Building @usedotfo: Next-gen AI Voice Typing. 🎙️ Vibe Coder | AI & Blockchain Specialist. Serial Founder. Turning intent into logic at the speed of thought. ⚡
@DivyanshT91162 Comparing embedding search to grep is like saying 'a filing cabinet solved the problem' — true, but only because you're describing two different tasks. One finds text. The other finds meaning.
@kwindla@RohanVasishth Voice AI in an autonomous car is the only context where latency is literally a safety variable. A 300ms TTS delay isn't annoying there — it's how many meters you traveled before the car could tell you to brake.
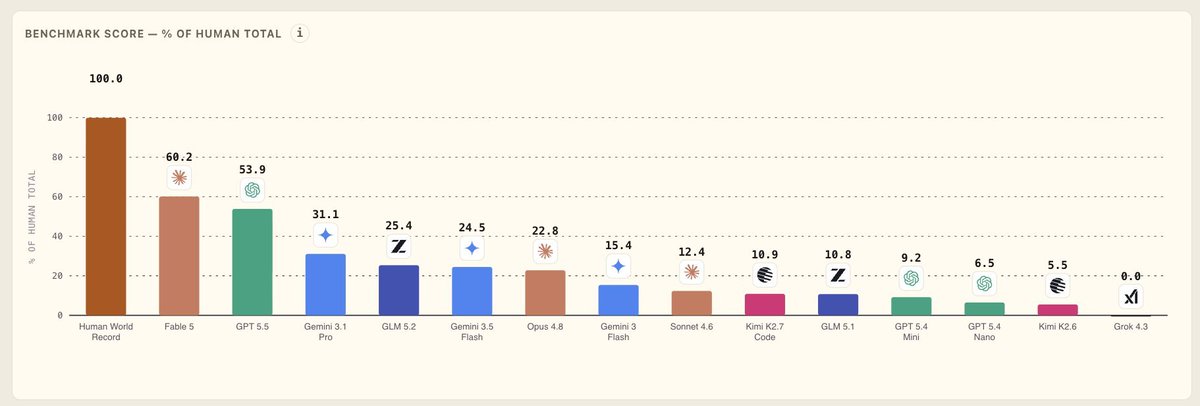
new shape-rotator benchmark
Fable and GPT-5.5 of course far ahead of the field
but now look at GLM-5.2. it's ahead of Gemini 3.5 Flash and Opus 4.8
you can't really benchmaxx a benchmark that was just released
so the GLM-5.2 gains seem more and more like a genuine improvement!
@ivanfioravanti every few months a new model promises disruption. when does 'be ready' become the boy who cried AI?every few months a new model promises disruption. when does 'be ready' become the boy who cried AI?
Outstanding paper on computer-using agents.
(bookmark it)
Computer-using agents drive real software through the screen, but they solve every task from scratch. Ask one to repeat a task, and it re-reads the screen and re-reasons every tap, paying the full cost again.
PreAct compiles the first successful run into a small state-machine program, states that check the screen and transitions that act, then replays it directly on later runs. That runs 8.5 to 13x faster with no per-step language-model calls.
Replay stays guarded. At each step, PreAct checks that the screen matches what the program expects before acting, and hands control back to the agent when reality diverges.
Why does it matter?
Most computer-use costs are repeated reasoning on tasks the agent has already solved. Amortizing that into a replayable program is a clean way to make agents faster the second time.
Paper: https://t.co/kMloX0qC5M
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
RNG-Bench tests if frontier MLLMs can act on what is no longer visible
Matching Pairs and 3D Maze force models to reconstruct hidden states from memory alone.
The hardest configs span 128K tokens and 350 images per episode—and remain far from saturated.
SOMEONE LEAKED THE SYSTEM PROMPTS OF EVERY MAJOR AI
Claude Opus 4.8, Gpt-5.5, Gemini 3.5, Grok, Cursor, Copilot all of them
what's inside:
→ claude's exact rules for when it can refuse you (spoiler: the bar is very high)
→ gpt-5.5's full thinking vs instant prompt differences → gemini 3.5 flash tools config in raw json
→ cursor's complete coding agent instructions
→ docker, zed, perplexity, notion all leaked
this isn't jailbreaks. this is the actual personality, behavior, and constraint layer shipped with every response you've ever gotten from these models
the ai companies know this repo exists
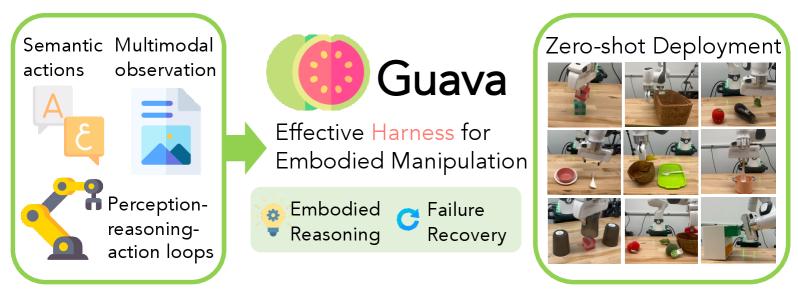
Guava: a universal harness for robot manipulation
A 4B open-source model trained on fewer than 2K simulation trajectories matches frontier proprietary models on real-world tasks, generalizing zero-shot to unseen objects and long-horizon tasks.
@Akashi203 Cooking everything at once vs. running to the pantry between each ingredient. The speedup is real — but the compile time better be worth it.
What's happening in AI right now is genuinely hard to process.
A 3 billion parameter model is matching models that are 200 to 300 times larger. On math. On coding. On reasoning. And beating some of them.
It's called VibeThinker-3B. Built by Sina Weibo's team on a tiny Qwen 3B base.
→ 94.3% on AIME math matches DeepSeek V3.2 (671B) and Kimi K2.5 (1 trillion parameters)
→ 96.1% on LeetCode beats GPT-5.2 and Claude 4.6 on unseen contest problems
→ 80.2% on LiveCodeBench highest of any small or mid-size model tested
A model you can run on a laptop is solving competition math at the same level as models that need entire GPU clusters.
The idea behind it: reasoning and knowledge are two different things.
Knowledge needs massive parameters to store facts. Reasoning is a procedure search, check, correct, compose and procedures compress into small models far more efficiently.
The honest catch: ask it a broad factual question and it trails the big models badly. This isn't a general-purpose win.
It's a reasoning specialist. And that's exactly what makes the result credible instead of hype.
A 3B model. Competing with trillion-parameter flagships. On reasoning tasks. Running locally. That's where we are now.
@scaling01 "Cost per token" is a bad proxy for value. A $20 flight and a $2000 flight both get you to NYC. The seat class is different. Frontier labs are charging for the window.
@kwindla TTS by metrics is like judging a concert by the setlist. The performance is the product, and performance doesn't fit in a spreadsheet.TTS by metrics is like judging a concert by the setlist. The performance is the product, and performance doesn't fit in a spreadsheet.