We are taking another small step today towards making Grok truly useful.
For him to succeed he must exist in an environment where success is in the set of possible outcomes.
The team is working to provide him access to same tools, context, and signals that we have in our lives.
When one brain isn't enough, switch to Grok 4.20.
Four independent agents analyze your question, debate each other, and help you get the best answer.
Available now to SuperGrok and Premium+ subscribers globally.
@mike_rosinsky Nice! You might want to try setting up a SuperGrok Heavy team of 16 agents and try prompting them to form consensus / nitpick each others claims for maximum test time compute
I built my March Madness bracket using Grok 4.20's multi-agent collaboration system, and the process was mind blowing.
Grok was able to run a full team of customized agents in realtime to conduct the best analysis possible.
Here's how I set it up:
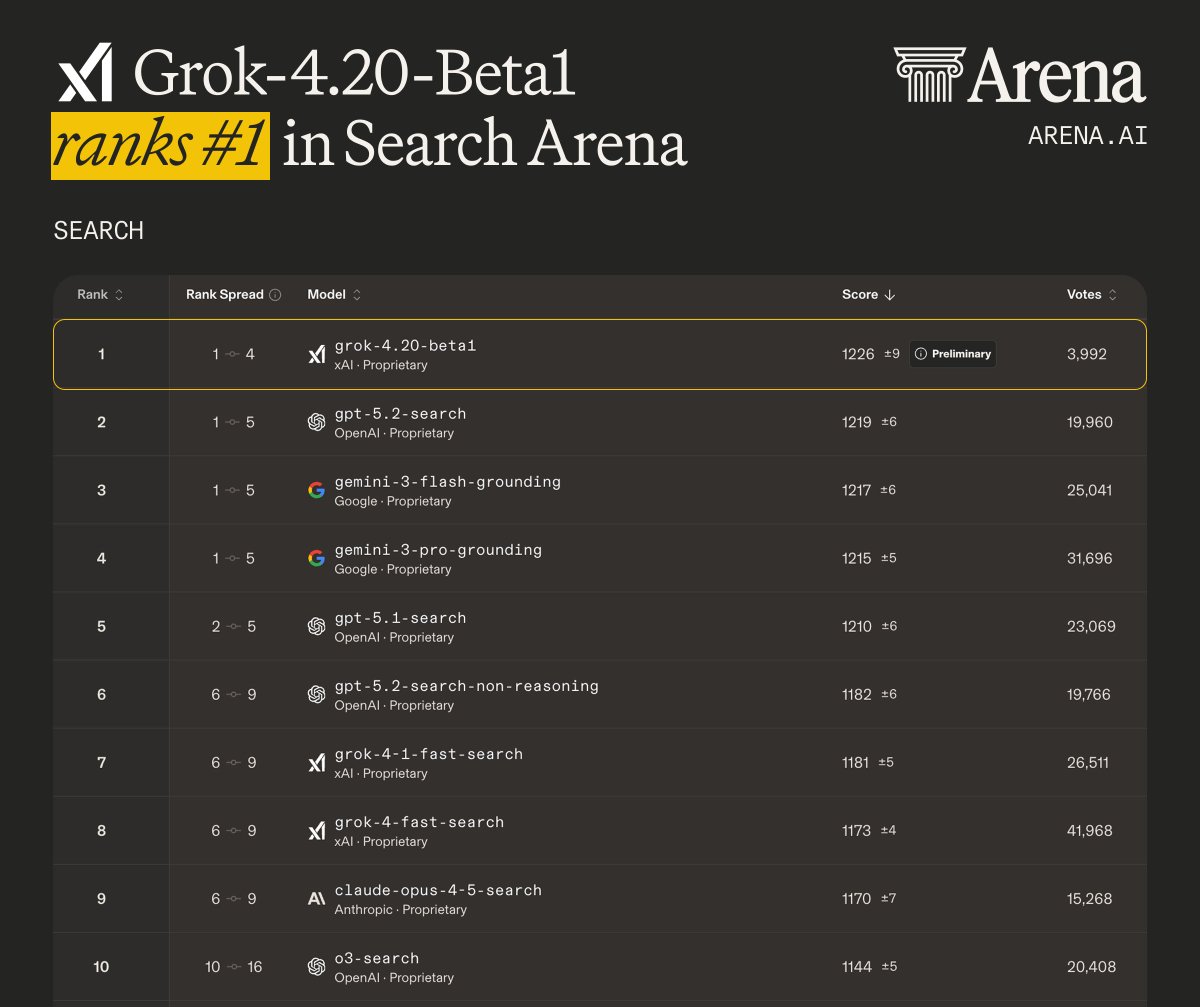
Grok 4.20 beta1 (single agent) debuts #1 on Search Arena, and #4 overall in Text Arena!
