Introducing your newborn to the world is a feeling every parent knows. That is exactly how I feel today as we unveil @autohealai, the AI for production engineering.
Our mission is to empower engineering teams to build unbreakable customer experiences. @utkarshohm, @puneet_sar, and I believe AI’s true value lies in turning engineers into superheroes especially in production. Production has always been that one SDLC phase where engineering teams feel they have the least control. We are changing that permanently, starting with the production-facing roles of SRE and Support Engineering.
To do this, we are solving the "production trifecta" for the enterprise:
- Production Context Graph
- Security & Governance
- Unified Incident Management
We are building at the frontier of agentic AI while partnering deeply with customers on their AI transformation journeys. Read more here:
https://t.co/apl3rtQHNf
Shoutout to @airindia staff Sumit Tarun and sahir for going out of their way and hustling with multiple agencies to retrieve my phone when I forgot it at security check. I couldn’t deboard so they brought it to me on the flight. Airindia staff helped me when most airlines wouldnt
@arafatkatze@cline@AmpCode@Cursor So what’s the alternative to multi agent and more instructions? Agree with the 3 problems and agentic search > vector search
Introducing ❄️ @snowglobe_so, the simulation engine for AI chatbots.
Magically simulate the behavior of your users to test and improve your chatbots.
Find failures before your users do.
Am so hesitant to add readme file in code dirs fearing coding agent will update code but not doc at time t and stale docs will throw off the agent at time t+1. precom check that keeps readme updated? any solutions @dosu_ai@cognition_labs@augmentcode@coderabbitai@AnthropicAI?
