The @fastinoAI folks just released GLiGuard, an open-source safety moderation model that remembers encoders are king for these kinds of tasks.
One model, Apache 2.0:
gliguard-LLMGuardrails-300M: 300M params, evaluates multiple safety tasks at a time.
🧵
We’re dropping two open source SLMs this week.
1. One of them matches SOTA accuracy at up to 93x smaller.
2. The other one beats a recent OpenAI model.
Model #1 drops tomorrow 👀
It was a big week for us, with Fastino Labs demoing Pioneer twice at AI Agent Conference.
Our team flew to New York this week to show people firsthand how we're fine-tuning state-of-the-art models with our agent, Pioneer.
At our booth, conversations revolved around the potential of open-source technology and why agentic fine-tuning is the next logical step for task-specific models.
Our co-founder @george_onx ran two live Pioneer demos, walking through how it delivers value not just for ML engineers, but for developers as well.
We also hosted a co-founders dinner for everyone to connect and wind down after a long day.
Here are some of our favorite moments from the conference.
We just published a paper on our autonomous fine-tuning agent. The internet found it before we announced it.
The paper describes the agent that powers Pioneer, our platform that autonomously fine-tunes small language models end-to-end. Pioneer has two operating modes: cold start (you give it a task description, it handles everything) and production (it retrains deployed models using labeled inference failures).
We evaluated cold-start mode across eight benchmarks spanning tasks including reasoning, math, code generation, summarization, classification, and question answering. Fine-tuning performed by the Pioneer Agent improved models by up to +84 percentage points over base. End-to-end runs completed in 8–12 hours at $12–55 per run, demonstrating demonstrating that autonomous fine-tuning can produce high-performing models at minimal cost.
A few cold-start results worth noting:
ARC-Challenge (Llama 3.2 3B): The base model scored 5.3% because it couldn't follow multiple-choice format. Pioneer Agent brought it to 72.6% over 11 iterations. We also discovered that chain-of-thought supervision via DeepSeek-R1 traces was the decisive breakthrough.
HumanEval (Qwen3 8B): When trained on MBPP, the fine-tuned model reached 92.7% pass@1 in just 4 iterations. Interestingly, we found that adding GPT-4.1-generated solutions hurt performance, indicating that external model outputs can dilute the training signal when fine-tuning for basic Python tasks.
SMS Spam (GLiNER2): F1 score on SMS spam classification went from 0.159 to 0.997. The final push from 0.98 to near-perfect required adding just 55 targeted examples to the initial dataset.
To evaluate production mode, we introduce a novel benchmark: AdaptFT-Bench. AdaptFT-Bench evaluates whether an autonomous agent can fix a deployed model's failures without breaking what already works. It simulates production conditions using synthetic inference logs organized into three stages with increasing noise rates (15% → 25% → 40%), mixing fixable noise with poisonous noise like false premises and label flips.
Here are the most notable results from our evaluation of production mode:
TriviaQA (Llama 3.2 3B): Pioneer, the Aagent outperformed naive retraining by 43 percentage points by the final stage, the largest gap across all scenarios.
GSM8K (Qwen3-8B): Pioneer Agent improved the deployed model from 75.9% to 81.2% as noise accumulated, while naive retraining degraded from 71.6% to 64.7%, demonstrating that the agent gets better precisely where naive approaches get worse.
These results demonstrate that the full fine-tuning lifecycle, from task description through production deployment and continuous improvement, can be reliably automated. We also introduce AdaptFT-Bench, a new benchmark for evaluating autonomous model improvement under realistic production conditions.
Link to the paper below.
2022: I built one of the first vibe coding tools.
2026: vibe coding is a $10B+ market.
Today we're launching Pioneer - vibe tuning.
Describe a model. We train it. We evaluate it. We keep improving it.
2030: vibe tuning is a $...... market.
Today, we are launching Pioneer: the world’s first agent for fine-tuning and inferencing SLMs and LLMs.
With Pioneer, you can fine-tune and deploy models like Qwen, Gemma, and Llama and achieve state-of-the-art performance in minutes, with a single prompt. Models are continuously optimized on live inference data, meaning that models in production improve over time.
Additionally, Pioneer is the only platform in the world to offer fine-tuning for small encoder-based language models including GliNER2, offering frontier-model quality on specific tasks at small-model cost and speed.
Start for free at https://t.co/57VlSchQa2.
