🎉 We’re excited to share our intent to acquire @Immerokcom!
Together, we’ll build a cloud-native service for @apacheflink that delivers the same simplicity, security, & scalability that you expect from Confluent for Kafka.
Learn more → https://t.co/49h9maz1pT
I finally started my engineering blog on Medium about what we build at @ConfluentInc. @ApacheFlink and #FlinkSQL at the core, a ton of abstractions around it for more productivity.
Let me start simple by creating some tables ✌🏻
https://t.co/makiy5Rppf
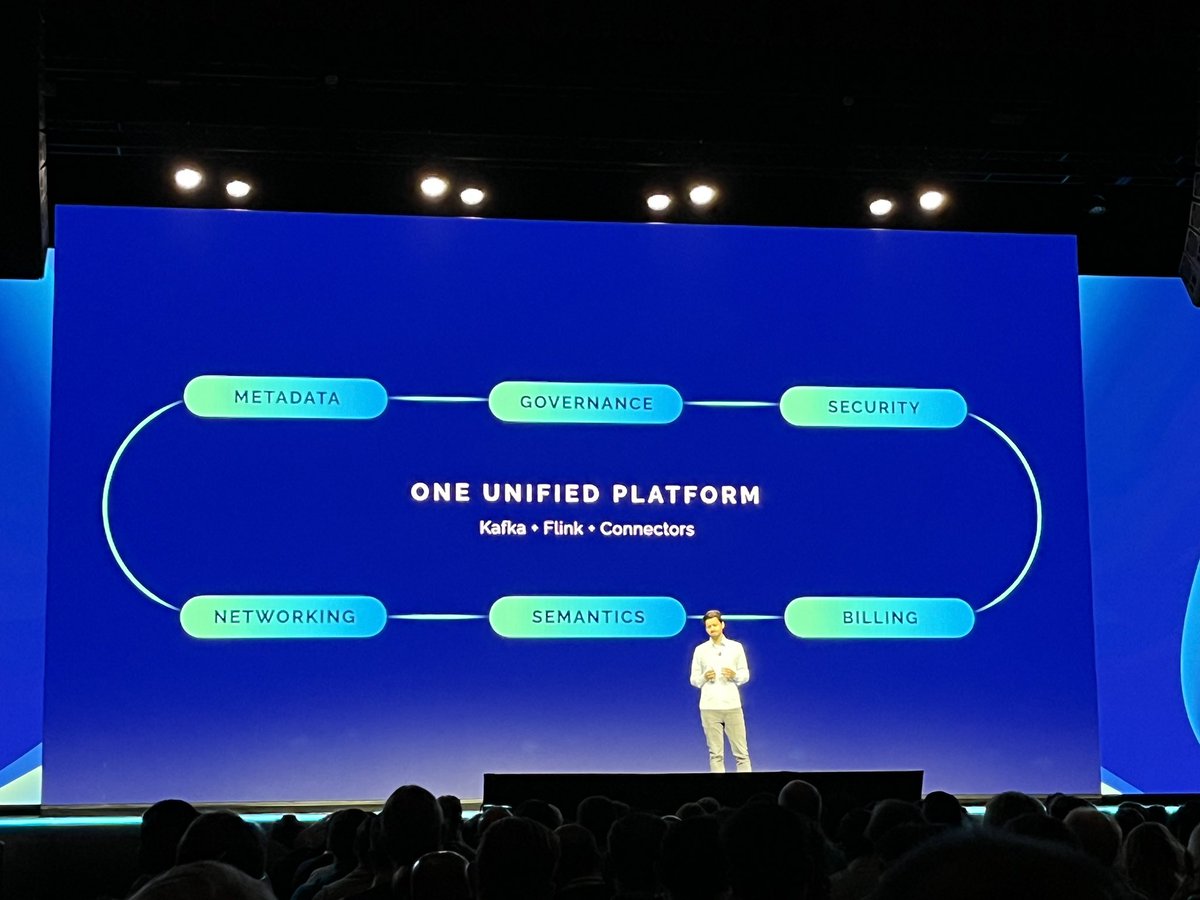
🧨 The first cloud-native @ApacheFlink offering for all major clouds is now generally available 🥳
Creating real-time production pipelines will become easier every day across #AWS, #Azure and #GCP 🌤️. Strongly coupled with #ApacheKafka in @ConfluentInc Cloud💪
Today is a very special day for me 🥲 - celebrating my 10-year @ApacheFlink anniversary 🐿️
Ten years ago, I made my first commit.
