Great to see autoresearch blowing up becoz of the legendary Karpathy sensei. This year will ofc be an exciting year for automated AI research. For all of you guys excited to jump onto it, hopefully our papers will be some helpful references:
- automated feedback loop for research agents to optimize LLM pre-training and post-training stacks: https://t.co/Bu0p4M1DOw
- generating novel research ideas with LLMs, along with a comparison against human experts: https://t.co/5Wnt8G2XbO
- evaluating the effectiveness of LLM-generated ideas through experiment execution: https://t.co/szBSHimZKl
- finetuning LLMs to directly predict the effectiveness of research ideas: https://t.co/g99KkBmypL
@kavinbm power-law K shaped divergence, a small fraction would get much better than generations before them, the much larger fraction will get higher negative outcomes than folks before them.
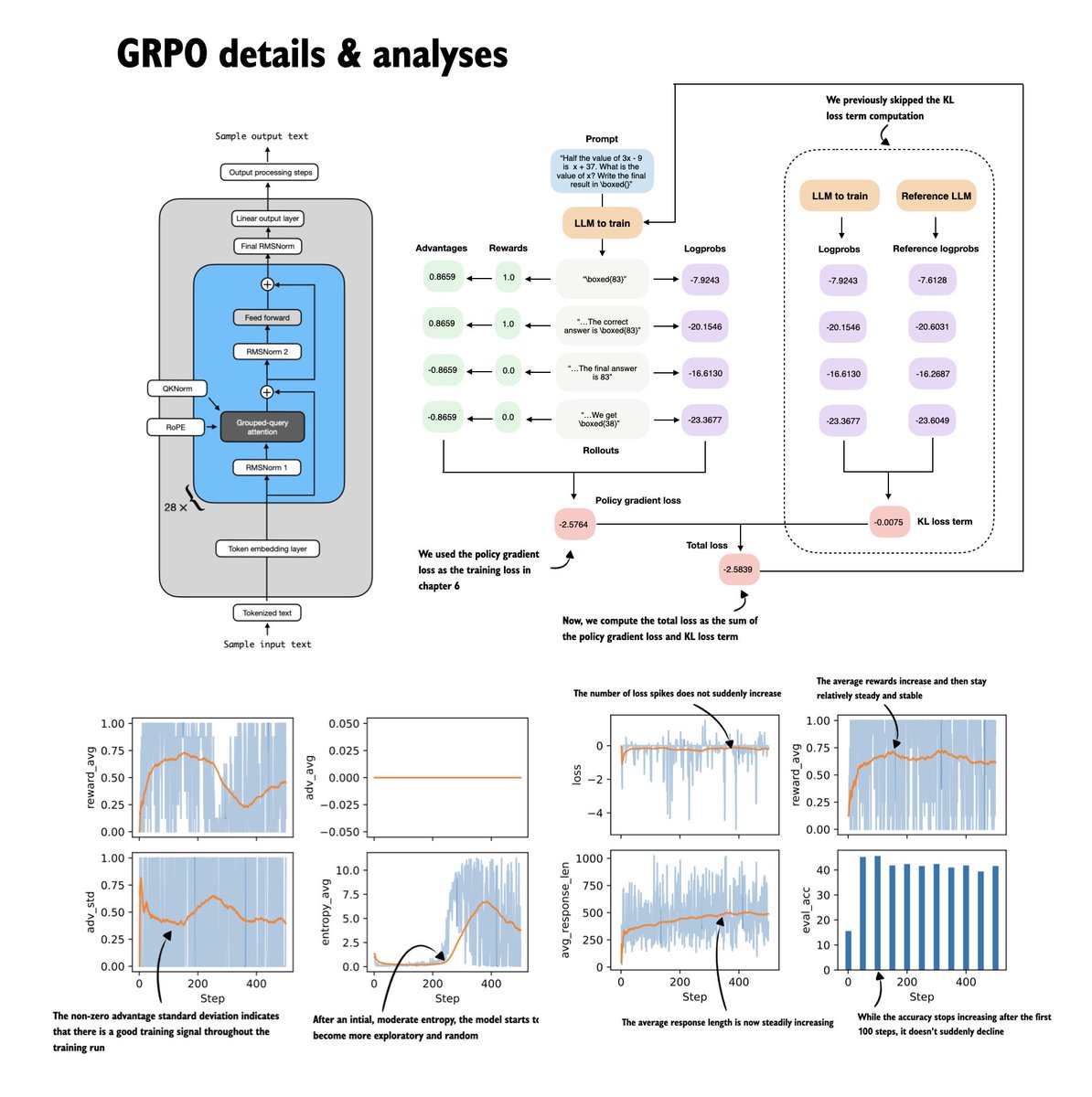
Finished Ch07 on Improving GRPO for Reinforcement Learning!