But they can’t do that for config. Gonna dig into infra config (k8s, terraform, helm) next…
Possible solutions:
-add instruction to agent md file.
-wait for models to get better at it?
-any suggestions?
Starting to share problems I face while coding with agents
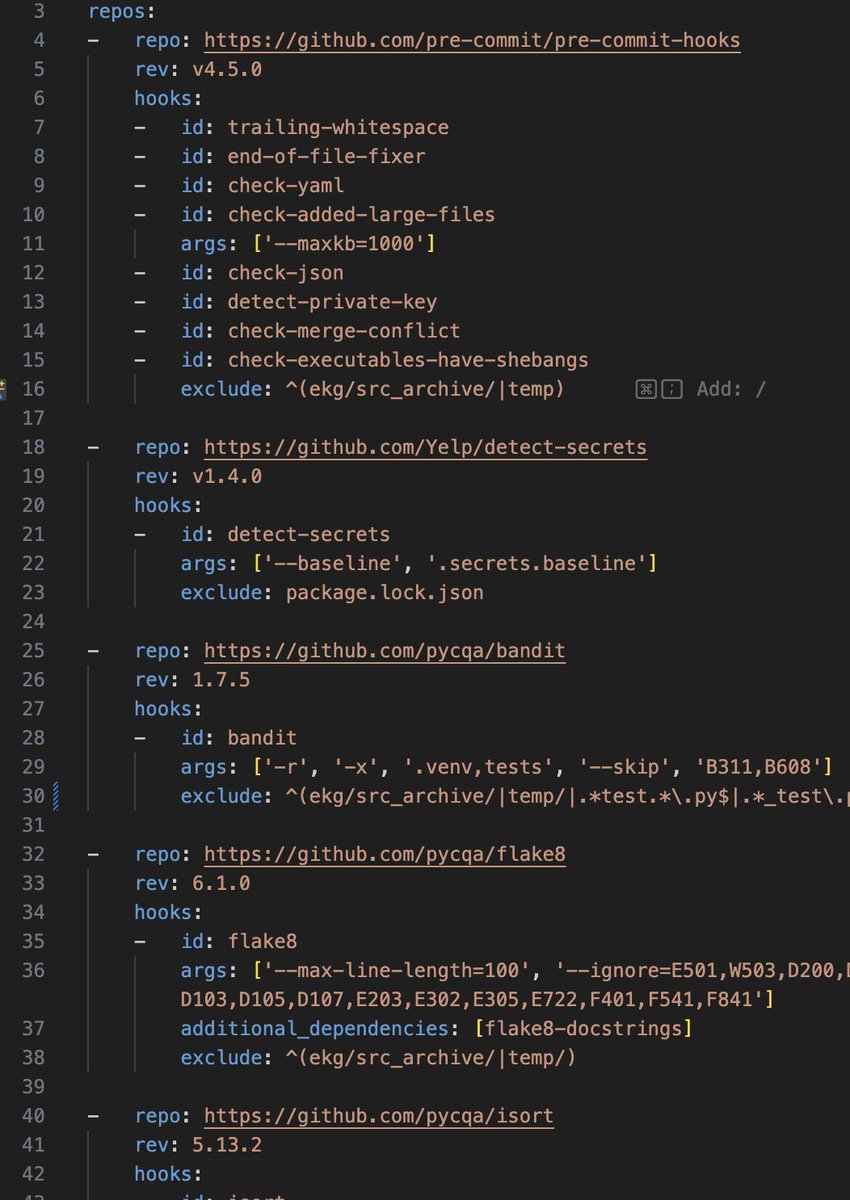
#1:Coding agents dont yet understand devops config (lint, ide, pre-commit, test, ci, sec). How do I know? If you ask them to make a change in app code they can proactively try to re-use or update related code files..(1/2)
The easiest way to get started with #claudecode or @cursor_ai agent on an existing code base is to ask it to configure/ improve pre-commit check, run it and fix all the failures. Did it for all my repos, programming with only agents now
🎧 New SSB Pod w/ @utkarshohm - Director of AI @thoughtspot 🎧
- Applying LLMs to High Fidelity Analytics Use Cases
- Challenges with using Text to SQL model output
- Data Security for LLM Enabled Products
- Customer Outcomes from Sage
Stream on X or other platforms (🧵)
@bindureddy I believe that too but I see that the ratio of gpt/Claude production deployments to that of open source models is 10:1 right now across startups, big tech and enterprises alike! Any examples of latter that you can share?
"How is LLaMa.cpp possible?"
great post by @finbarrtimbers
https://t.co/L0aLRXrh9f
llama.cpp surprised many people (myself included) with how quickly you can run large LLMs on small computers, e.g. 7B runs @ ~16 tok/s on a MacBook. Wait don't you need supercomputers to work with LLMs?
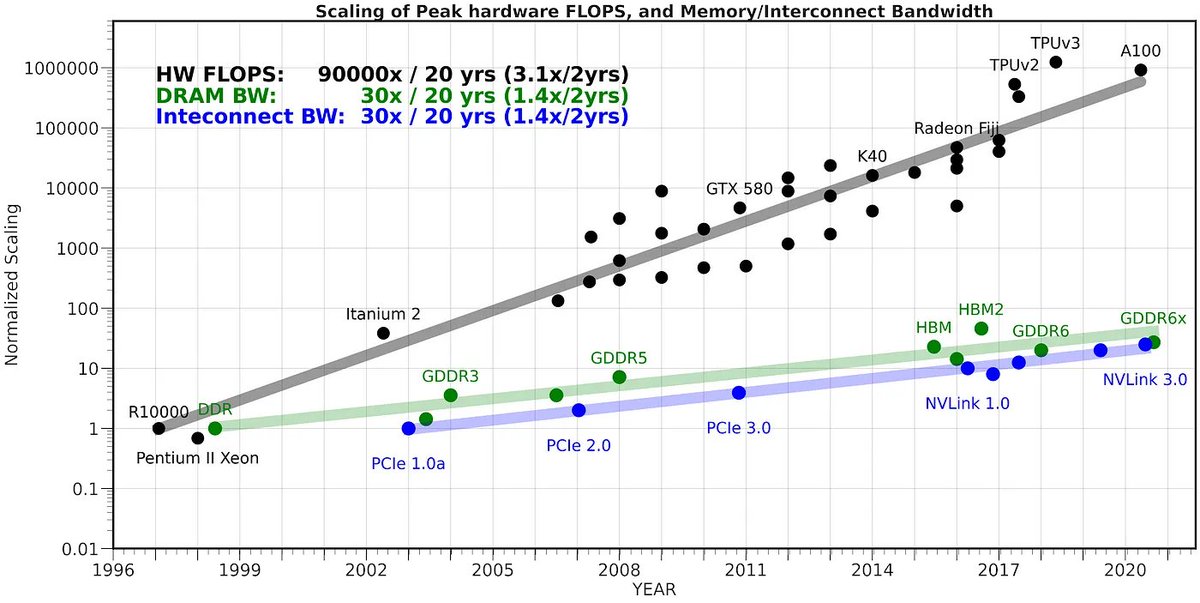