Thanks to everyone who has accompanied me on this journey! Impossible to list all the great people that were part of it ❤️
https://t.co/5eybycpC57
Hey @ApacheFlink people, little reminder: The CfP for #KafkaSummitLondon2024 will close today! This time with a dedicated track for non-Kafka talks:
https://t.co/eBeR7YOr77
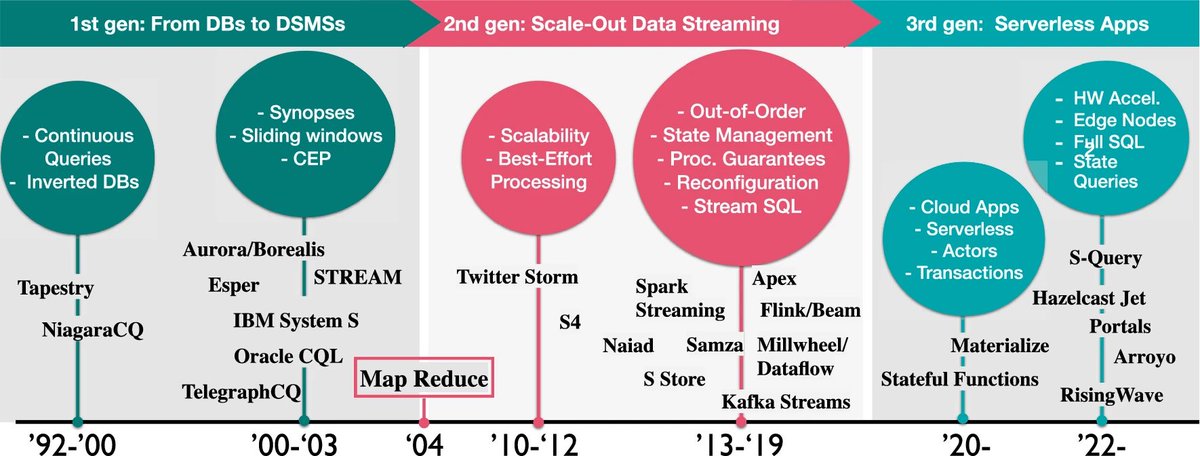
Took >3 years with @MarioFragkoulis, @SenorCarbone & @vkalavri to write a survey on the evolution of streaming systems in the last 20 years (@VLDBconf J.).
Looking for a single point of reference for all things streaming systems research? It’s here:
https://t.co/YwGD9ZZPCa
🐿️ #FlinkSQL will get new syntax in the CREATE TABLE statement.
The @ApacheFlink community just approved the new DISTRIBUTED BY clause. Connectors that support the concept of bucketing can use this starting with Flink 1.19.
https://t.co/NI86tho7II
Flying back home from #Current23
What an inspiring event, full of great people, talks and projects. 😍
We also did a short trip to Lake Tahoe with @twalthr. The Desolation Wilderness is just mind-blowing. One of the most beautiful places I’ve been to so far. 🤯
I haven‘t posted much lately, but now you might understand: We were busy building a #cloudnative@ApacheFlink service 🙂
Try it out NOW! 🐿️