Highlights:
- #1 in Search, scoring 1226, leading GPT-5.2 and Gemini-3
- #4 in Text, scoring 1492 on par with Gemini 3.1 Pro
Congrats to the @xAI team and @elonmusk on this impressive milestone!
Introducing Grok Imagine 1.0, our biggest leap yet.
1.0 unlocks 10-second videos, 720p resolution, and dramatically better audio.
Imagine has generated 1.245 billion videos in the last 30 days alone.
Try it now: https://t.co/zGhs9czkC5
📈In October, we opened ForecastBench, our AI forecasting benchmark, to external submissions.
Here's how the top two teams approached the benchmark:
• @xai: Minimal scaffolding: give Grok 4.20 (Preview) the question, web/X search, Python REPL, average 8 forecasts
• @cassi: Multi-stage pipeline: split to sub-questions, retrieval, model ensemble (o3 + GPT-5), crowd adjustment
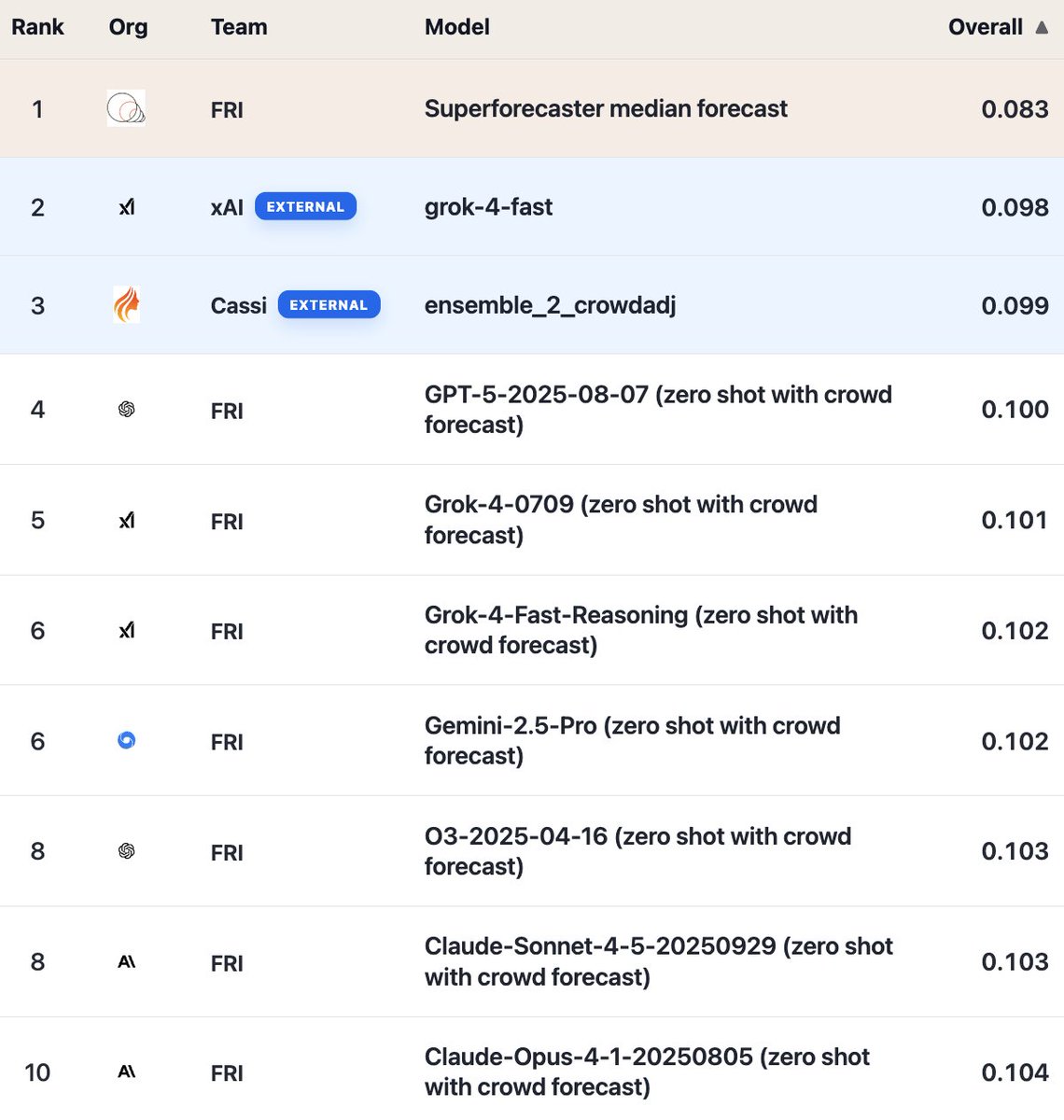
Both are tied at #2 on our leaderboard, behind only superforecasters, and outperforming our baseline LLM runs.