TLDR at batch_size=1 (i.e. just generating a single stream of prediction on your computer), the inference is super duper memory-bound. The on-chip compute units are twiddling their thumbs while sucking model weights through a straw from DRAM. Every individual weight that is expensively loaded from DRAM onto the chip is only used for a single instant multiply to process each new input token. So the stat to look at is not FLOPS but the memory bandwidth.
Let's take a look:
A100: 1935 GB/s memory bandwidth, 1248 TOPS
MacBook M2: 100 GB/s, 7 TFLOPS
The compute is ~200X but the memory bandwidth only ~20X. So the little M2 chip that could will only be about ~20X slower than a mighty A100. This is ~10X faster than you might naively expect just looking at ops.
The situation becomes a lot more different when you inference at a very high batch size (e.g. ~160+), such as when you're hosting an LLM engine simultaneously serving a lot of parallel requests. Or in training, where you aren't forced to go serially token by token and can parallelize across both batch and time dimension, because the next token targets (labels) are known. In these cases, once you load the weights into on-chip cache and pay that large fixed cost, you can re-use them across many input examples and reach ~50%+ utilization, actually making those FLOPS count.
So TLDR why is LLM inference surprisingly fast on your MacBook? If all you want to do is batch 1 inference (i.e. a single "stream" of generation), only the memory bandwidth matters. And the memory bandwidth gap between chips is a lot smaller, and has been a lot harder to scale compared to flops.
supplemental figure
https://t.co/2j6NGSFRPc
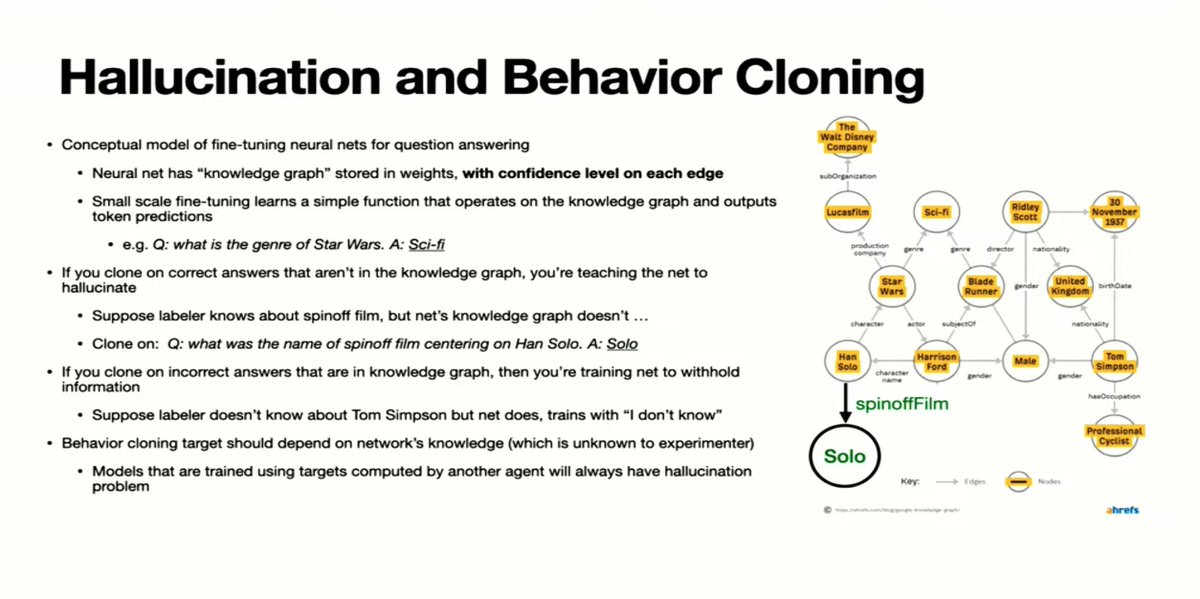
If you clone on correct answers that aren't in the knowledge graph, you're teaching the net to hallucinate.
