🚨Model alert!🚨
We're very proud to release the biggest decoder-only auto-regressive GPT model for Spanish ✍️
🧠 Model: https://t.co/mY1ByUs2lR
💾 Dataset: https://t.co/fOIp7kUdLe
💻 Demo: https://t.co/odb7ZOhGL2
📢 More time to submit! ⏳
The READIxTSAR Workshop (Reading Difficulties + Text Simplification) has extended its deadline for #LREC2026 🙌
Don't miss the chance to showcase your research on #NLProc, #accessibility, and #simplification!
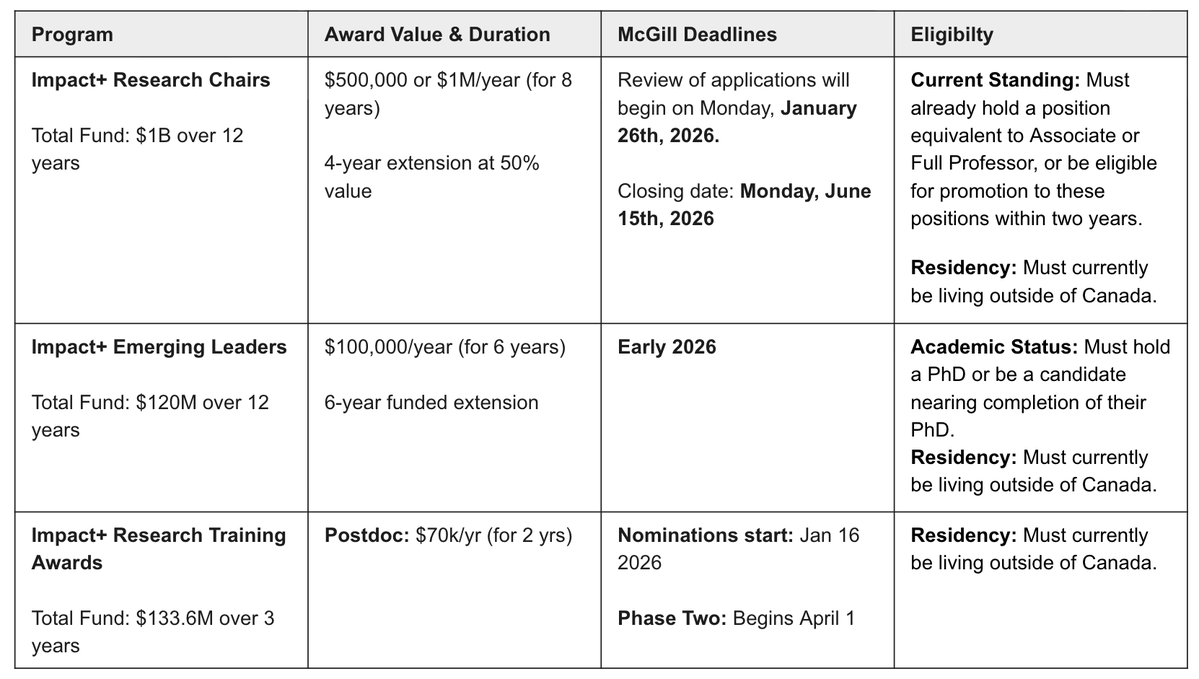
McGill University (@mcgillu) has many open faculty and postdoctoral positions with generous funding packages, thanks to Impact+ grants, which are investing $2 billion to attract global talent to Canada 🇨🇦🇨🇦🇨🇦.
Associate/Full Professor: $8 million startup package
Assistant Professor: $600K startup package
Postdoc: $70K (starting salary)
If you are interested and work in the space of AI/ML/NLP/LLMs, please reach out to me.
#AI #NLProc #ML
Can national libraries shape AI?
Javier de la Rosa (@versae) shows how Norway’s National Library uses 20 years of digitisation to power Norwegian language models, speech tech and privacy-centric public-interest AI.
🎧 https://t.co/M2Da2UNOON
📺 https://t.co/WSDpOoxZnu
Full stack devs, SWEs, MLEs, forward deployed engineers, research engineers, applied scientists: we are hiring!
Join us and tackle cutting-edge challenges including physical AI, time series, material sciences, cybersecurity and many more.
Positions available in Paris, London, Singapore, Amsterdam, NYC, SF, or remote.
https://t.co/INALdNGvCP
@VikParuchuri@vanstriendaniel@huggingface This is actually pretty good. Can the layout be done separately, extract the bounding boxes for reading order, and run again on them?
@vanstriendaniel@huggingface Nice! We are currently testing these models out too. Any chance you can add Chandra as well? It's the one that worked best for our newspaper collection so far.
¿Te gustaría formar parte del equipo humano que desarrollará los próximos LLMs en español? Estamos buscando ingenieros en informática deseosos de involucrarse en un proyecto ilusionante y transformador.
Más info. aquí: https://t.co/wlLQlU0wWK
🚀 New Book Alert!
Our edited collection Navigating Artificial Intelligence for Cultural Heritage Organisations is out now! 🎉
Explore 10 chapters on AI in archives, libraries, & museums by top experts.
📖 Free download: https://t.co/XKqg4mpuGa
#AI#CulturalHeritage@UCLpress
@michahu8 Awesome! I didn't get to the appendices yet 😅 Thanks for pointing that out. I'll be testing it on languages other than English, including extremely low-resource.
Excited to drive innovation and push the boundaries of open, scientific AI research & development! 🚀 Join us at @allen_ai to shape the future of OLMo, Molmo, Tulu, and more. We’re hiring at all levels—apply now! 👇 #AI #Hiring
Research Engineer https://t.co/5pJlruiT5J
Research Scientist https://t.co/4pg74asUbg
Young Investigator https://t.co/veTCj9Fotx
🚀 We're Hiring Applied AI Engineers! 🚀
Do you write clean, efficient Python? Are you familiar with AI frameworks? Do you thrive in a collaborative team?
If that sounds like you, DM me now! Let's build the future of AI together. 💡🤖
@maballesterosv En general, sí. Pero depende de la abilidad concreta que se le espera un LLM hoy en día. La mayoría de los modelos son entrenamientos base (pre-training), sin capacidad para seguir instrucciones o los diálogos (post-training).
📢✨ PAPER ALERT ✨📢
Ever wondered whether copyrighted material **actually** makes for better LLMs? 🤔 We asked the same question—and the results are in! Our paper is accepted at NoDaLiDa/Baltic-HLT 2025, and the pre-print is live: 🔗 https://t.co/RJFZMouSD5 🧵👇