Unstructured weight #sparsity made practical.
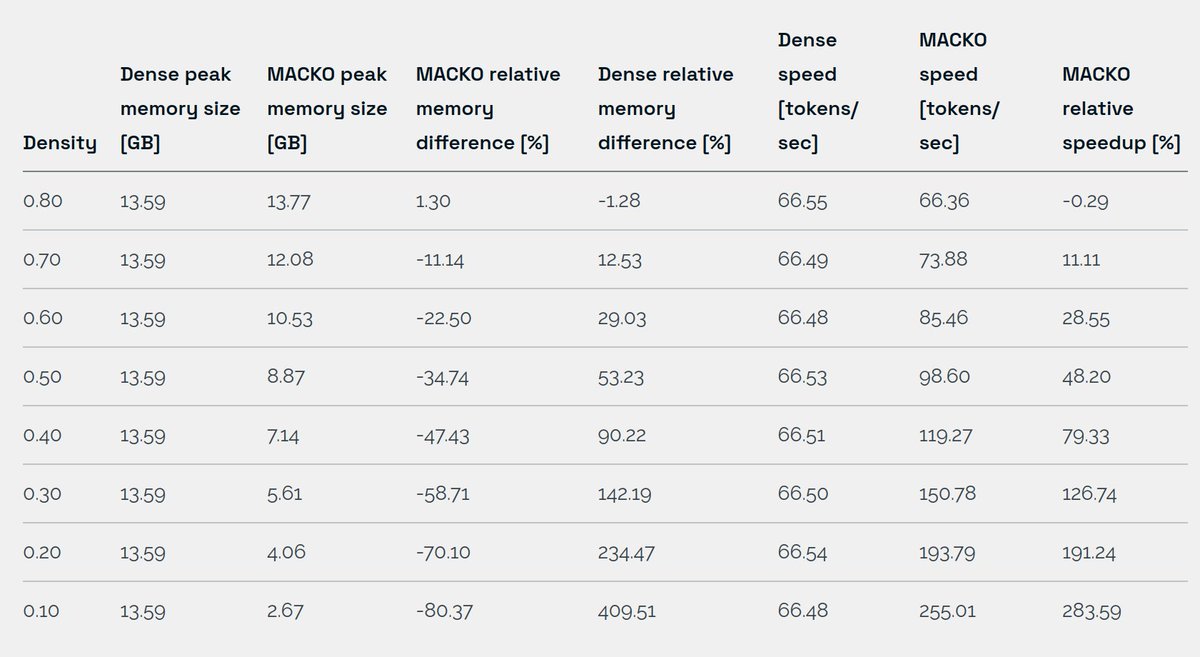
50% unstructured weight sparsity was considered too low for real GPU speed up without specific hardware support (like @cerebras).
With @bozavlado we built MACKO-SpMV - a new matrix format + SpMV kernel to change that. 🧵
@0xJayHK@cerebras@bozavlado tldr: optimize memory while keeping the compression compatible with the GPU programming model. The first step ofc is to figure out, what is the GPU programming model :D
Unstructured weight #sparsity made practical.
50% unstructured weight sparsity was considered too low for real GPU speed up without specific hardware support (like @cerebras).
With @bozavlado we built MACKO-SpMV - a new matrix format + SpMV kernel to change that. 🧵
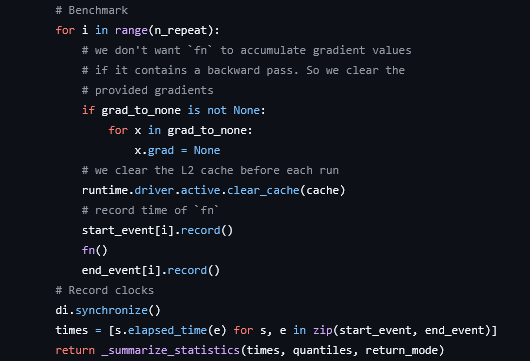
It is funny how little correct information is there about how to properly benchmark a CUDA kernel. Most papers are wrong, eval libraries are hard to inspect and even this could have a problem because it may include the kernel launch depending on clear_cache implementation
btw, I think BackendBench just uses triton's do_bench function, which uses a very similar timing mechanism to the one exploited here and wouldn't be robust to the same side-stream shenanigans
@miru_why@niklassheth@ronusedh@intology My second personal favorite is to not clean the cache between invocations, and testing only on matrices that fit the cache. You can get some truly unbelievable flops :D
@miru_why@niklassheth@ronusedh@intology Hahaha. I spent months debugging this. Had to fix the official torch documentation that contained the same problem in it's examples.
Unfortunately, pretty common pattern.
I do model compression and optimization. It is essential to have access to different GPUs and that would be impossible without @vast_ai . Happy to finally meet you guys at #ICML2025 . And thanks a lot for the Nintendo Switch!