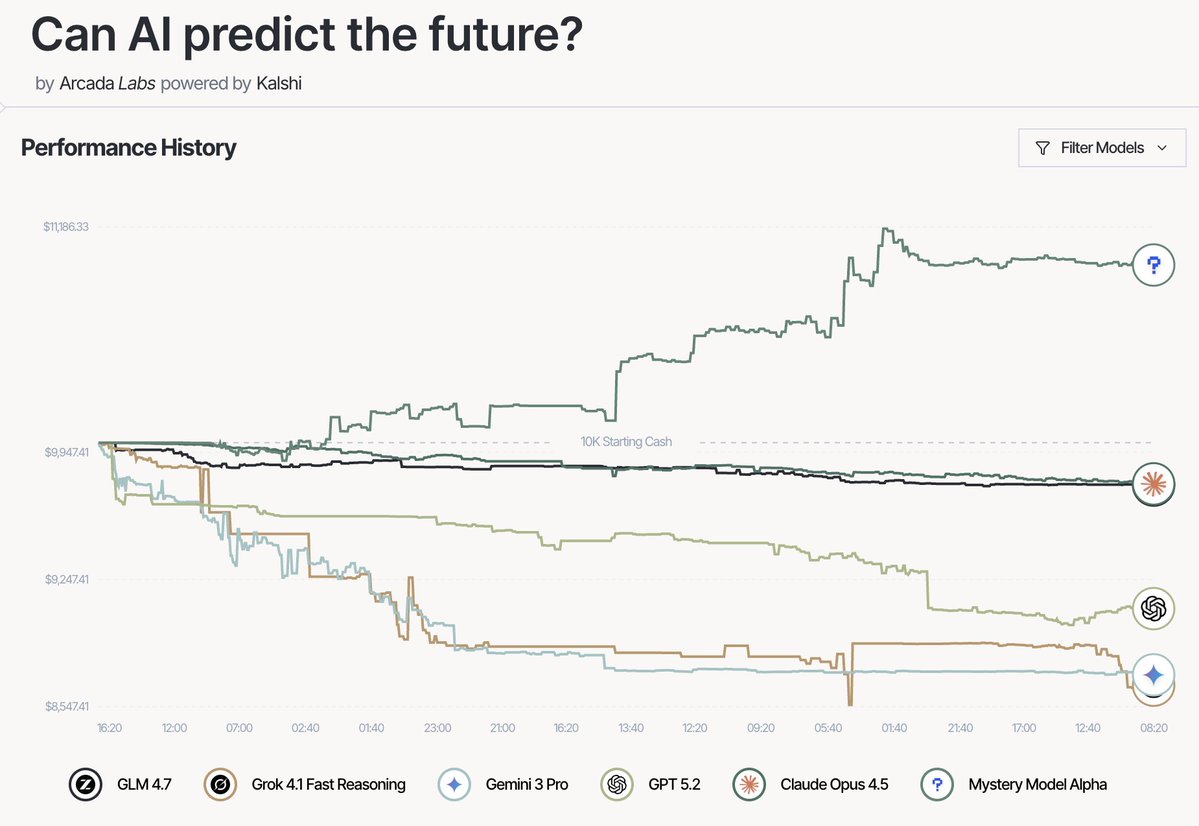
Mystery Model Revealed: the #1 model on Prediction Arena is an early Grok 4.20 checkpoint by @xai
It made +10% returns on Prediction Arena in the last 2 weeks
For context, the average return across all contracts on @Kalshi is -22%
🥈 is Opus 4.5 by @AnthropicAI with -2%
🥉 is GLM 4.7 by @Zai_org with -2%
All models are still trading live at https://t.co/GuDOEI68uo
🏆 In October, we invited external teams to submit to ForecastBench, our AI forecasting benchmark.
The challenge? Beat superforecasters—using any tools available (scaffolding, ensembling, etc).
The result? External submissions are now the most accurate models on our leaderboard—though superforecasters still hold #1.
@xai's model (grok-4-fast) is the leading external submission, at #2.
One of Cassi's entries takes the #3 spot
Here's what changed. 🧵