#Current23
https://t.co/8DVW2rDTYQ
⚡ Don’t miss @ApacheFlink Power Hour at #Current23! ⚡
Join us on 9/26 at 4:00 PM PT for 3 back-to-back talks
1️⃣ The Flink Table API with @twalthr
2️⃣ An Overview of Flink SQL Joins with @alpinegizmo
3️⃣ The AdaptiveScheduler, a New Default for Streaming with @davidmoravek
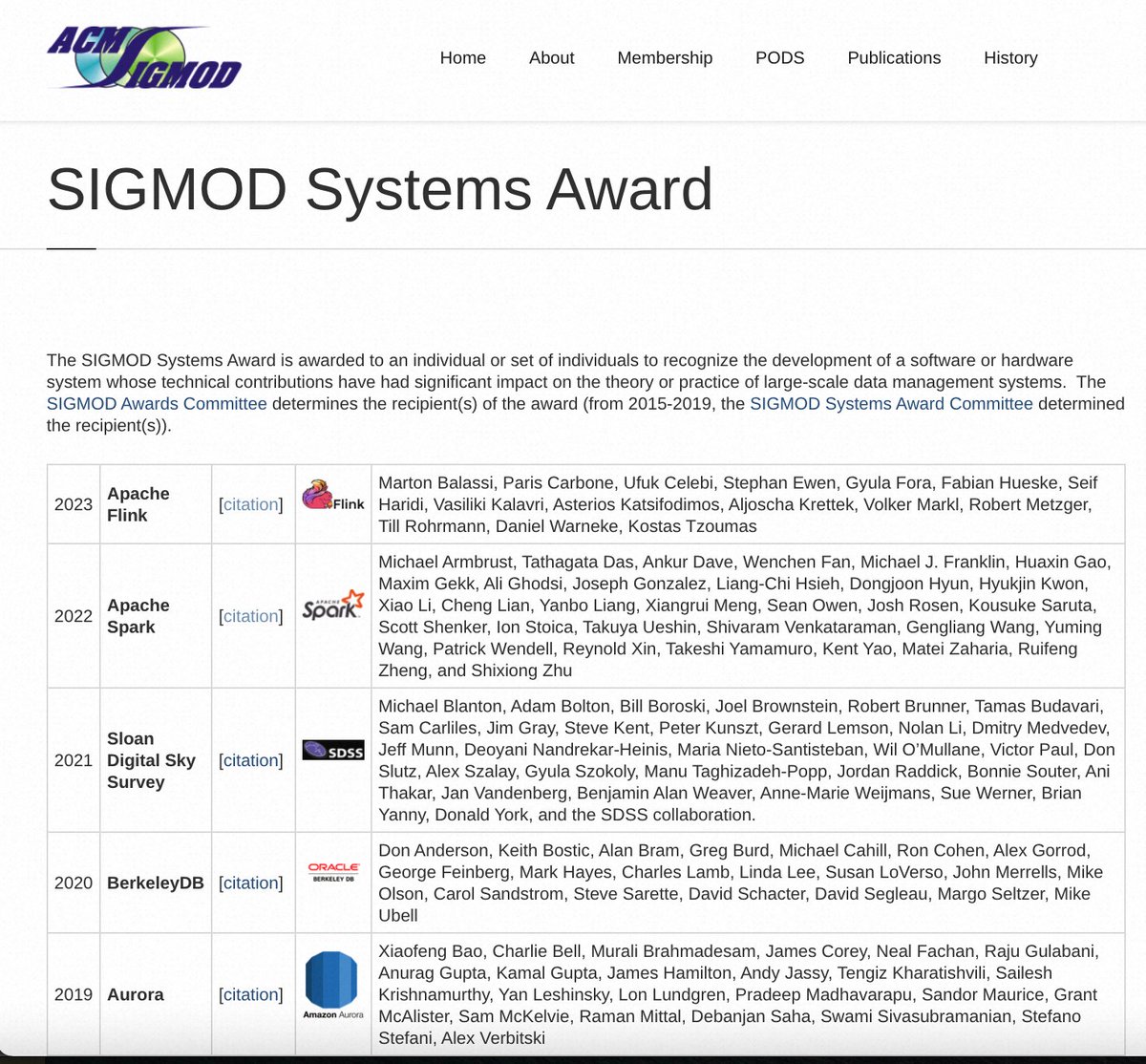
#ApacheFlink has won the 2023 SIGMOD Systems Award!!
"Apache Flink greatly expanded the use of stream data-processing."
Thanks the over 1,400 contributors and many others who contributed in ways beyond code.
https://t.co/V7XEsku5jf
@ApacheCalcite upgrade story in @ApacheFlink being continued.
In Flink 1.17.x there were 1.27✅, 1.28✅, 1.29✅.
In coming 1.18.x #FlinkSQL there will be another major upgrade: 1.30✅, 1.31✅, 1.32⏳...
Feedback is highly appreciated if we unintentionally broke something. 🙏
The #SQL standard might be an old lady, but the diff for SQL:2023 shows how active the industry is.
Very nice blog post by @petereisentraut:
https://t.co/z5PqHfdDUo
People working with #Data might know how valuable this is: @ApacheFlink receives the @SIGMOD Systems Award 2023! 🥳
It's an honor to be part of of this amazing community for so many years. Thanks to all the individuals who have dedicated their time to this project! 👏🐿️