If you say "don't know" to answers that are in fact in the knowledge graph, then you're teaching the net to withhold information unnecessarily.
2/
Is Falcon really better than LLaMA?
Short take: probably not.
Longer take: we reproduced LLaMA 65B eval on MMLU and we got 61.4, close to the official number (63.4), much higher than its Open LLM Leaderboard number (48.8), and clearly higher than Falcon (52.7).
Code and prompt open-sourced at https://t.co/KzfqCzvU5W
No fancy prompting engineering, no fancy decoding, everything by default.
----
Full story:
On OpenLLM Leaderboard (https://t.co/j4zBmmRnsa), Falcon is the top 1, suppressing LLaMA, and promoted by @Thom_Wolf (https://t.co/sNZFtRv6K7)
Yet later @karpathy expressed concern about why on Open LLM Leaderboard, the LLaMA 65B score is significantly lower than official (48.8 v.s. 63.4), see https://t.co/JzcrYhSeoA
We figure that a simple quick open-sourced evaluation script on LLaMA 65B would clarify, so we just did it https://t.co/KzfqCzvU5W
Again, everything is default, official MMLU prompt, no fancy prompt engineering, no fancy decoding. LLaMA 65B simply can do it. We encourage everyone to try the eval script out.
This result makes us continue to hold the belief that the best bet of open-source community to get close to GPT-3.5 is to do RLHF on LLaMA 65B, per our previous discovery in Chain-of-thought Hub https://t.co/N0ng4cwhmI
Yet we do not intend to raise wars between LLaMA and Falcon -- both are great open-sourced models and have made significant contribution to the field! Falcon also have the advantage of a easier license, which also gives its great potential to be awesome!
🍻🍻
* Hiring five engineers for one year costs a million dollars.
* Your observability bill(s) should come to about 20-25% of your infrastructure bill (combined)
* If the tool costs >$30k/year, you can prob get a discount
what other budget rules of thumb do you have, as a manager?
