Research Scientist at Google DeepMind, working on Gemini.
(prev. PhD at ETH Zürich & MPI-IS Tübingen.)
No second-hand opinions. They are absolutely my own ;)
📢I'll be presenting two posters, at #ICML2024 HiLD workshop (Straus 2) today (assuming no further ✈️ delays):
- Closed form of the Hessian spectrum for some neural networks https://t.co/qQTWOZUsQw
- Landscaping Linear Mode Connectivity https://t.co/w09UyJ2Wyf
This is Gemini 3: our most intelligent model that helps you learn, build and plan anything.
It comes with state-of-the-art reasoning capabilities, world-leading multimodal understanding, and enables new agentic coding experiences. 🧵
sure the numbers are great, but screw that! it’s your phd, try wild and original ideas even if you fail once or twice at least.
https://t.co/Y1XisXjGXd
A few numbers from my PhD:
8 first-author top-conference (CVPR/ICCV/ECCV) papers
100% acceptance rate per paper
80% acceptance rate per submission
1 invited long talk at CVPR tutorial
5 top-conf demos (acceptance rate 100% vs ~30% average)
~2k GitHub stars
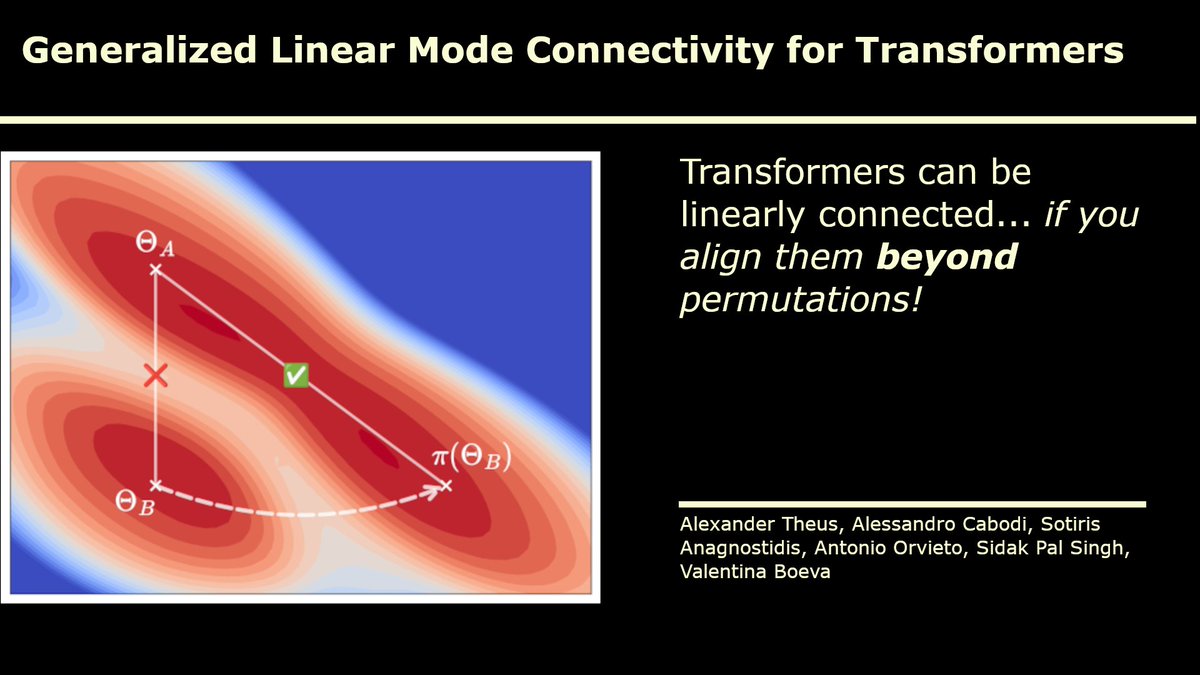
1/ 🚨 New paper alert! 🚨
We explore a key question in deep learning:
Can independently trained Transformers be linearly connected in weight space — without a loss barrier?
Yes — if you uncover their rich symmetries.
📄 arXiv: https://t.co/wVoLYNzk0m
🚀 TOMORROW afternoon at ICLR: Learn about the directionality of optimization trajectories in neural nets and how it inspires a potential way to make LLM pretraining more efficient ♻️
(Poster# 585, hall 2b)
Ever wondered how the optimization trajectories are like when training neural nets & LLMs🤔? Do they contain a lot of twists 💃 and turns, or does the direction largely remain the same🛣️? We explore this in our work for LLMs (upto 12B params) + ResNets on ImageNet.
