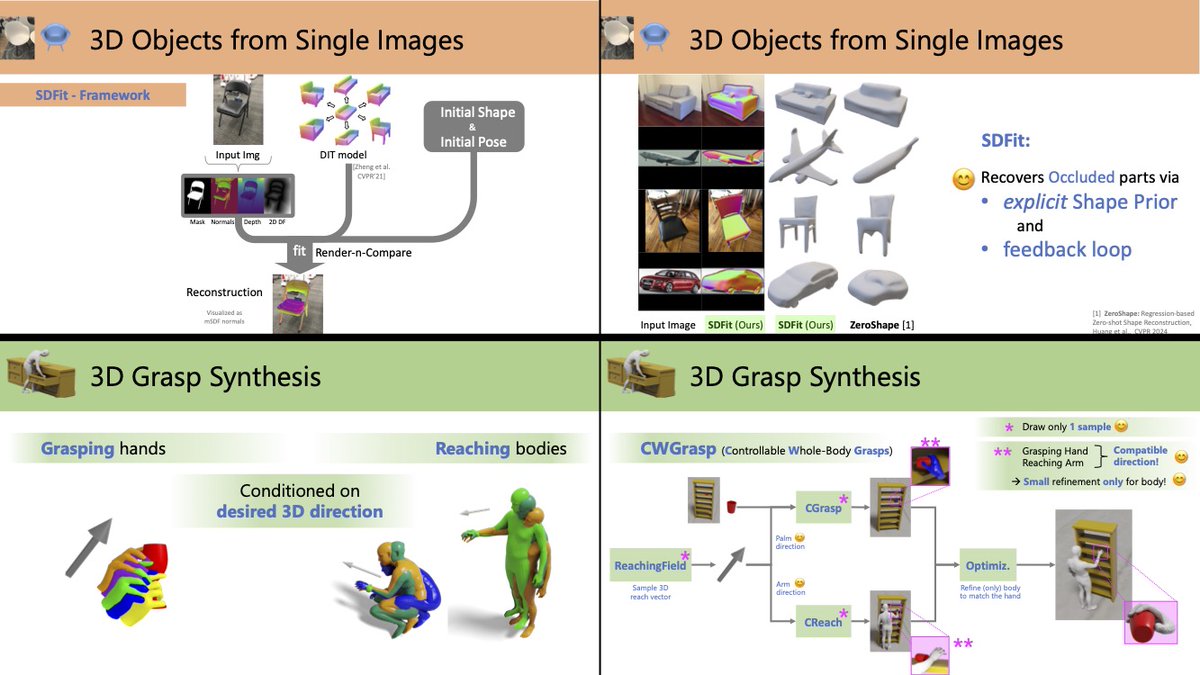
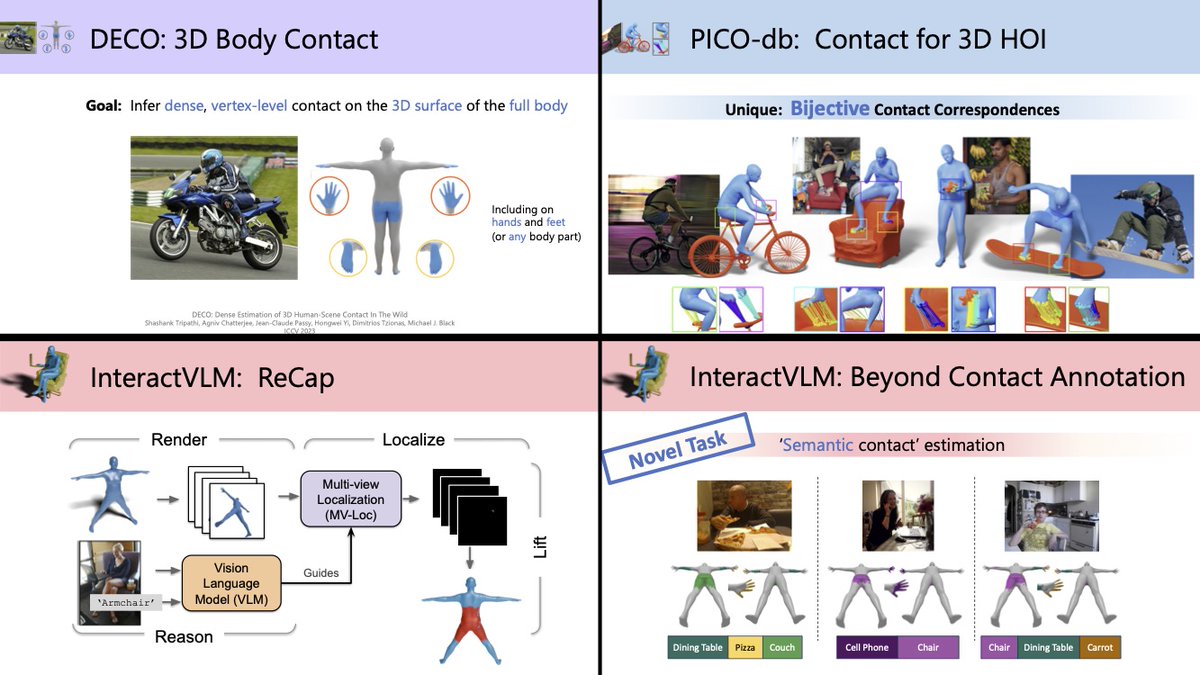
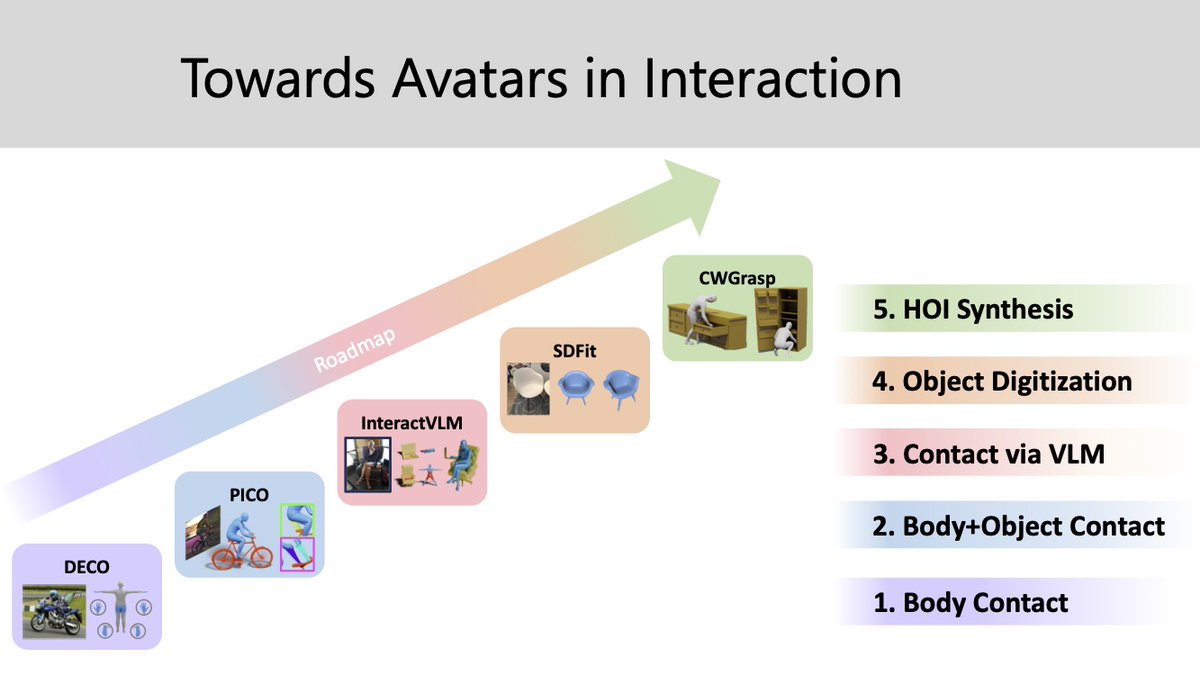
🎯 Modeling how people interact with objects in #3D is important for both 3D #perception from 2D images, and for 3D #avatar synthesis for AR/VR
👉 I gave a talk on this @ #BMVA 'Symposium on Digital Humans'
👉 Video: https://t.co/RJs3fOygDX
👉 Slides: https://t.co/8wJwEGYuss
📢 Working on Digital Humans/Avatars? Register for the BMVA Symposium on Digital Humans on the 28th of May in London! We're also looking for recent work to be presented on the day. Not sure if your work fits? Send me a DM.
