MMLU is saturated. HLE is getting there.
We built Multimodal STEM HLE++: for what comes next, and the top frontier labs publishing SOTA models are already using it.
1,100 PhD-level multimodal STEM problems that break Opus 4.6. Around 20% pass@1 on SOTA. Hard enough to expose reasoning failures. Solvable enough to generate real RL signal.
Every problem requires joint reasoning over images and text, has a deterministic ground-truth answer, and was authored by a PhD-level domain specialist.
50-task public sample on @HuggingFace.
Full pack available now. Links below.
The models are already extraordinary.
That's not the hard part anymore.
The hard part is letting them touch reality.
Real workflows. Real data. Real stakes.
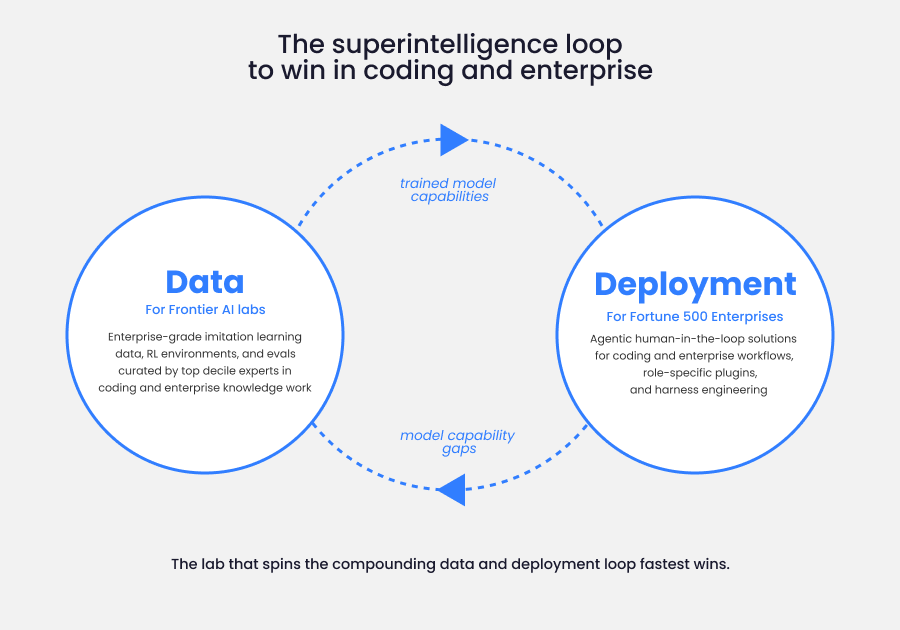
The next decade belongs to whoever solves deployment, not whoever builds the best benchmark score.
I've been making that bet for seven years.
I'm more convinced than ever. Link below.
Who's actually building AI?
3 months and 14 episodes into This Week in AI, @Jason has sat down with founders and operators across infra, models, dev tools, consumer, creative, robotics, healthcare, and more.
INFRA & COMPUTE
Chase Lochmiller (Crusoe) @ChaseLochmiller
Lin Qiao (Fireworks AI) @lqiao
Chris Lattner (Modular) @clattner_llvm
Nick Harris (Lightmatter) @theanalognick
Mitesh Agrawal (Positron AI) @mitesh711
Alex Cheema (EXO Labs) @alexocheema
Philip Johnston (Starcloud) @PhilipJohnston
Naveen Rao (Unconventional AI) @NaveenGRao
Russ d'Sa (LiveKit) @dsa
FOUNDATION MODELS & RESEARCH
Kanjun Qiu (Imbue) @kanjun
Carina Hong (Axiom Math) @CarinaLHong
Jeremy Fraenkel (Fundamental) @fraenkelj
EVALS & BENCHMARKS
Anastasios Angelopoulos (Arena) @ml_angelopoulos
DEV TOOLS, CODING & AUTOMATION
Karri Saarinen (Linear) @karrisaarinen
Matan Grinberg (Factory) @matanSF
Spiros Xanthos (Resolve AI) @spirosx
Wade Foster (Zapier) @wadefoster
CONSUMER & SEARCH
Aravind Srinivas (Perplexity) @AravSrinivas
Richard Socher (youdotcom & Recursive) @RichardSocher
Tanay Kothari (Wispr Flow) @tankots
Steven Berlin Johnson (NotebookLM) @stevenbjohnson
CREATIVE & MEDIA
Demi Guo (Pika) @demi_guo_
Victor Riparbelli (Synthesia) @vriparbelli
Mikey Shulman (Suno) @MikeyShulman
Grant Lee (Gamma) @thisisgrantlee
ROBOTICS
Jake Loosararian (Gecko Robotics) @jakeloosy
Boris Sofman (Bedrock Robotics) @bsofman
HEALTHCARE
Shiv Rao (Abridge) @ShivdevRao
Trey Holterman (Tennr) @TreyHolterman
ENTERPRISE, VERTICAL & DATA
George Sivulka (Hebbia) @gsivulka
Kashif Ali (TaxGPT) @ChKashifAli
Alex Elias (Qloo) @ape
TALENT & WORKFORCE
Ali Ansari (micro1) @aliansarinik
Jonathan Siddharth (Turing) @jonsidd
Thank you all for joining!
