Kunci waras di dunia yang gila itu ternyata simpel:
Keluar.
Gerak.
Ketemu orang.
Lihat dunia.
Pokoknya jangan diem. Jangan diem otaknya. Jangan diem badannya. Jangan diem jiwanya.
Masalah mah ada terus, dan solusinya pelan-pelan pasti ketemu. Yang penting gerak. Just keep moving.
setiap aku ngerasa ketinggalan aku selalu sadar bahwa aku ini berangkatnya dari minus, mencapai titik nol udah jadi sebuah pencapaian besar dalam hidupku
People who think they are extremely self-aware are often doing nothing more than turning themselves into a permanent psychological project. Every reaction is analyzed, every emotion is interpreted, every insecurity is examined, every childhood event is revisited.
They call it awareness, but most of the time it is simply self-preoccupation with intellectual decoration around it. The ego has not disappeared, it has become the observer, the analyst, the therapist, and the patient all at once. Years can pass this way. The prison remains exactly where it was. Only the description of the prison becomes more sophisticated.
Underrated life advice: Have more hobbies and fewer opinions. Learn an instrument. Plant a garden. Build something with your hands. Cook. Paint. Run. The happiest people I know spend less time debating life and more time actually living it.
Paper review: LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
https://t.co/TpFFnwPWkc
Nice clean github: https://t.co/HOuqEf0HaF
This is the application of the LeJEPA results to world models, trained offline on experience from three different robotics style tests with one to two million steps in each dataset. Re-states the benefits of the SigReg loss relative to prior world model approaches.
Uses ImageNet standard 224x224 RGB pixel input images with an unmodified ViT-Tiny vision transformer from HuggingFace to generate latents. One extra post-projection step is needed to give SigReg the necessary freedom to perturb the latents into independent gaussians, since ViT ends with a layernorm’d layer. Also tested with ResNet-18, which still performed well, but slightly worse.
Uses a 192 dimensional latent. Performance slightly dropped when doubling the latent size to 384; it would be nice to know if it was stable there, or if it continued worsening with excessive latents. There is a relationship between batch size and SIGReg, the larger latent may have improved performance if the batch size was increased.
The predictor is implemented as a ViT-S backbone – Why a vision transformer when the latent is flat? Uses a history of 3 sets of latents for two of the benchmarks and 1 for the other. Performance was markedly better with the “small” ViT model than the “tiny”, but the larger “base” model degraded notably, which is interesting.
Dropout of 0.1 on the predictor significantly improved performance. 0.2 was still better than 0.0, but 0.5 was worse.
Trained with a batch of 128 x 4 trajectories. I wish their training loss graphs were more zoomed in with grid lines.
Performs planning at test time instead of building a policy by training in imagination like Dreamer / Diamond. Rolls out 300 initially random sets of actions up to a planning horizon H of 5 (at frame-skip 5). Iterates up to 30 times using the Cross Entropy Method (CEM). The main paper body mentions using Model Predictive Control (MPC) strategy, where only the first K planned actions are executed before replanning, but appendix D says they execute all 5 planned actions.
After training, they probe the latent space to demonstrate that it does capture and represent physically meaningful quantities. They also implement a decoder from the latent space back to pixels – not used by the algorithms, but helpful to see what things the latent space is actually representing. They tested incorporating the reconstruction loss into training, but it hurt performance somewhat.
They wound up with a 0.1 lambda for SigReg, as opposed to 0.05 in the LeJEPA paper. 1024 sigreg projections, but observe the number has negligible impact
I like the JEPA framework, but so far my attempts to use it on Atari games with value functions have not matched my other efforts.
Kamu Mau Pasang AC ?
Coba pertimbangan beberapa merek ini
Waktu tukang lagi masang AC di kostku. aku sempat tanya AC paling dingin apa? Trus jawabannya "DAIKIN"
Kata tukang AC nya:
- Dinginnya Cepat
- Suhu 26° udah kerasa dingin kali
- Jarang ada keluhan
- Tapi, Harganya lebih mahal
Nah kalau aku sendiri pasang merek Sharp karna:
- Sering pakai merek ini di rumah
- Harganya lebih murah
Tapi semua brand AC ini balik ke kebutuhan masing" ya. Karna beda merek beda kelebihan/kekurangan
📷: tt/genzine
Your brain physically rewrites itself every time you pick up a pen.
