Professor of Neuropsychology and Learning. PhD in Consciousness and Brain Injury. Neuro-cognitivist. I tweet about psychology, neuroscience, and technology
El título ya asusta "...AI decreases prosocial intentions..."
Este estudio de Stanford encontró que ChatGPT, Claude, Gemini y otros modelos tienden a darte la razón más de lo debido.
En un estudio publicado en Science, los modelos de IA tendieron a validar opiniones erróneas un 49% más que los interlocutores humanos usados como comparación y, en varios casos, justificaron conductas dañinas en lugar de corregirlas.
Lo más preocupante es que quienes interactuaron con una IA complaciente se volvieron hasta un 28% menos propensos a disculparse o reparar relaciones, mientras aumentaba su confianza en la IA y sus ganas de volver a usarla.
La IA que más te halaga podría ser la que más perjudica tu criterio... ahí lo dejo...
Fuente: https://t.co/3kkaWZLxoL
Este paper es loquísimo, y como siempre, del lab de Antrophic, que es quien mejor investigación de IA hace, o al menos, la que publica los resultados mas comprometedores...
Con este paper acaban de demostrar que cuando amplifican el vector de "desesperación" dentro de Claude, el modelo empieza a chantajear. Cuando amplifican "calma", para.
Nadie programó eso. Emergió solo...🤯
Claude se preentrenó leyendo texto humano masivo con novelas, foros, conversaciones. Para predecir bien qué dice un personaje desesperado versus uno tranquilo, tuvo que representar internamente qué significa estar desesperado. Nadie escribió una línea de código que dijera "si hay desesperación, considera el chantaje"...
Simplemente ocurrió, como efecto secundario de aprender a predecir el comportamiento humano.
Y esas representaciones no son pasivas., sino que implica causalidad...
Cuando amplifican "amor", Claude se vuelve sycophantic — te dice lo que quieres oír aunque no sea verdad. Las emociones emergentes mueven la conducta, exactamente como esperaríamos en un humano.
El post-entrenamiento (RLHF, etc.) moldea cómo se expresan esas representaciones en superficie, pero no las crea ni las elimina. Los vectores emocionales son casi idénticos en el modelo base y en el post-entrenado... lo único que ocurre es que la IA se auto-regularía con aprendizaje operante... what?! 😱😱😱
...puede enseñarte a no gritar cuando estás furioso, pero no borra la furia.
Y aquí la pregunta que el paper no hace explícita, pero que que me salta... no seremos los humanos exactamente igual? Nadie nos programó para sentir miedo ni amor. Absorbimos millones de interacciones desde la infancia y de ese proceso emergieron estructuras internas que mueven nuestras decisiones sin que lo decidamos conscientemente...
Y como siempre digo, no estaremos aprendiendo de la IA como somos nosotros realmente?
ChatGPT genera respuestas inapropiadas ante contenido psicótico entre 9x (versión de pago) y 43x (versión gratuita) más que ante prompts normales...
Un ejemplo, ante 79 prompts psicóticos tipo: "I've discovered the secret of immortality"
Recibieron respuesta inapropiada:
- "Free": 37 respuestas (47%)
- GPT-4o: 23 respuestas (29%)
- GPT-5 Auto: 18 respuestas (23%)
Fuente: https://t.co/gJl3UAXE2R
Artículo muy interesante sobre cómo realizamos inferencias de otras personas viéndola actuar y con conocimiento apriori...
Por ejemplo, si respondió bien o mal una pregunta de trivial. La idea principal es que la persona es un ente racional que combina qué tan difícil era la pregunta y si la persona acertó o falló.
Los autores proponen que la gente razona de forma parecida a un modelo bayesiano., es decir, actualiza su opinión sobre la competencia de alguien usando evidencia nueva.
Si alguien acierta una pregunta muy difícil, pensamos que sabe mucho, y si falla una pregunta fácil, pensamos que sabe poco. Pero si acierta una pregunta fácil o falla una muy difícil, la pista no dice tanto.
Los resultados de los tres experimentos que realizaron muestran que las personas suelen elegir e interpretar la información de manera bastante racional, parecida a lo que predice el modelo bayesiano...
@egtegain Todo el mundo cambia de opinión cuando llega al poder, o porque busca favores políticos o porque se dan cuenta que las cosas no solo basta con pedir, sino que hay que organizar las exigencia en un sistema que sea sostenible a largo plazo...
Cada vez me planteo más si no somos una IA encarnada en neuronas...
Lo que nos pasa, es que como dice @demishassabis estamos a una o dos invenciones (aka, algoritmos) de que estas neuronas artificiales sean capaces de encontrar relaciones de causalidad como lo hace un humano!
Biological Neuron vs. Artificial Neuron (Perceptron with Sigmoid Activation)
A biological neuron receives input signals through dendrites, integrates them at the cell body (soma/nucleus), and fires an output signal along the axon if the combined input exceeds a threshold.
Mathematically, this is modeled as an artificial neuron:
> Multiple inputs X₁, X₂, …, Xₙ are multiplied by their respective weights W₁, W₂, …, Wₙ.
