HuggingBench (https://t.co/R87BSpfPen) is designed to assist you in discovering the best setup for serving ML models. 🚀 Here is the blog post explaining our journey and what we are trying to achieve 🛠️📈 https://t.co/7xPIKsFEb7
If AI stays closed-source, proprietary and monopolistic like it is now, it will destroy lots of jobs and just make the richest companies richer and more powerful!
If we open it up thanks to open science and open-source, foster competition and decentralization of value and control, it will create many more jobs and economic value than it destroys.
Let’s go!
Only one more day left to grab this awesome book for for free. Perfect read if you want to get deeper understanding of data structures behind the commonly used databases
Our book on "Data Structures for Data-Intensive Applications" co-authored with Stratos Idreos (@HarvardDASlab) and @DennisShasha can be downloaded for free from the publisher for the next few days (until Feb 12): https://t.co/0lsOjSC6hy
#FNT#DataStructures#Textbook#Databases
Are database benchmarks truly relevant today?
In our latest blog, @jrdntgn explores the limitations of database benchmarks and why they might not be the best tool for selecting a database.
🗞️ https://t.co/2KRx2J11BO
Everything is available to non-CMU students:
* Lectures are on Youtube: https://t.co/qnXILcbP2a
* Slides + Notes on course website.
* Project source code on Github.
* Grading with Gradescope (see FAQ ➡️ https://t.co/aw1jPt7cYl)
Yes, I know my mic got screwed up in Lecture #1.
How to efficiently 🚀 run BERT model from @huggingface? How do various BERT variants, such as DistilBERT and RoBERTa, stack up in terms of inference throughput 🥊?
⭐ Check out my latest blog post https://t.co/2sK1p8JfOO
I've just published my new blog post that walks you through optimizing Resnet-50 model: 8X inference throughput with only a few commands!
https://t.co/tfhiwOugin
I've just published my new blog post that walks you through optimizing Resnet-50 model: 8X inference throughput with only a few commands!
https://t.co/tfhiwOugin
Are you using @huggingface models? If so https://t.co/R87BSpfPen might help you find the best model serving setup to increase your inference throughput helping keeping your inference costs low. ⏱️💰
Over the last few months, I've been working with my friends to solve the problem of making ML model serving more efficient.💡. It's still early days, but I am excited to introduce you to HuggingBench https://t.co/R87BSpfPen 🌟
HuggingBench (https://t.co/R87BSpfPen) is designed to assist you in discovering the best setup for serving ML models. 🚀 Here is the blog post explaining our journey and what we are trying to achieve 🛠️📈 https://t.co/7xPIKsFEb7
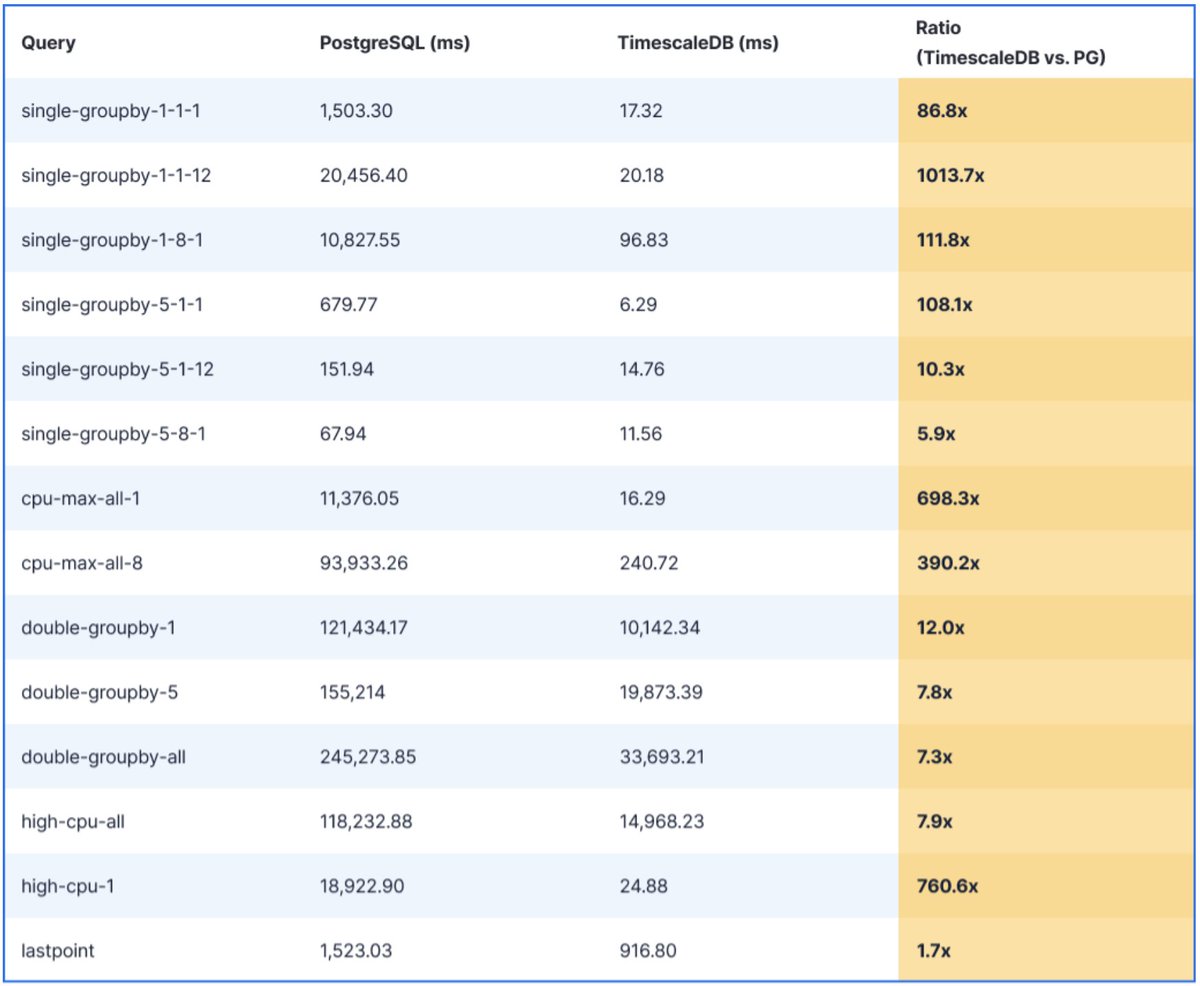
Team recently did detailed benchmarking of @TimescaleDB and #PostgreSQL across a variety of time-series analytical queries (incl. using PostgreSQL declarative partitionsing).
Can really see the performance benefits of TimescaleDB's columnar compression. 🚀
📺 Go scheduler: Implementing language with lightweight concurrency (2019)
This presentation by @dvyukov outlining the problems solved by Go's scheduler is 🔥.
Wonderful slides, explanations and examples!
https://t.co/HQ6UU4Mj8F
What to focus on during a code review? Don't waste your time with automatable formalities like code style. Rather spend your review budget on those aspects which will be hard/expensive to change later on. The "Code Review Pyramid" provides some guidance on what to look for.
💥 BIG NEWS!!!
@TimescaleDB just raised a $110 million Series C at a $1+ billion valuation! 💰💰💰
Round led by Tiger Global, with participation from all our existing investors: @benchmark, @NEA, @Redpoint, @iconventures, and @TwoSigmaVC.
https://t.co/lhAPEgb5IV
🐯🦄🚀💥 1/