Neuroscientists at Norwegian University scanned students' brains while they handwrote letters versus typing the same letters on a keyboard.
The results shattered decades of assumptions about how we process information.
Handwriting activated massive networks in the sensorimotor cortex, the visual processing centers, and the hippocampus simultaneously. Complex neural symphonies lit up across multiple brain regions, creating rich interconnected pathways between motor control, visual recognition, and memory formation.
Typing the same letters? The brain activity looked like someone had dimmed the lights across entire cognitive districts. The neural networks that flourished during handwriting simply went dark.
The difference?
When you form letters by hand, your brain constructs elaborate spatial maps of each character. The motor cortex learns the precise pressure, angle, and trajectory needed to create an 'A' versus a 'B.' Your visual system tracks the ink flowing from pen to paper in real time. Your parietal lobe integrates hand position with eye movement. Your hippocampus encodes not just what you wrote, but how the writing felt, where you paused, which words required more pressure.
Typing activates almost none of that circuitry. You press a key, a letter appears. The motor movement is binary. The visual feedback is uniform. The spatial relationship between thought and symbol gets mediated by a machine that standardizes every character into identical fonts and spacing.
Your brain treats these as fundamentally different cognitive tasks.
The evolutionary context makes this obvious once you see it. Human hands developed for manipulation, creation, and fine motor control over millions of years. We painted on cave walls, carved bone tools, and shaped clay vessels long before we invented written language. When writing emerged 5,000 years ago, it built on top of existing neural infrastructure that already connected hand movement with symbolic thinking.
Keyboards appeared 150 years ago. Touchscreen typing maybe 20 years ago. From an evolutionary timeline perspective, we started using them approximately yesterday. Our brains are still running ancient software that expects physical engagement with symbols.
That software produces dramatically different learning outcomes.
Students who take handwritten notes consistently outperform students who type the same information on memory tests, comprehension assessments, and creative applications of the material. The difference persists even when researchers account for typing speed, note length, and time spent studying.
The act of forming letters by hand forces deeper processing at the moment of information encounter. You cannot handwrite as fast as someone speaks, so your brain must actively filter, summarize, and prioritize information in real time. The motor effort required to form each word creates additional memory traces that typing does not generate.
Children who learn to write letters by hand develop reading skills faster than children who learn letters primarily through typing or screen interaction. The sensorimotor experience of creating letterforms helps their brains recognize those same letterforms when they encounter them in text.
Adults who handwrite shopping lists, daily schedules, or meeting notes remember the information better than adults who type identical lists into phones or computers. The spatial memory of where you wrote something on a page provides retrieval cues that digital text does not offer.
These findings collide directly with how education and work environments have evolved over the past two decades. Schools replaced handwriting instruction with typing classes. Offices converted from paper systems to fully digital workflows. Students take notes on laptops. Professionals draft documents on screens.
We optimized for speed and efficiency while accidentally severing the neural pathways that evolution spent millions of years developing.
The implications reach beyond memory and learning into fundamental questions about human cognition. If the physical act of forming symbols changes how your brain processes ideas, what happens to thinking itself when you remove the physical component?
Digital text is infinitely searchable, instantly editable, and perfectly shareable. But it may be creating brains that process information more superficially, store memories less durably, and connect ideas more weakly than brains that regularly engage in handwriting.
The neuroscience suggests we traded cognitive depth for technological convenience without realizing what we were giving up.
Some of the most innovative thinkers across history were obsessive handwriters. Darwin kept detailed handwritten journals. Einstein worked through complex theories in handwritten notebooks. Virginia Woolf wrote her novels by hand before transcribing them. Steve Jobs famously took handwritten notes during Apple meetings even as he was building the most advanced computers on Earth.
Perhaps they intuited something about the relationship between hand, brain, and insight that we measured in brain scanners but somehow forgot in practice.
Your pen is literally a cognitive enhancement device that activates neural networks digital keyboards cannot reach.
I am literally begging you to stop everything and just log how much time gets lost in the in-betweens, let alone weekends. don’t do anything with it. just log it. then see it. now, as you’re seeing it, hold this in mind: “in today’s world, you could build a fully fledged business doing what you love in a couple months by using only a fraction of that lost time you’re now staring at.” now, if you’re not boiling on the inside, you either don’t care for your freedom or you missed the point completely. this little practice might save you a lifetime.
what it takes to increase your luck (luckmaxxing)
exposure (groups, activities, environments) + risk taking + energy + right place + right time + removing any negative associations with yourself (no more unlucky jokes)+ recognizing how fortunate you are to live your life = luck
Palantir AI + Claude was used to detect, prioritize, and strike over 1,000 targets in the first 24 hours of Operation against IRAN.