Building on the GRPO from scratch intro, this adds (and analyzes) more bells and whistles! (Clipped policy ratios, KL term, format rewards, and couple of improvements.)
https://t.co/twsR8cdhh1
@atullchaurasia the standard ml interview process is much better designed -> ai assisted coding round, ml problem solving, ml system design, technical deep dive, culture fit.
Rq k means embedding + quotient embedding for highly sparse categorical data + (tranformer block with relative time bias+ importance bias on meta preferences+ alibi/rope position bias + qk norm) + cascaded cross entropy is all you need for recsys.
@cosminnegruseri@agrwalprabhat Use semantic ids eith rq kmwans. Relative time bias, additive importance bias, cascaded rq cross entropy loss, quotient embedding for compressing sparse data, to get SOTA, I used these tricks to get highest reported test ndcg@10bat both zvuk and yamda, basically HSTU + add-ons.
On DeepWiki and increasing malleability of software.
This starts as partially a post on appreciation to DeepWiki, which I routinely find very useful and I think more people would find useful to know about. I went through a few iterations of use:
Their first feature was that it auto-builds wiki pages for github repos (e.g. nanochat here) with quick Q&A:
https://t.co/DQHXagUwK0
Just swap "github" to "deepwiki" in the URL for any repo and you can instantly Q&A against it. For example, yesterday I was curious about "how does torchao implement fp8 training?". I find that in *many* cases, library docs can be spotty and outdated and bad, but directly asking questions to the code via DeepWiki works very well. The code is the source of truth and LLMs are increasingly able to understand it.
But then I realized that in many cases it's even a lot more powerful not being the direct (human) consumer of this information/functionality, but giving your agent access to DeepWiki via MCP. So e.g. yesterday I faced some annoyances with using torchao library for fp8 training and I had the suspicion that the whole thing really shouldn't be that complicated (wait shouldn't this be a Function like Linear except with a few extra casts and 3 calls to torch._scaled_mm?) so I tried:
"Use DeepWiki MCP and Github CLI to look at how torchao implements fp8 training. Is it possible to 'rip out' the functionality? Implement nanochat/fp8.py that has identical API but is fully self-contained"
Claude went off for 5 minutes and came back with 150 lines of clean code that worked out of the box, with tests proving equivalent results, which allowed me to delete torchao as repo dependency, and for some reason I still don't fully understand (I think it has to do with internals of torch compile) - this simple version runs 3% faster. The agent also found a lot of tiny implementation details that actually do matter, that I may have naively missed otherwise and that would have been very hard for maintainers to keep docs about. Tricks around numerics, dtypes, autocast, meta device, torch compile interactions so I learned a lot from the process too. So this is now the default fp8 training implementation for nanochat
https://t.co/3i5cv6grWm
Anyway TLDR I find this combo of DeepWiki MCP + GitHub CLI is quite powerful to "rip out" any specific functionality from any github repo and target it for the very specific use case that you have in mind, and it actually kind of works now in some cases. Maybe you don't download, configure and take dependency on a giant monolithic library, maybe you point your agent at it and rip out the exact part you need. Maybe this informs how we write software more generally to actively encourage this workflow - e.g. building more "bacterial code", code that is less tangled, more self-contained, more dependency-free, more stateless, much easier to rip out from the repo (https://t.co/iKJUoHiIpl)
There's obvious downsides and risks to this, but it is fundamentally a new option that was not possible or economical before (it would have cost too much time) but now with agents, it is. Software might become a lot more fluid and malleable. "Libraries are over, LLMs are the new compiler" :). And does your project really need its 100MB of dependencies?
I bombed my YC application 7 times, before finally making it. So I created Y Bombinator, it tells your chances of getting in and helps avoid the mistakes I did.
Take a look!
https://t.co/sjzgia5ZKq