most of my conversations is entirely talking in terms of types and interfaces
i just keep doing full iterations of these until i can't find any more holes to poke
and i trust the agent to implement at that point
it's not done if it's not implemented
it's not done if the implementation is ugly
it's not done if it's not documented
it's not done if users can't discover it
it's not done if you can't market it
Fable is a good model. As with all new models, it is simultaneously excellent and entirely unremarkable (relative to other models). It is slow and expensive, and the "loops are all you need" discourse they are pushing is obvious in the context of someone using Fable-class models
What I've found so far is that for broad scope design (code architecture) tasks, Fable is unremarkable. Or, not better enough to justify its cost and speed.
But in highly targeted goal-oriented loops, it is another beast entirely. It is very slow but produces very good results.
I let it churn on optimizing a SwiftUI-layout resolver in Go I wrote and it was able to bring it down to an order of magnitude I could not reach myself (micro => nanosecond scale). But it took 2 hours and $40 to do it and I had to claw back some changes it overfit to Apple Silicon. Still, very worth it.
In comparison, for "implement this feature/change" iterative work, I ran head-to-head Fable vs GPT5.5 vs. GLM-5.1. They all produced equally acceptable final results, but GPT5/GLM did it in a couple minutes and Fable was churning away for 40 minutes. And GLM cost me less than a dollar, GPT5.5 ~$1.50, and Fable cost $9.
You can see that in this context, interactively working with an agent is nonsense. Its too slow. You need to write loops to keep the agent working and you probably want to highly parallelize the work being done. As with all things, I think a balance makes sense...
My sense is that I'd reserve Fable for targeted, surgical analysis and work. Not for daily driving everyday tasks.
I'm going to keep spending a shitload of money (relatively) and maining Fable for the rest of the week to continue to judge, will report if anything changes. I'll continue to head-to-head as well.
You're right regarding debugging. Tangentially, Nancy Leveson (Engineering a Safer World) demonstrated that software can behave differently under different contexts. Ariane 4 software was good enough for Ariane 4 rockets but not Ariane 5 (and humans botched the port). The overflows in the code, by definition, didn't apply to Ariane 4 rockets the way the applied to Ariane 5
I have to push back on 2 things as i think one is categorically incorrect and the other is demonstrably incorrect.
1. Debugging:
Debugging is not a thing if coding is solved. You would produce correct behaviors. I don't understand how a solved problem could produce erroneous behavior.
2. Coding is the easy part:
setting hardware, capacity, talking to users, product planning agreed is in fact hard, but so is coding.
Example: If coding was in fact not hard then Claude Code having a flickering issue for well over 9 months, which is a purely software challenge, would have been solved almost immediately (immediately being on a shortened time scale comparatively to a human solve time scale).
For more trivial applications software approximation can largely work. I also love software approximation for exploring how things should feel.
TIL Plan 9 doesnt actually support _recursive_ unions! you can only union one dir at a time. because i _thought_ they were recursive, that's how wanix does unions, enabling overlayfs style layered filesystems. just bind multiple trees on top of each other
Side note: @davis7 got me Discord-pilled for OpenClaw/hermes and it’s so much better.
1 thread per “request” is so much easier to manage and maps to my brain much better
I'm really upset about this: OpenAI's Codex Desktop had a "Copy as Markdown" option for exporting full chat transcripts, but the feature vanished in an update a couple of days ago
Genuinely my single favorite feature of Codex compared to Claude Code
https://t.co/nk3yiPXHxL
@davidcrawshaw That’s because people like you are interested in the results. For every one of you there’s more that are just tabbing over to YouTube or scrolling their phone and turning their brains off
I don't know who these people are or who they represent, but they're sniffing around trying to learn about me behind my back. Lots of people I've worked with have been pinging me. Don't know what they're up to, but if you get one go ahead and tell them I'm fucking awful. Thanks.
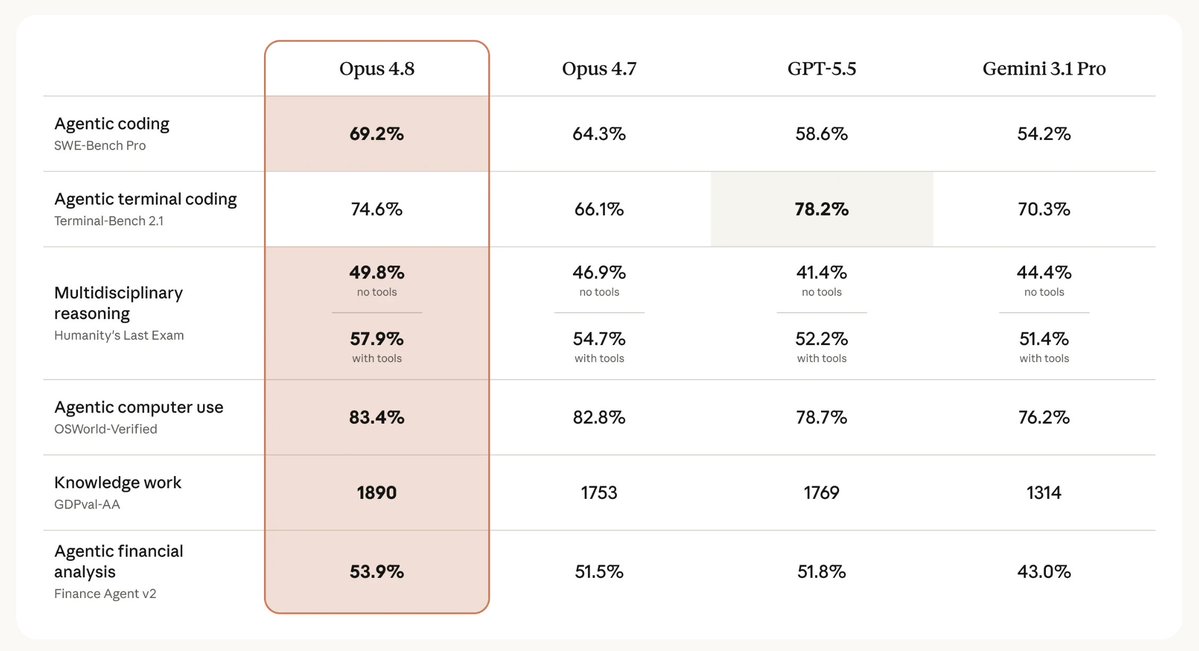
Anthropic did a big strategic error. Normally they compare their models with their old models. Instead today, now that everybody knows how strong GPT 5.5 is at coding, they put it in the mix, basically showing all their customers that the benchmarks can't be trusted.