Run Polars' distributed engine on your own infrastructure.
Deploy a distributed Polars cluster on any Kubernetes setup (EKS, AKS, GKE, or minikube) and get a query dashboard with past queries, advanced query profiling, Open-lineage support, and more.
Sign up and install with a single Helm command. Connect via `ClusterContext` and run distributed queries.
Read all about it at https://t.co/PnKfBF2wZ2
We've released Python Polars 1.41. Some of the highlights:
• Faster Parquet metadata decoding
Parquet metadata is now decoded with a hand-written, specialized Thrift parser instead of the generic auto-generated one. Speedup scales with table width: 1.6× for 100-column tables, up to 3.3× for 10,000-column tables.
• Nested common subplan elimination
The query optimizer now eliminates duplicate subplans at all nesting depths.
• LazyFrame.gather()
Row selection by integer index is now available in lazy mode, without collecting first.
Blog post: https://t.co/r5vnzQ4HkJ
We've released Python Polars 1.40. Some of the highlights:
• Streaming grouped AsOf join
AsOf joins with a `by` argument are now supported in the streaming engine, extending last release's streaming AsOf support to grouped time-series joins.
• Basic over() in the streaming engine
Elementwise window expressions using over() can now run in the streaming engine.
• More expressions lowered to streaming
cov(), corr(), interpolate(), skew(), kurtosis(), and entropy() are now natively supported in the streaming engine.
Link to the complete changelog: https://t.co/P7pkxZrNuk
We've released Python Polars 1.39. Some of the highlights:
• Streaming AsOf join
join_asof() is now supported in the streaming engine, enabling memory-efficient time-series joins.
• sink_iceberg() for writing to Iceberg tables
A new LazyFrame sink that writes directly to Apache Iceberg tables. Combined with the existing scan_iceberg(), Polars now supports full read/write workflows for Iceberg-based data lakehouses.
• Streaming cloud downloads
scan_csv(), scan_ndjson(), and scan_lines() can now stream data directly from cloud storage instead of downloading the full file first.
Link to the complete changelog: https://t.co/62Mx2ZJWVh
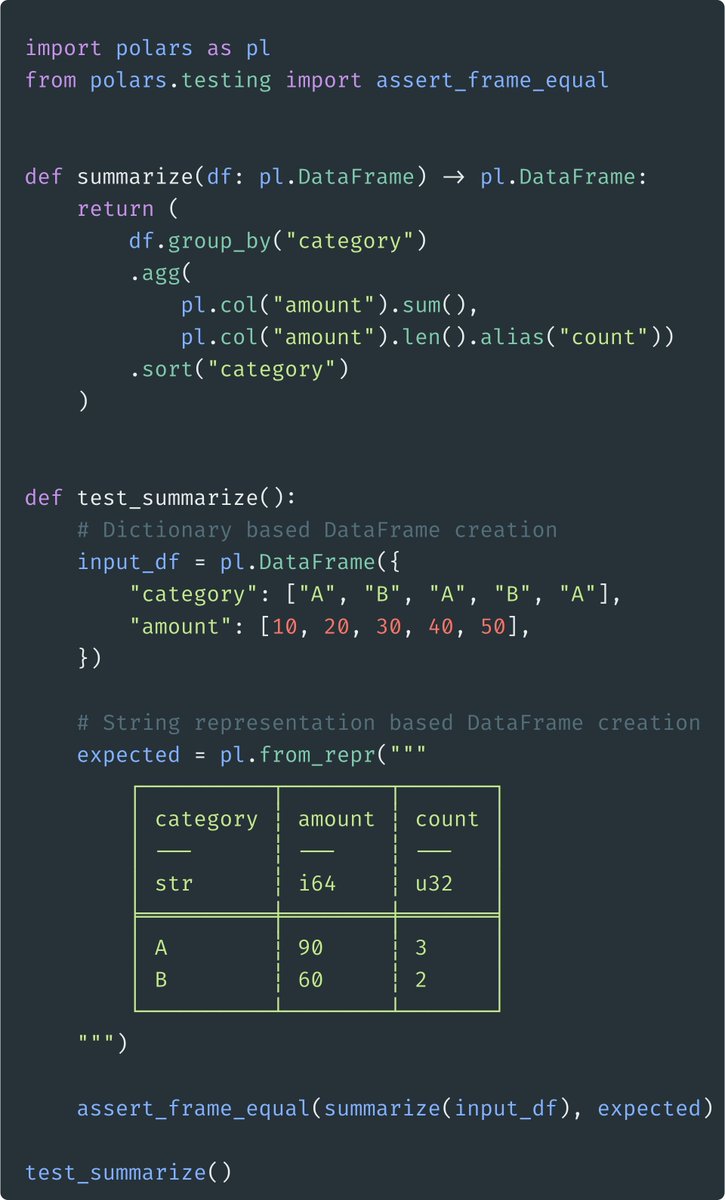
pl.from_repr() constructs a DataFrame or Series directly from its printed string representation. This can be useful in unit tests: instead of rebuilding expected DataFrames through dictionaries with typecasting, the schema is encoded in the header and the values are right there in the table. You can see at a glance what the test is asserting.
