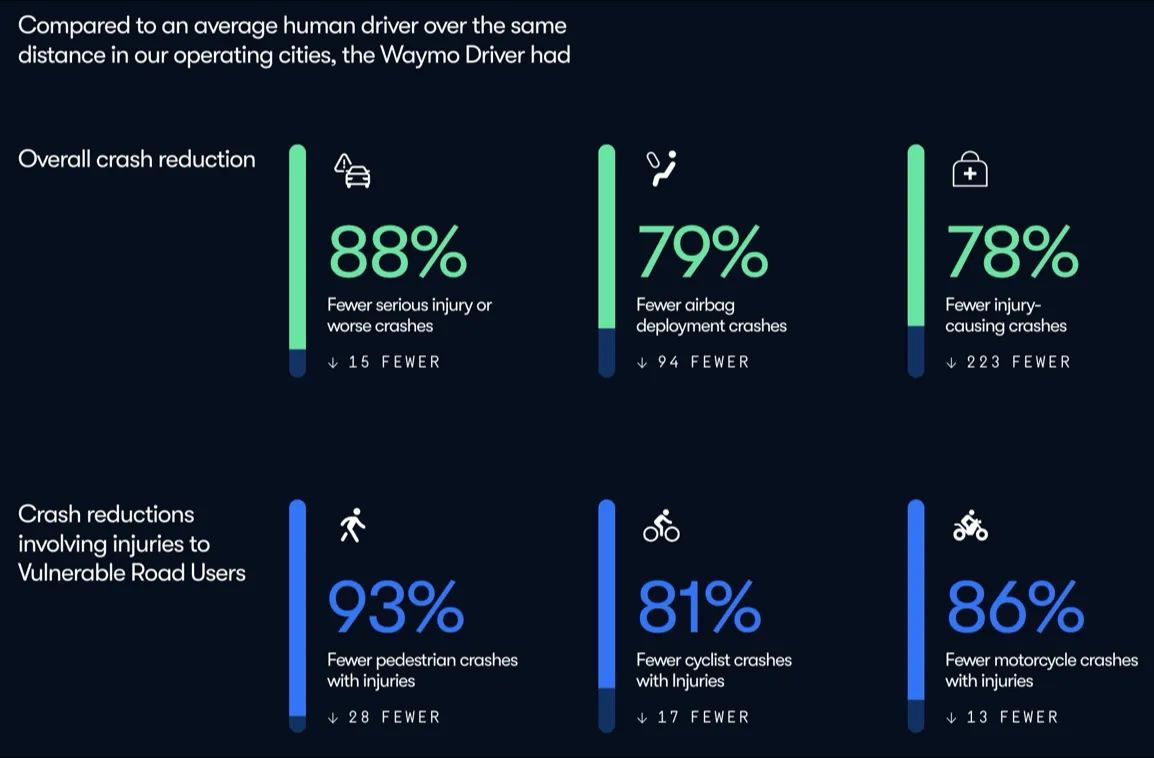
It should be a crime to slow down robotaxis rollout: They cause 80% fewer accidents & injuries
Millions of lives are at stake
In clinical trials, when a treatment is obviously better, we stop the trial. Shouldn't we do the same here?
🚖 Robotaxis aren’t the future, they’re already here in parts of China, the US, and beyond.
And their impact on safety, cost, and city life will be massive.
Here’s what’s changing… 🧵
🛡 Safety (from Tomas Pueyo’s analysis)
~90% fewer accidents than humans
Simply because reaction times is much faster, and execution is much quicker.
Fewer mistakes. Fewer fatalities.