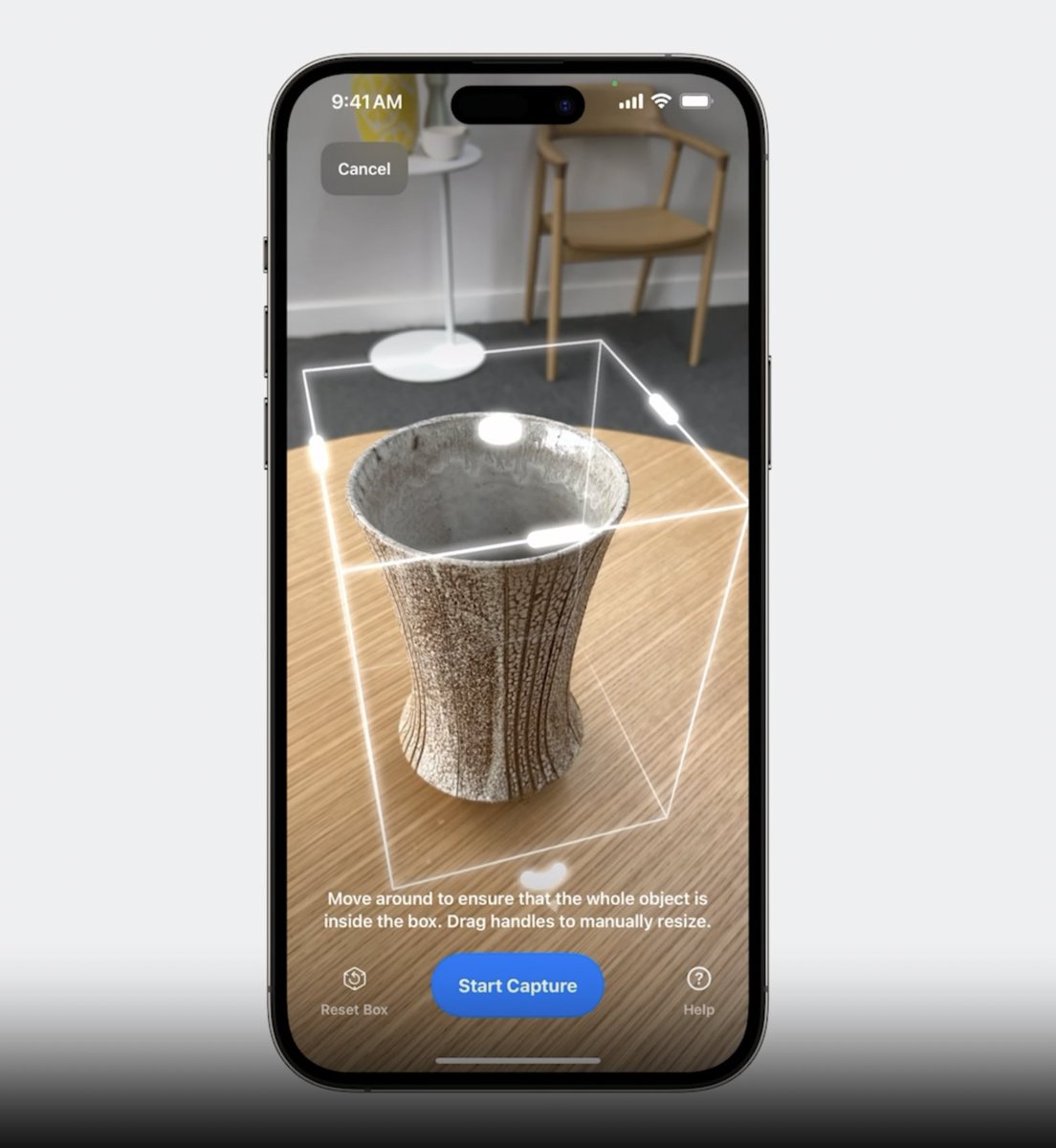
Apple's Object Capture now runs *on-device*! 💥 😳
This is a game changer as as any app can now integrate 3D scanning *for free*, and you can see where this is going at next WWDCs...
https://t.co/UrHymmlJbH
🚫 Beware of biases & toxicity inherited from Big Tech LLM
The tl;dr - several conditions need to be met for your open source fine tuned model to truly benefit from a Big Tech LLM.
More details in https://t.co/k3frNmCMzG
Can smaller open source models like #alpaca#dolly#mpt#falcon fine tuned on output of sota LLMs from @OpenAI@Google@Meta compete with them? Takeaways from @UCBerkeley paper "The False Promise of Imitating Proprietary LLMs".
🧵
💪 Fine tuning doesn't create new knowledge, just augments capabilities. Prefer models avail in Billion+ size
🖌️Imitation models learn style, not content. Human labelers w/o domain expertise/sufficient time get deceived by confident but factually inaccurate answers