Register/submit here 👉 https://t.co/DDC2R3Z0Zg
Many thanks to our co-organisers @avideypi, @vinaypn and @SanyalSoubhik, as well as our exciting keynote speakers Tadas Baltrusaitis, Abhijeet Ghosh, Thu Nguyen-Phuoc and Dimitris Tzionas.
I'm excited to share what I've been working on during my summer internship at @Microsoft . GASP creates photorealistic, real-time Avatars from an image or short video.
Project page: https://t.co/oW3oh4UxH5
Arxiv paper: https://t.co/Y60X5mn66Z
Demo Video: https://t.co/E4y187MmYM
Anne Gagneux, Ségolène Martin, @qu3ntinb, Remi Emonet and I wrote a tutorial blog post on flow matching: https://t.co/TSkg1VZ5cn with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: https://t.co/0GRNZd3l8O
The Computer Vision Foundation has just posted all of the recorded talks from #ICCV2023 up on its YouTube channel.
Check them out here:
https://t.co/hoOc0vqQKf
🚀 Exciting Research Alert! Traditional #AIAlignment#RLHF methods are expensive & require updating billions of parameters.
🔥 Is it possible to do #LLMAlignment without finetuning model parameters?
✅ YES! Transfer Q*: Principled Decoding Alignment
https://t.co/oCiOxIy5VS
This might be one of the most important 45-mn read you could indulge in today if you want to understand the secret behind high performance large language models like Llama3, GPT-4 or Mixtral
Inspired by the @distillpub interactive graphics papers, we settled to write the most extensive, enjoyable and in-depth tech report we could draft on the science of creating high quality web-scale datasets, detailing all the steps and learnings that came in our recent 15 trillion tokens 🍷FineWeb release
And it's not all, in this article we also introduce 📚FineWeb-Edu a filtered subset of Common Crawl with 1.3T tokens containing only web pages with very high educational content. Up to our knowledge, FineWeb-Edu out-performs all openly release web-scale datasets by a significant margin on knowledge- and reasoning-intensive benchmarks like MMLU, ARC, and OpenBookQA
To close, we make a number of surprising observations on the "quality" of the internet it-self which may challenge some of the general assumptions on web data (not saying more, I'll let you draw your conclusions ;)
Take a walk through it, you won't be disappointed 👇
@PankajK25774511 Hi Pankaj, I don't use chatGPT/variants for reading research papers. It may be useful for reading papers in other areas outside the core. For the core areas it's probably best to refer to the original papers and read thoroughly. Let me know if you find it useful.
An important update on the #CVPR2024 submission deadline from the conference organizing committee:
Our Program Chairs have voted to shift the CVPR 2024 submission deadline to November 17th (A one-week extension). The website will be updated shortly to reflect this change.
Super excited to share that my first-ever paper, READ Avatars, has been accepted to @BMVCconf.
Project Page: https://t.co/8WPCSLFeoe
Blog post: https://t.co/ZaC6SxzKHd
TLDR: We bring emotion into audio-driven talking head generation using neural rendering.
🚨Here’s an intuitive explanation for why training on lots and lots of data creates emergent properties, for instance math and reasoning, in large language models like #GPT-4 and #ChatGPT 🚨 1/17
How to do experiments?
Junior students often feel stressed before the weekly meeting with their advisors because their experiments do not go well. 😩😰😱
Some tips on why, what, and how to do experiments. 🧵