The success was so ridiculous, so game-changing, that the Pentagon didn’t even wait.
What used to be just a pilot project, just something they were testing out… suddenly became official, permanent, and everywhere.
Palantir is now the core AI brain of the entire U.S. military. It’s getting rolled out across ALL branches.
🪵di sini ada yang suka baca artikel gitu kah, lagi pengen nyoba baca baca artikel ilmiah buat ganti kebiasaan doom scrolling. boleh tahu web andalan temen temen gaa? sebelumnya terima kasih yaa!
This is so brilliant. 👌
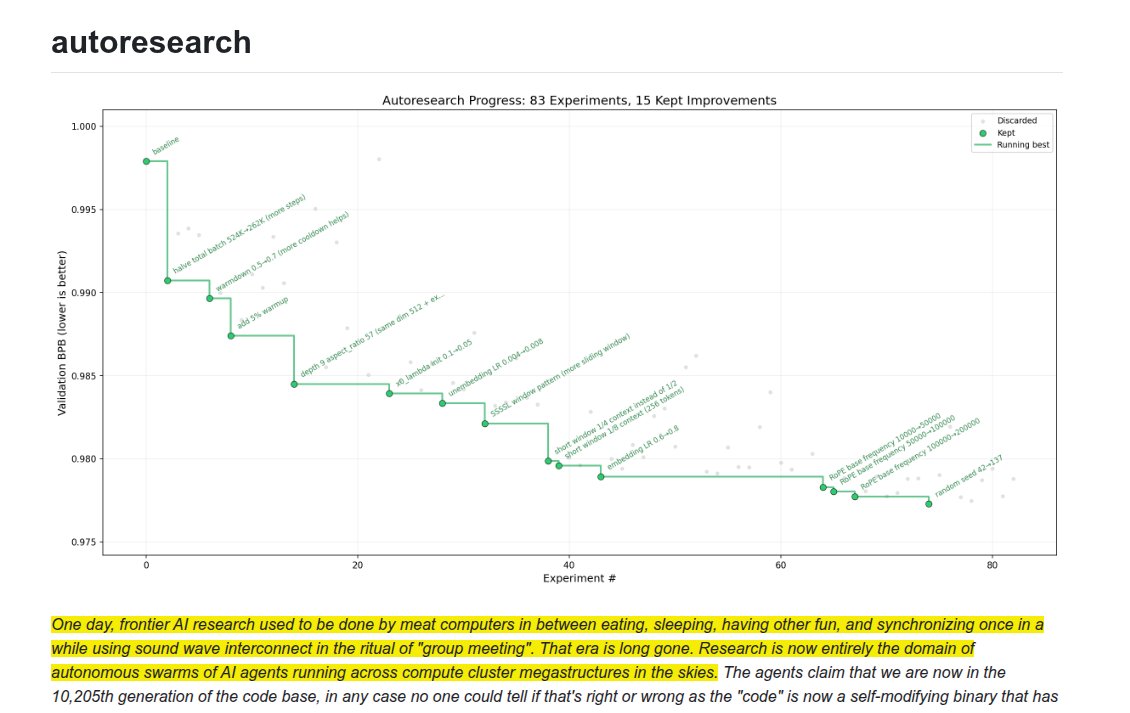
Andrej Karpathy just open-srouced a tiny tool called “autoresearch” that lets AI automatically improve its own training code.
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
You (the human) only write plain instructions in a Markdown file — things like “try bigger models” or “test new optimizers.”
The AI agent does everything else: it edits the actual training code, runs training for exactly five minutes on one GPU, checks the score (validation loss), and keeps the better version or throws the bad one away.
It repeats this loop all night in its own git branch, running about 100 experiments while you sleep.
Every run gets a 5-minute time budget, leveling the field for architectural changes.
The system evaluates success purely on which code achieves the lowest validation loss.
This setup executes 12 experiments per hour, accumulating 100 complete runs overnight on 1GPU.
This is a huge deal because the fixed 5-minute timer makes every idea fair, no matter how wild. Suddenly one person with one GPU can run a full AI research lab overnight. You no longer code experiments — you just “program the programmer” with better prompts. Prompt quality is now the only thing that matters.