Key findings👇
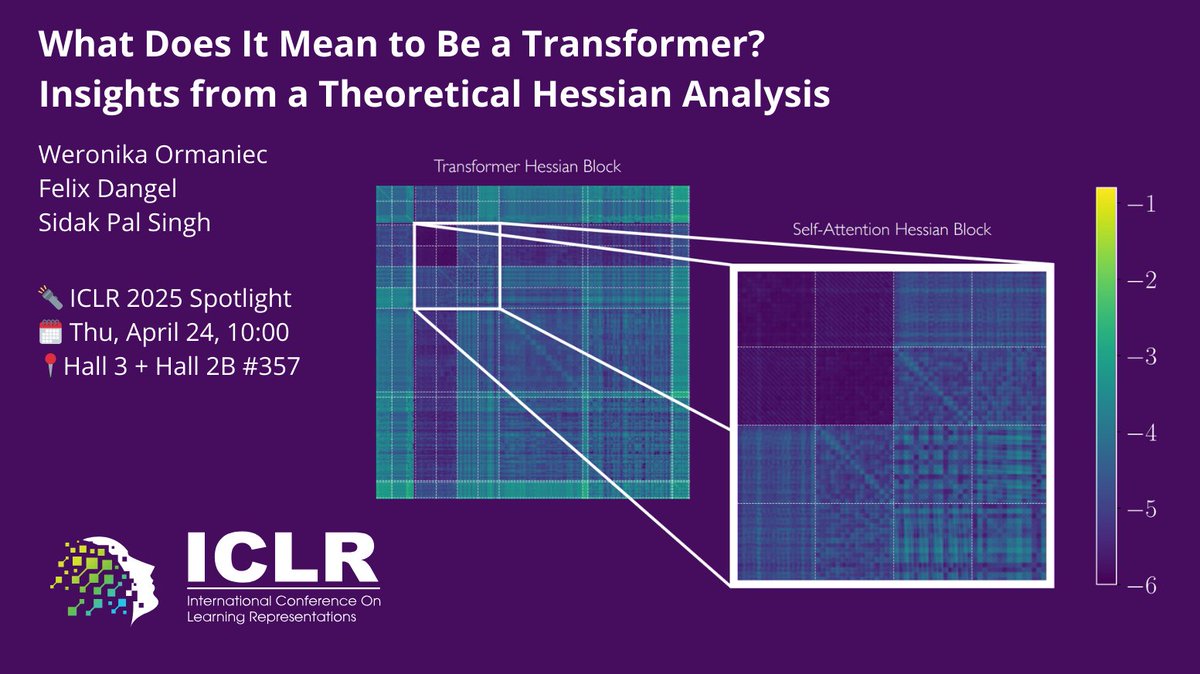
Don't miss out our spotlight ✨paper at ICLR 🇸🇬 about the loss landscape of Transformers and their special heterogeneous structure, done together with great collaborators!
https://t.co/VyQiHGM7CE
Ever wondered how the loss landscape of Transformers differs from that of other architectures? Or which Transformer components make its loss landscape unique?
With @unregularized & @f_dangel, we explore this via the Hessian in our #ICLR2025 spotlight paper!
Key insights👇 1/8
✨New Preprint ✨ Ever thought that reconstructing masked pixels for image representation learning seems sub-optimal?
In our new preprint, we show how masking principal components—rather than raw pixel patches— improves Masked Image Modelling (MIM).
Find out more below 🧵
@mayank98shri@TheGradient@ynd@baharanm The bulk + outliers notion isn't wrong. The key is to understand how sharpness reduction is happening. GN can lead to spurious sharpness reduction; while NME reduces sharpness through adapting the geometry of the model itself. In vision, these ways are balanced, but not for LLMs.
Reinventing things has a bad rep in today's age. But is it really that bad? Maybe it's something to be even cultivated, like selectively?
The second post in this series of blogs is now out. Let's have a deeper look at this overused trope!
https://t.co/BIlzZKepuU
I’m exploring a new form of writing—threads of human curiosity woven through the circuits of AI, crafting reflections that are, in the end, fully machine-generated, yet in a way profoundly human.
https://t.co/zJgGaePdDL
Come, let's scale up the building one floor,
And, layer up the neural networks once more.
Soon our buildings will touch the sky,
And, our computers will bear AGI.
A quaint little hut in the mountains is out of fashion,
Satisfaction has no gradients for backpropagation.
~Fitoor
@kellerjordan0@bozavlado QK params and V params have very different behavior in terms of their curvature. So grouping them together is not ideal. I believe you could still try preconditioning QK params together, and keeping V separate.
📢I'll be presenting two posters, at #ICML2024 HiLD workshop (Straus 2) today (assuming no further ✈️ delays):
- Closed form of the Hessian spectrum for some neural networks https://t.co/qQTWOZUsQw
- Landscaping Linear Mode Connectivity https://t.co/w09UyJ2Wyf
Poster 1: Sharpness/Flatness are much talked about: better minima, Sharpness aware minimization, Edge-of-Stability, and so on. But what really is sharpness? What exactly does it quantify, besides the surface-level definition? How are the eigenvalues and eigenvectors really like?
Poster 2: Linear Mode Connectivity (LMC) is yet another popular feature of neural loss landscapes. But how does LMC arise in the first place? How should the landscape be structured to allow LMC? Are barriers present just at the end, or do they start much early?