Come join us in our mission to create bigger datasets to understand human development! We're hiring two software developers to join our team and build data repositories. Remote work possible.
Please RT!
https://t.co/SyHNrHTIIF
@doughertyorama We don't have a codebook per se -- I think the prereg (https://t.co/lcwFn8GdAC) has the clearest explanation of how variables were coded and transformed.
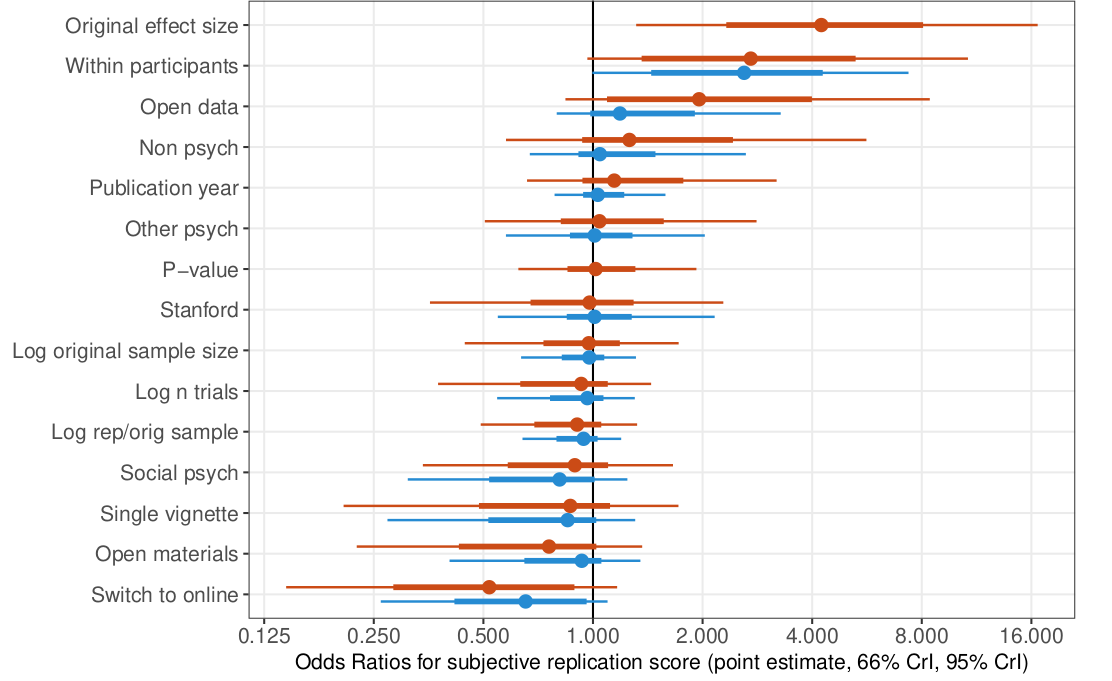
New preprint with @mcxfrank and Maya Mathur: Eleven years of student replication projects provide evidence on the correlates of replicability in psychology (https://t.co/AYlOGH5KhM) reporting 176 replications from students in a grad methods class @StanfordPsych. (1/5)
So excited to see all of these student projects together at last! This work realizes an idea that @rebecca_saxe introduced me to years ago: that students are the real drivers of cumulative science.
original idea: https://t.co/W8fAZt9rFE
new preprint: https://t.co/MIGnf1g6pP
Our coded data, code, pre-reg, and a number of student reports are at https://t.co/K3lyTPIZVi. We're extremely grateful to all the students who did the replications -- this data would not exist without their efforts! (5/5)
but many also correlate with each other! When all the predictors are in the same model (with shrinkage prior), larger original effect size and within-participants designs are the strongest predictors of replication success. (4/5)
Check out our new paper with @jurafsky! What inductive learning biases influence language learning, and how? We pretrain transformer models on different structures and fine-tune on English to test the learning effects of different inductive biases https://t.co/XJsVuGh5eN
@HaoHailin @roger_p_levy@glossapsycholx Interesting. What effect is this happening with? The targeted effects I've studied with (A-)Maze have had the largest effect at the critical word, but there's many phenomena out there. I might try out https://t.co/cKSWrZQlYq from @coryshain to deal with spillover.
Let me tell you why I'm so excited about this new paper by the amazing @veroboyce in @glossapsycholx, ""A-maze of natural stories: comprehension and surprisal in the Maze task". 1/9
https://t.co/rlcRiLdhLa
@jkdempc@tmalsburg I-maze (from @weGotlieb ) might be good here. It mixes A-maze and nonce distractors, so you can have the control of a nonce distractor at the critical word, but get the benefits of A-maze over L-maze overall. See https://t.co/QRXd5W8dhW and https://t.co/djuesGfmjp
Key assumption in experimental pragmatics & semantics: people who judge a sentence like ´Some dogs are mammals’ false do so because they derive the ´Some, but not all’ implicature. In this new paper we show that this assumption is in fact unwarranted 1/3 https://t.co/tddlbpNdaR
Demand characteristics are a textbook concern in research w/ humans
Yet, they’re not actually well understood
In this new pre-print, @mcxfrank and I used meta-analysis and replication to take stock. What we found was informative...but also concerning
https://t.co/JRGDYdxOu7
🧵
I'm thrilled to have this paper with @roger_p_levy out in @glossapsycholx ! I hope our methods work on Maze gives more researchers an easy option for collecting incremental reading time data on a range of materials!
The Glossa Psycholinguistics team is delighted to announce the publication of a new article!
Head over to our website to read
"A-maze of natural stories: comprehension and surprisal in the Maze task", by Veronica Boyce and @roger_p_levy
https://t.co/qFPCkdSlCc
Ibex-with-Maze now supports adding a delay after a participant makes an error before they can try again (in redo mode). Caveat: I haven't used it in experiments yet! (code: https://t.co/E0ap9s6n4T, commentary: https://t.co/RYA1oshEEh)
This paper is one culmination of three-plus years' work investigating the syntactic capabilities of today's autoregressive language models, with carefully controlled experiments like we would use in a psycholinguistics experiment with human subjects. The results blow me away. 1/5