Today we are sharing a new result from BDH: 97.4% accuracy on Extreme Sudoku puzzles while maintaining language fluency.
No chain-of-thought
Current LLMs → nearly 0% accuracy.
If a model can write beautifully but still cannot reason through a hard constraint space, that is not a side issue.
That is the issue.
@adrian_pathway is exploring with @JonKrohnLearns Pathway’s new post-transformer architecture #BDH that aims to bridge the gap between transformer models and how the brain actually works.
https://t.co/kdUlWM7e92
Wow. 🧠
The paper presents Dragon Hatchling, a brain-inspired language model that matches Transformers using local neuron rules for reasoning and memory.
It links brain like local rules to Transformer level performance at 10M to 1B scale.
It makes internals easier to inspect because memory sits on specific neuron pairs and activations are sparse and often monosemantic.
You get reliable long reasoning and clearer debugging, because the model exposes which links carry which concepts in context.
The problem it tackles is long reasoning, models often fail when the task runs longer than training.
The model is a graph of many simple neurons with excitatory and inhibitory circuits and simple thresholds.
It stores short term memory in the strengths of connections using Hebbian learning, so links that fire together get stronger.
Those local rules behave like attention but at the level of single neurons and their links.
They also present BDH-GPU, a GPU friendly version that implements the same behavior as an attention model with a running state.
This design produces positive sparse activations, so only a small fraction of neurons fire at a time.
Many units become monosemantic, meaning one unit often maps to one clear concept even in models under 100M.
The theory ties the approach to distributed computing and explains how longer reasoning can scale with model size and time.
----
Paper – arxiv. org/abs/2509.26507
Paper Title: "The Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain"
along Sutton's lines @pathway_com new post-transformer architecture, Baby Dragon Hatchling (BDH) could pave the way for autonomous AI.
Their paper, The Missing Link Between the Transformer and Models of the Brain, tackles key AI challenges: generalization over time, real-time learning & interpretability
https://t.co/OUzyxg8bjY
We launched a new post-transformer architecture, Baby Dragon Hatchling (BDH) paving the way for autonomous AI.
Our paper, The Missing Link Between the Transformer and Models of the Brain, tackles key AI challenges: generalization over time, real-time learning & interpretability
We are hosting a meetup around LLMs & RAG on April 30 in SF – https://t.co/CffGyht7hV.
Talks by @lukaszkaiser (Co-author of Attention is All You Need) & @JChorowski (Co-author with Y Bengio and G Hinton) followed by drinks and bites (🍕 /🍺).
See you there!
99% of LLM courses teach you how to build LangChain demos using static datasets... 🧸
But real-world LLMOps is a bit different... 🐻
Here is a real-world example with 𝗳𝘂𝗹𝗹 𝘀𝗼𝘂𝗿𝗰𝗲 𝗰𝗼𝗱𝗲 ↓
🏎️ 2023 Benchmarks announced: Pathway is the fastest data processing engine on the market. 90x faster than existing streaming solutions (Flink, Spark, Kafka Streams).
https://t.co/vYmRFB7vqx
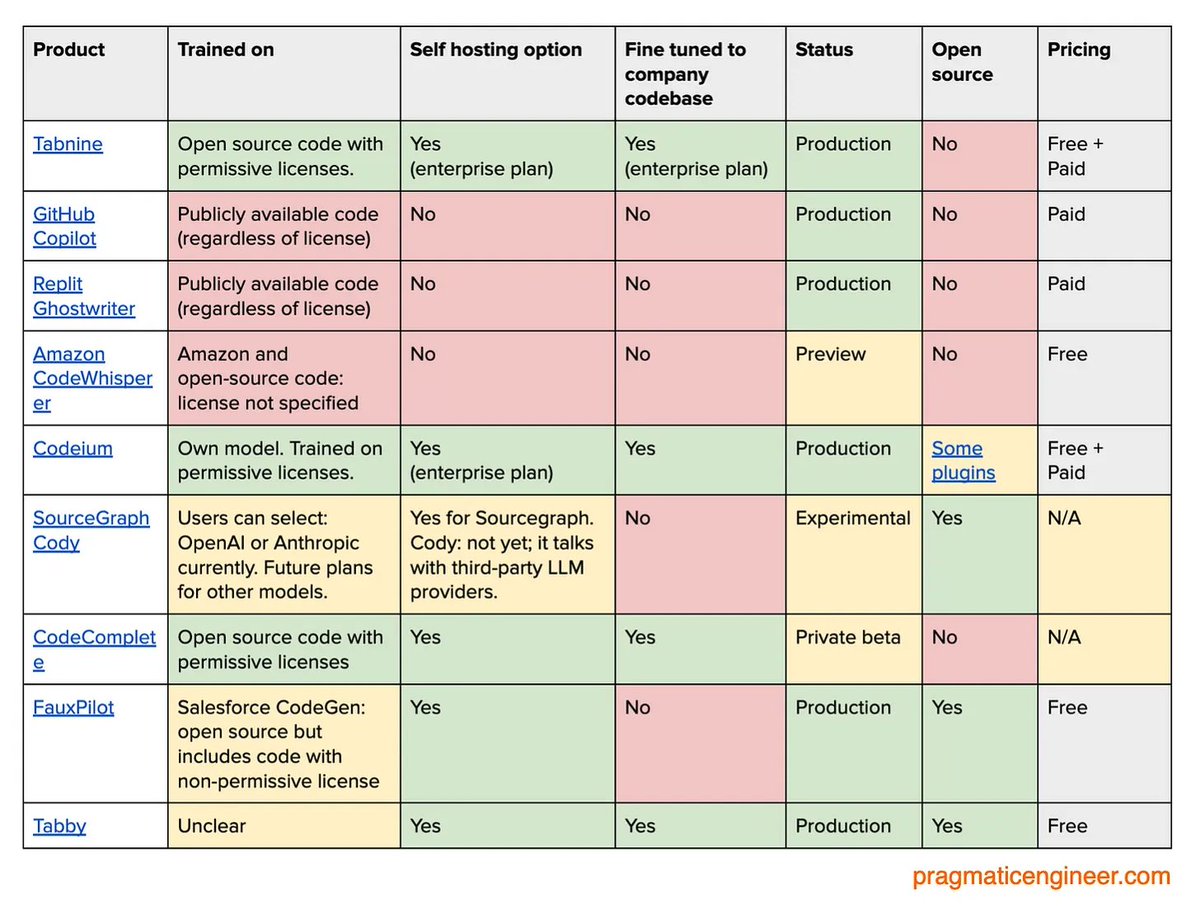
Alternatives to GitHub Copilot, and some of their characteristics.
Re-posting as my earlier share had a few inaccuracies (namely: Codeium does not train on non-permissive licenses, as they detailed here: https://t.co/okB85JiUx0)
More: https://t.co/9DCPT0u4UJ
Very happy to share our $4.5M funding round! Pathway - the programming framework which handles streaming data updates for you, is now open to all developers!
Thanks to our enterprise clients, our brilliant team, and our investors for joining the ride!
https://t.co/6kFZqubY5M
HyperFormula is out! 🎉 It is an open-source, high-performance calculation engine for web apps. We wrote it from scratch in TypeScript. Read about how we made it: https://t.co/I2TwOmBUWw
@JavaScriptDaily@typescript@kentcdodds#typescript
https://t.co/eKgYUPbX8U
@Ryslaw Zastanawiam się nad Questem, ale głównie do grania w steam vr. Najbardziej mi zależy na inside-out Jak się ma jakość VD i Oculus Link do Rift S według Ciebie? Jest sens jeszcze rozważać ten ostatni?