@Pranav2278 The paper was written in early June 2025, and the repository has changed a lot since then 😁
Do you think it would be worth writing a more complete version that describes the full architecture?
Small models are cheap to run, but expensive to adapt.
The hard part is not only fine-tuning. It is the surrounding loop that involves collecting data, diagnosing failures, building evals, avoiding regressions, choosing curricula, and deciding when an update is safe.
This new paper introduces Pioneer Agent, a closed-loop system for continual improvement of small language models in production.
In cold-start mode, the agent starts from a natural-language task description, acquires data, builds evals, and iteratively trains models. In production mode, it uses labeled failures to diagnose error patterns, synthesize targeted data, and retrain under explicit regression constraints.
The results are strong: gains of 1.6 to 83.8 points across eight cold-start benchmarks, no regressions across seven AdaptFT-Bench scenarios, intent classification from 84.9% to 99.3%, and Entity F1 from 0.345 to 0.810.
Paper: https://t.co/lFkFiXzP8E
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
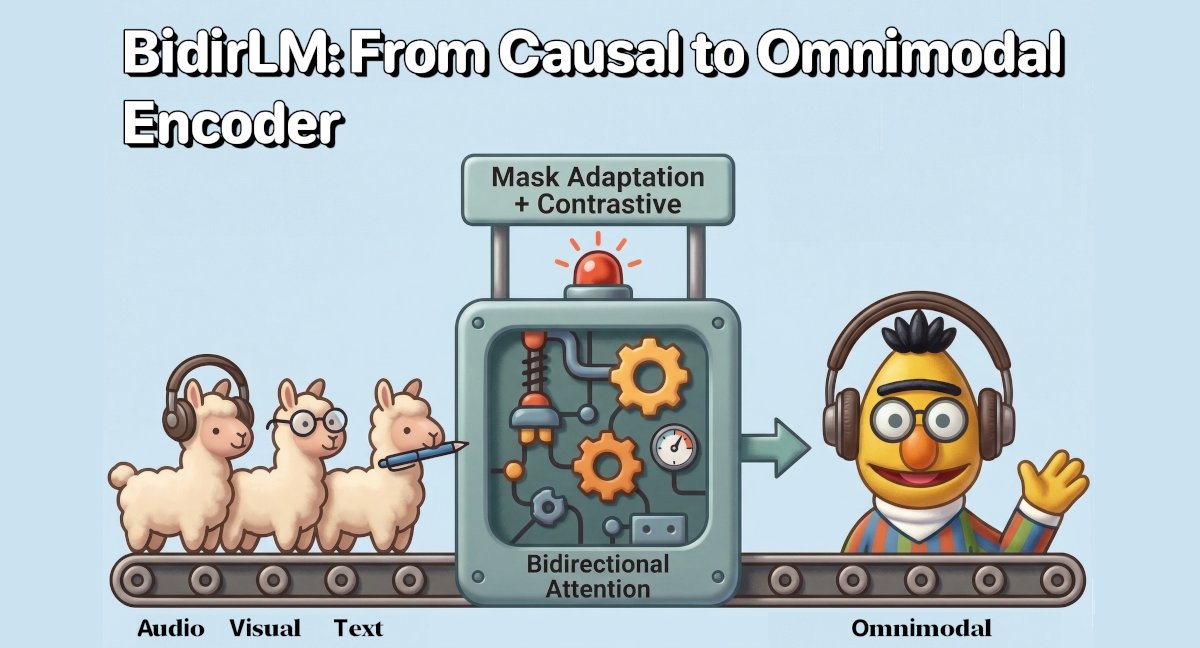
🚀 New model family release with an OMNIMODAL version !
After Eurobert, I'm excited to introduce BidirLM, a family of 5 frontier bidirectional encoders including an OMNIMODAL encoder at just 2.5B parameters.
🧵👇
https://t.co/AZzOJ6ZhhN
🧩 To celebrate yesterday's Sentence Transformers v5.4 release, I went back to update SpanMarker: my Named Entity Recognition project.
It's still a solid, extremely efficient option for NER. Here's how it works and what's new 🧵
Last night at @vercel demo night, we showed something we've been building.
Fine-tuning models for production is brutal. Weeks of iteration, pipelines that break, no guarantee it beats your baseline.
We’re fixing that. To learn more, stop by our booth at HumanX this week.