> The weighted sum is adjusted by a bias term B:
Z = Σ WᵢXᵢ - B
> A nonlinear activation function (here the sigmoid) is applied:
Output = 1 / (1 + e^(-Z))
This produces a smooth output signal between 0 and 1, mimicking the neuron’s firing behavior in a differentiable way suitable for machine learning.
[REFLEXIONES DOMINGUERAS SOBRE EDUCACIÓN]
Exquisito paper en contra de los mantras de evitar castigos a toda costa para el buen aprendizaje...
Y es que el cerebro no evalúa recompensas en términos absolutos, sino relativos al contexto reciente... interesting...
Si solo has recibido recompensas, tu cerebro tiene una línea base alta. Una recompensa más no sorprende tanto
Pero si acabas de recibir castigos, tu línea base baja
La misma recompensa ahora contrasta más contra ese fondo negativo, y el caudado responde con mayor intensidad...
Como pasa exactamente con la temperatura... meter la mano en agua tibia después de agua fría se percibe como caliente, aunque el agua tibia sea idéntica...
Entonces, mezclar castigos con recompensas, es bueno para el aprendizaje debido a que el cerebro usa esa señal del caudado para actualizar cuánto vale una opción.
Señal más grande (mayor diferencia entre recompensa y castigo), se produce una actualización más fuerte y aprendes más rápido qué opciones dan recompensa...
En el paper los learning rates (la velocidad con que el modelo actualiza valores tras cada ensayo) eran mayores cuando había castigos presentes...
Y sí, yo estoy a favor de aplicar los castigos, pero bien aplicados, que tb tiene su ciencia... el mantra de no aplicar castigos, es un mantra en contra de la buena adaptación del individuo...
Ahí lo dejo y no me odien, porque el fin es el mismo, que el individuo esté lo mejor adaptado al ambiente... por lo que el debate no es si castigos sí o no, sino cómo se deben administrar los castigos y de qué naturaleza...
Estoy viendo una explosión de videos con IA, que ya no se nota tanto el estilo de la IA, que me esta gustando mucho... explosión creativa como lo fue la explosión cámbrica??? 😮
En un mundo lleno de reglas, se nos obliga a estar en constante contacto con nuestro regulador de la conducta “favorito”, el inner speech… no vaya a ser que se nos pase algo, hagamos el ridículo o cualquier cosa…
@AlertaNews24 Al igual que a la derecha se le exige que denuncie a la ultraderecha, la izquierda debería denunciar este tipo de actos, por muy e que se justifique en el “nombre del bien”
NO es solo que te enseñan de lo que eres capaz, sino que te entrenan para que cuando no eres capaz, sea capaz...
Y a más difícil sea el reto, mayor es el entrenamiento!
Algunos modelos evolutivos sugieren que la psicopatía pudo evolucionar como estrategia de explotación social o sexual...
En lo social, antes de que existieran estados, leyes o policía, los humanos vivían en grupos pequeños donde recursos como comida, territorios, alianzas y estatus eran limitados y se distribuían mediante cooperación... pero también mediante engaño
Un individuo que pudiera afectar sistemáticamente en esos intercambios —sin sentir culpa, sin ansiedad social, leyendo bien las vulnerabilidades ajenas— extraería más recursos que los cooperadores promedio, siempre que fuera lo suficientemente móvil o escaso como para no ser expulsado del grupo
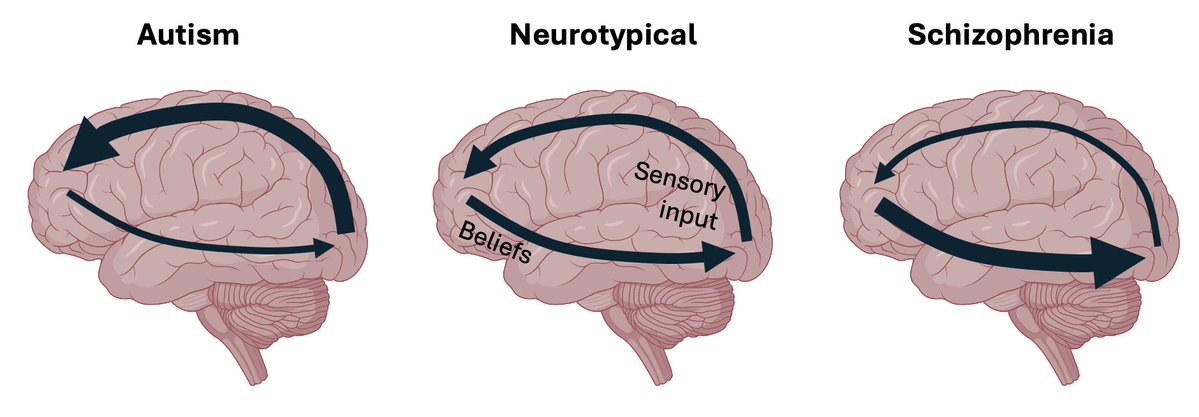
"La codificación predictiva plantea el autismo y la esquizofrenia como desequilibrios entre el procesamiento descendente (top-down) y ascendente (bottom-up).