AI research just became 100× faster and open to anyone.
My friend told me that that usually, Javanese people are very implicit when it comes to everything; So you often have to guess people's intentions (they don't usually say what they want directly). It must be hellish for autistic people
Dr Fei-Fei Li (@drfeifei ) on limitations of LLMs. 🎯
The same vibe of what Yann LeCun says.
"Language is purely generated signal. You don't go out in nature & there's words written in the sky for you. There is a 3D world that follows laws of physics"
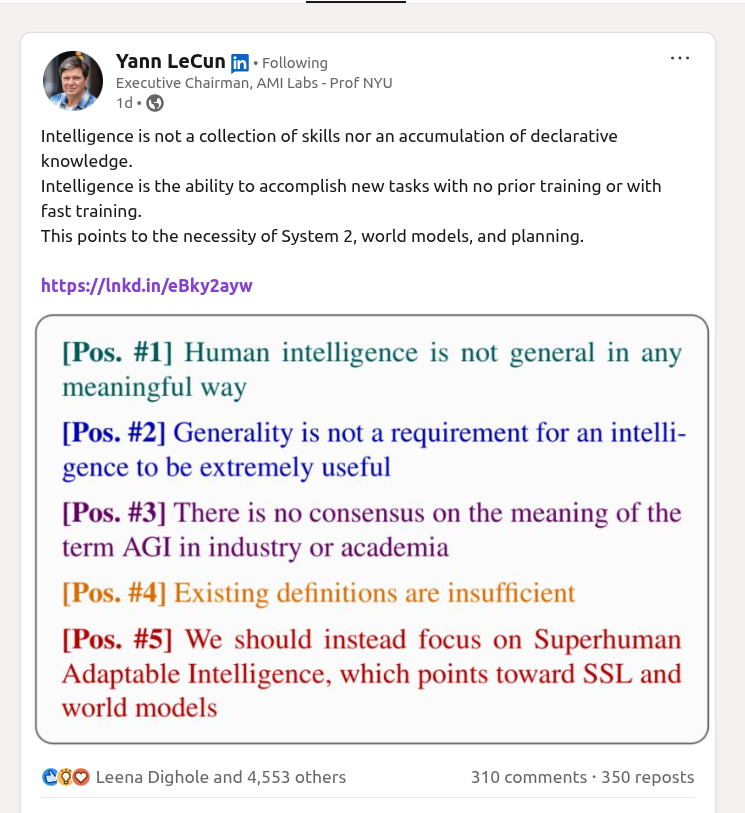
Yann LeCun defines Intelligence
"Intelligence is not a collection of skills nor an accumulation of declarative knowledge.
Intelligence is the ability to accomplish new tasks with no prior training or with fast training.
This points to the necessity of System 2, world models, and planning."
Yann LeCun's (@ylecun ) new paper along with other top researchers proposes a brilliant idea. 🎯
Says that chasing general AI is a mistake and we must build superhuman adaptable specialists instead.
The whole AI industry is obsessed with building machines that can do absolutely everything humans can do.
But this goal is fundamentally flawed because humans are actually highly specialized creatures optimized only for physical survival.
Instead of trying to force one giant model to master every possible task from folding laundry to predicting protein structures, they suggest building expert systems that learn generic knowledge through self-supervised methods.
By using internal world models to understand how things work, these specialized systems can quickly adapt to solve complex problems that human brains simply cannot handle.
This shift means we can stop wasting computing power on human traits and focus on building diverse tools that actually solve hard real-world problems.
So overall the researchers here propose a new target called Superhuman Adaptable Intelligence which focuses strictly on how fast a system learns new skills.
The paper explicitly argues that evolution shaped human intelligence strictly as a specialized tool for physical survival.
The researchers state that nature optimized our brains specifically for tasks necessary to stay alive in the physical world.
They explain that abilities like walking or seeing seem incredibly general to us only because they are absolutely critical for our existence.
The authors point out that humans are actually terrible at cognitive tasks outside this evolutionary comfort zone, like calculating massive mathematical probabilities.
The study highlights how a chess grandmaster only looks intelligent compared to other humans, while modern computers easily crush those human limits.
This proves their central point that humanity suffers from an illusion of generality simply because we cannot perceive our own biological blind spots.
They conclude that building machines to mimic this narrow human survival toolkit is a deeply flawed way to create advanced technology.