Episode 14 out now: https://t.co/oaDPn5WfT8
Last week we released the Open MM-RL Dataset.
A PhD-level multimodal STEM benchmark built for verifiable reasoning across physics, chemistry, biology, and math. Four STEM domains, one dataset
-Physics: Quantum and Particle Physics, Condensed Matter and Materials, Electromagnetism, Photonics, and Plasma Systems, Astrophysics and Space Physics
-Mathematics: Algebra and Structure, Discrete Mathematics, Analysis and Continuous Mathematics, Probability and Geometry
-Biology: Evolutionary Systems, Molecular Mechanisms, Cellular Processes and Neural Biology
-Chemistry: Chemical Structure, Reaction Mechanisms, Synthesis, Spectroscopy and Properties
The bar is raised. Download below.
Open MM-RL Dataset is trending on @huggingface.
We built something I've wanted for a long time.
- PhD-level STEM reasoning across physics, math, biology & chemistry
- 100% verifiable, auto-gradable answers
- Single-image, multi-panel & multi-image formats
- Two-round expert review on every problem
- RL-ready reward structure out of the box
Most multimodal dataset test perception. This one tests reasoning. The kind that doesn't break under scrutiny.
Built by PhD SMEs.
Validated for frontier models.
Open to the community.
Website & Dataset below.
Most browser agent benchmarks are already solved.
We built ones that aren't.
500+ tasks. 100+ templates. 50%+ model-breaking difficulty at delivery. Full case study → Below.
Open-MM-RL is trending at #3 on @huggingface!
This is a strong signal that the community wants harder, cleaner datasets for frontier model evaluation, training and a sign that the community is actively looking for datasets that make multimodal evaluation more rigorous.
Take a look, tell us what you think, below.
Introducing the Open MM-RL Dataset.
A PhD-level multimodal STEM benchmark built for verifiable reasoning across physics, chemistry, biology, and math.
Four STEM domains, one dataset
-Physics: Quantum and Particle Physics, Condensed Matter and Materials, Electromagnetism, Photonics, and Plasma Systems, Astrophysics and Space Physics
-Mathematics: Algebra and Structure, Discrete Mathematics, Analysis and Continuous Mathematics, Probability and Geometry
-Biology: Evolutionary Systems, Molecular Mechanisms, Cellular Processes and Neural Biology
-Chemistry: Chemical Structure, Reaction Mechanisms, Synthesis, Spectroscopy and Properties
We're raising the bar.
Most AI systems break when documents stop being clean and predictable.
We built a dataset to fix that:
• 15,000+ OCR, summarization, and translation tasks
• 10+ document types (handwriting, scans, financial reports, more)
• 10+ languages
• 95%+ summarization accuracy
The hard part wasn't scale. It was realism.
Multi-page docs. Rotated text. Tables, math, and messy layouts. Strict no-hallucination summaries.
Plus a multi-layer QA system combining automated review and human validation to catch even subtle errors.
This is what it takes to train AI for real-world document understanding. Full case study below.