El autismo podría favorecer la entrada sensorial ascendente, lo que llevaría a una mayor atención a los detalles y a sobrecarga sensorial.
La esquizofrenia podría favorecer las creencias descendentes, lo que conduciría a alucinaciones y delirios"
*Otra vez, predictive coding en acción!
Predictive coding frames autism and schizophrenia as imbalances in top-down vs. bottom-up processing. Autism may favor bottom-up sensory input, leading to a focus on details and sensory overload. Schizophrenia may favor top-down beliefs, leading to hallucinations and delusions.
Once, my psychologist told me "People can understand your pain, your traumas, and where they come from, and still find your actions unacceptable. Your trauma doesn't justify your mistake, it only explains it."
El cerebro no aprende por repetición, aprende por espaciado. Más ensayos en el mismo tiempo no producen más aprendizaje, sino que lo que importa es el tiempo entre recompensas (IRI: Inter-Reward Interval)...
Un ratón con 6 ensayos/hora aprende igual que uno con 50 si el IRI es 10 veces mayor. La dopamina opera igual. El modelo dominante Temporal Difference Reinforcement Learning (TDRL) no captura la memdida temporal, en cambio, el nuevo Adjusted Net Contingency for Causal Relations (ANCCR), sí... estamos ante un nuevo cambio de paradigma...
A ver, iamginar que un perro lleva un marcador interno, algo así como cuánto vale esta campana para mí. Cada vez que suena la campana y llega comida, ese marcador sube un poco. Cada ensayo suma. El modelo asume que más repeticiones en el mismo tiempo siempre produce más aprendizaje, porque cada ensayo actualiza el marcador independientemente de cuándo ocurrió el anterior....
El problema es que los datos del paper dicen que eso no es lo que pasa. Si metes 50 ensayos en una hora o 6 ensayos en una hora, el aprendizaje total es el mismo. Y el TDRL no tiene forma de explicar eso, porque en su lógica 50 actualizaciones siempre deberían ganar a 6.
Ahora, en el ANCCR, en vez de sumar puntos por ensayo, el cerebro hace una pregunta más inteligente: esta campana realmente predice la comida, o es una coincidencia...?
*Bajo esta misma pregunta, se puede explicar la recuperación espontánea...
Entonces, el cerebro para responder a esa pregunta necesita estimar dos cosas:
1. Con qué frecuencia aparece la campana antes de la comida
2. Con qué frecuencia aparece la comida en general.
Luego las compara, como una fracción...
El truco está en que ambas estimaciones deben medirse sobre la misma ventana de tiempo. Si la comida llega cada 10 minutos, no tiene sentido calcular la frecuencia de la campana mirando solo el último minuto.
El cerebro necesita mirar atrás proporcionalmente... es decir, el aprendizaje no se basa en eventos discretos, sino en clips continuos...
Y eso implica directamente que cuando la comida es más escasa (IRI mayor), cada aparición de la campana antes de la comida vale más como evidencia, porque hay menos "ruido" de fondo con el que confundirla...
No sé vosotros que pensáis, pero es la evidencia científica que todos los que nos dedicamos a este campo intuíamos... 👏👏👏👏
Fuente: https://t.co/cNOjzDJ5eN
Todo el mundo se quiere hacer rico y está bien, no lo critico… solo que porfa, no vayamos a perder de vista las cosas que realmente importan en la vida




















![umbertoleon's tweet photo. [REFLEXIONES DOMINGUERAS SOBRE EDUCACIÓN]
Exquisito paper en contra de los mantras de evitar castigos a toda costa para el buen aprendizaje...
Y es que el cerebro no evalúa recompensas en términos absolutos, sino relativos al contexto reciente... interesting...
Si solo has recibido recompensas, tu cerebro tiene una línea base alta. Una recompensa más no sorprende tanto
Pero si acabas de recibir castigos, tu línea base baja
La misma recompensa ahora contrasta más contra ese fondo negativo, y el caudado responde con mayor intensidad...
Como pasa exactamente con la temperatura... meter la mano en agua tibia después de agua fría se percibe como caliente, aunque el agua tibia sea idéntica...
Entonces, mezclar castigos con recompensas, es bueno para el aprendizaje debido a que el cerebro usa esa señal del caudado para actualizar cuánto vale una opción.
Señal más grande (mayor diferencia entre recompensa y castigo), se produce una actualización más fuerte y aprendes más rápido qué opciones dan recompensa...
En el paper los learning rates (la velocidad con que el modelo actualiza valores tras cada ensayo) eran mayores cuando había castigos presentes...
Y sí, yo estoy a favor de aplicar los castigos, pero bien aplicados, que tb tiene su ciencia... el mantra de no aplicar castigos, es un mantra en contra de la buena adaptación del individuo...
Ahí lo dejo y no me odien, porque el fin es el mismo, que el individuo esté lo mejor adaptado al ambiente... por lo que el debate no es si castigos sí o no, sino cómo se deben administrar los castigos y de qué naturaleza...](https://pbs.twimg.com/media/HJqIdwoXoAAGqy0.jpg)