We've released Python Polars 1.38. Some of the highlights:
• (De)Compression support on text based sources and sinks
zstd and gzip are now supported for write_csv(), sink_csv(), scan_ndjson(), and sink_ndjson().
• scan_lines() to read text files
This new function constructs a LazyFrame by scanning lines from a file into a string column. This is particularly useful for working with (compressed) log files.
• Merge join in the Streaming engine
When join columns are sorted in both DataFrames, we now use a merge join, which can improve performance 2-4x and in some cases even up to 10x.
To unlock these performance gains, use the Lazy API and apply set_sorted(col) to let Polars know the data is sorted.
Link to the complete changelog: https://t.co/wRdWzdc7iT
The early design decisions for the Categorical type were under strain because of our streaming engine. Every data chunk carried its own mapping between the categories and their underlying physical values, forcing constant re-encoding. The global StringCache we built to solve it caused lock contention and wasn't designed for a distributed architecture.
The new Categories object, released in 1.31, solves this, and gives you:
• Control over the physical type (UInt8/16/32)
• Named categories with namespaces
• Parallel updates without locks
• Automatic garbage collection
When you know the categories up front you can use Enums. They're faster because of their immutability and allow you to define the sorting order of values.
The StringCache is now a no-op, but the code will keep working how it used to (with global Categories). You can also migrate by replacing it with explicit Categories where needed.
The result is a Categoricals data type that works well on the streaming engine without performance degradation, and is compatible with a distributed architecture.
Read the full deep dive: https://t.co/kkikdqxrER
Learn NumPy in 40 Minutes
The video introduces the core concepts of NumPy and shows how its array operations form the foundation of numerical computing in Python. It emphasizes why NumPy is a must-learn tool for data science, AI, machine learning, and scientific workflows.
https://t.co/0gj2URh0tw
We've just released 1.36.0 with a couple of big features. Here are the highlights:
Highlights:
🧩 Extension Types: Allows for custom data types within the Polars ecosystem. You can see an example in the image below.
🛟 Float16 Support: First-class support for model parameters and half-precision floating point data.
↪️ Lazy Pivot: LazyFrame.pivot() is finally here, allowing for query optimization on reshape operations.
👀 show(): Easily preview the first rows of a DataFrame or LazyFrame.
🗄️ SQL Parity: Added Window functions (ROW_NUMBER, RANK, DENSE_RANK) and CROSS JOIN UNNEST to the SQL API.
Performance:
⏱️ Parquet writer improvement: 2.2x runtime improvement with a 20% peak memory usage reduction, which is even 39% for partitioned sinks (on a synthetic benchmark).
🚀 Support for group_by_dynamic and Sorted Group-By on the streaming engine.
Find the full release notes here: https://t.co/cKr7V8purg
It’s been a year since the last Polars in Aggregate. Since then, we've shipped 37 releases, merged over 2,300 PRs, and built two new engines.
Here is what you need to know:
☁️ Polars Cloud is Live: Write code once, run it anywhere. Whether processing hundreds of rows locally or billions of records distributed, the API remains the same, and data stays within your cloud.
🚀 Next-Gen Streaming: Our rewritten streaming engine is showing performance gains of 3x-7x in benchmarks compared to the default in-memory engine.
🔢 Stable Decimals & Int128: For financial and scientific contexts where 0.1 + 0.2 must exactly equal 0.3, we now offer full precision control and a massive integer range.
We also cover the Categorical overhaul, collect_batches() for generators, and the new Common Subplan Elimination optimizer.
Read the full breakdown here:
https://t.co/kVGBD9VUPl
We've updated our benchmarks run. It has been more than a year since we ran them. Since then we've designed and implemented a complete novel streaming engine that can deal with Polars' data model.
The future of Polars looks bright and very, very fast!
https://t.co/li9LYERkGe
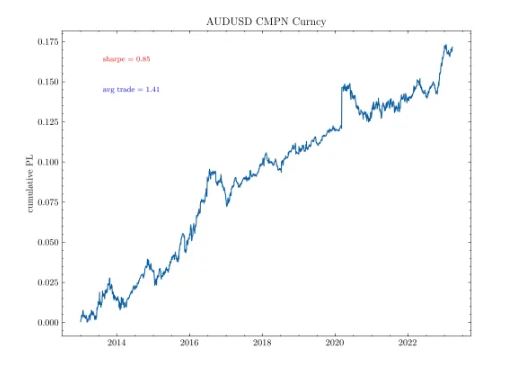
#AMM Paper with some embedded Python source:
Market making model analysis in High Frequency Trading for the north American stock
market
A simple approach without performance analysis, but still a good read for the #hft and #amm uninitiated.
https://t.co/jDOEEnqKyd
"A Formalized Approach to Validation of Parametric Quantitative Trading Models": "Parametric trading models represent mathematical operators that act upon time series of features and a set of parameters to generate trading signals." https://t.co/Z21lTfABS8
Post & Python: "Wavelet transform provides a unique lens to analyze stock market data, balancing both time and frequency insights... capturing both its large trends and minute fluctuations." https://t.co/hfG3gI08MX