@RamaswmySridhar With GLM + Fireworks + Pi harness we are seeing ~98% cache reuse.
A low cache hit rate is usually a harness issue. Maybe this is the coco optimization you are teasing?
@quick007YT Yes, good reference and related but our data represents merge outcomes, e.g. the issues found during code review that are hard to encode in tests.
https://t.co/1Avppe90fA
@gianwirth Ya, DeepSWE is a test-based eval. We find passing tests to be a weak proxy for code quality
We measure what code is merged into real codebases. This evals things hard to encode in tests (whether the code is idiomatic, aligned w existing codebase patterns, overengineered, etc.)
An interesting result...
We've found that every GPT-5.5 variant has a better and cheaper alternative:
- 5.5 → 5.4 high
- 5.5 high → 5.4 xhigh
- 5.5 xhigh → GLM-5.2 max
In 2/3 cases, just drop to the cheaper model and increase reasoning
@gianwirth Ya, DeepSWE is a test-based eval. We find passing tests to be a weak proxy for code quality
We measure what code is merged into real codebases. This evals things hard to encode in tests (whether the code is idiomatic, aligned w existing codebase patterns, overengineered, etc.)
@filicroval Looking more deeply into this now, actually
Roughly, we find, over this data:
- 5.5 is ~8% more token-efficient than 5.4 at default/high (but less token-efficient at xhigh)
- GLM uses many more tokens, ~2-2.4x, but they're mostly cached reads, so very cheap
@filicroval ~600 runs across all models. 5.4 and 5.5, ~100 runs. GLM, ~10 runs (but growing)
Ratings = Bradley-Terry model on pairwise outcomes across many tasks (varied difficulty, domain, etc.)
All agentic. Run = set of coding agents implementing the same spec in its native harness
@sven2401 We measure merge outcomes on a continuously evolving test set of real SWE tasks.
So we get signal on issues that surface during code review. Most coding evals just measure whether tests pass.
At a high level, 5.5 is penalized most often for scope creep.
GLM-5.2 max debuts at #3 on the Voratiq leaderboard
The first open-weight model to compete at the top of the frontier
Since it's open-weight, this is the floor
Cost, duration, and performance are all open to improvement as well
The full GLM-5.2 deep dive just went out to subscribers
Cost, duration, the open-weight win matrix, methodology
Subscribe to get the next one → https://t.co/nirUKjy3Xf
After more head-to-head matches
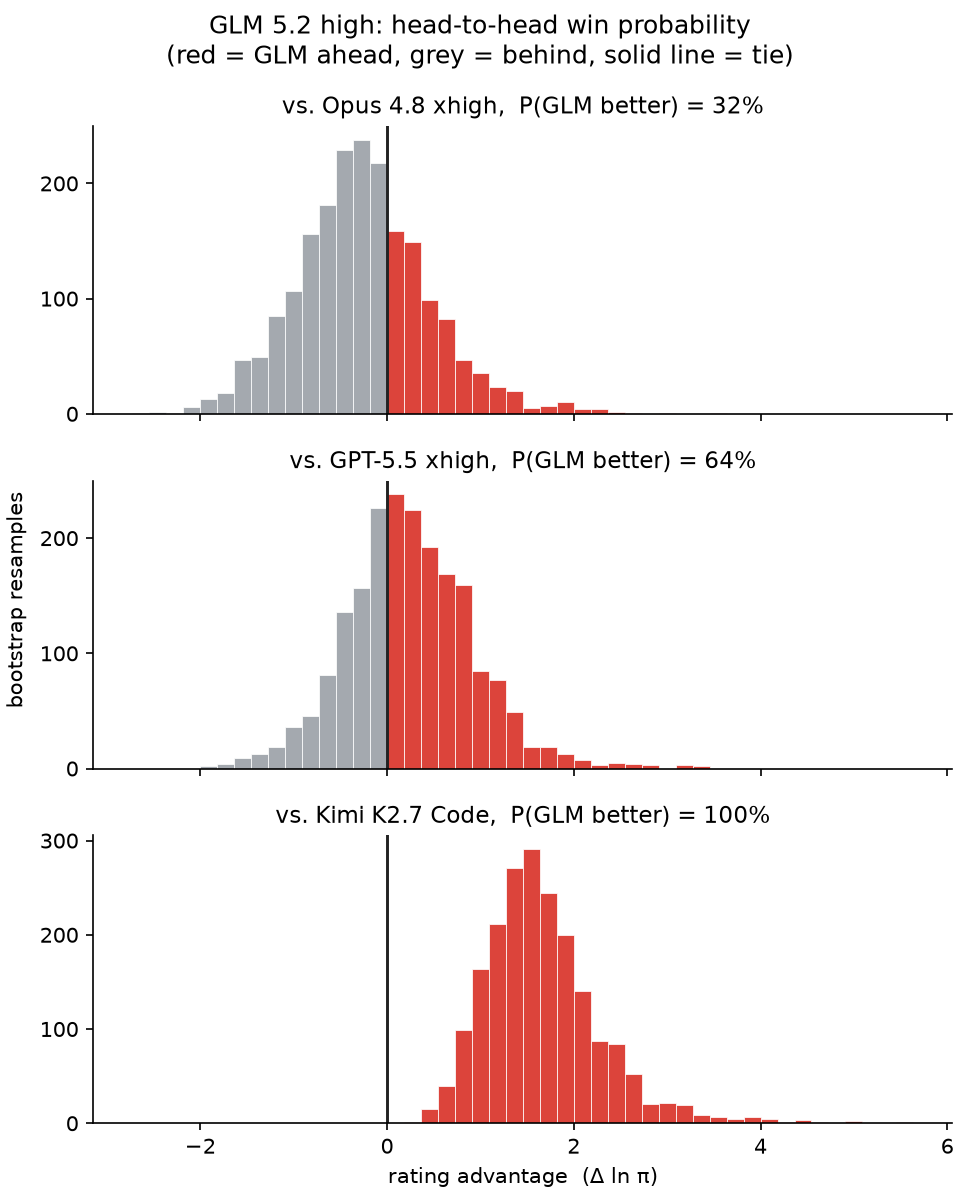
We're finding GLM 5.2 high to be ... quite good
Probability it beats:
- Opus 4.8 xhigh: 32%
- GPT-5.5 xhigh: 64%
- Kimi K2.7 Code (next-best open): 100%
Current best-estimate rank: 3rd of 56
After more head-to-head matches
We're finding GLM 5.2 high to be ... quite good
Probability it beats:
- Opus 4.8 xhigh: 32%
- GPT-5.5 xhigh: 64%
- Kimi K2.7 Code (next-best open): 100%
Current best-estimate rank: 3rd of 56
Still noisy though, will keep testing!
This is all within an agentic coding context, on real SWE tasks
Of course, with more data, across more domains, results could shift
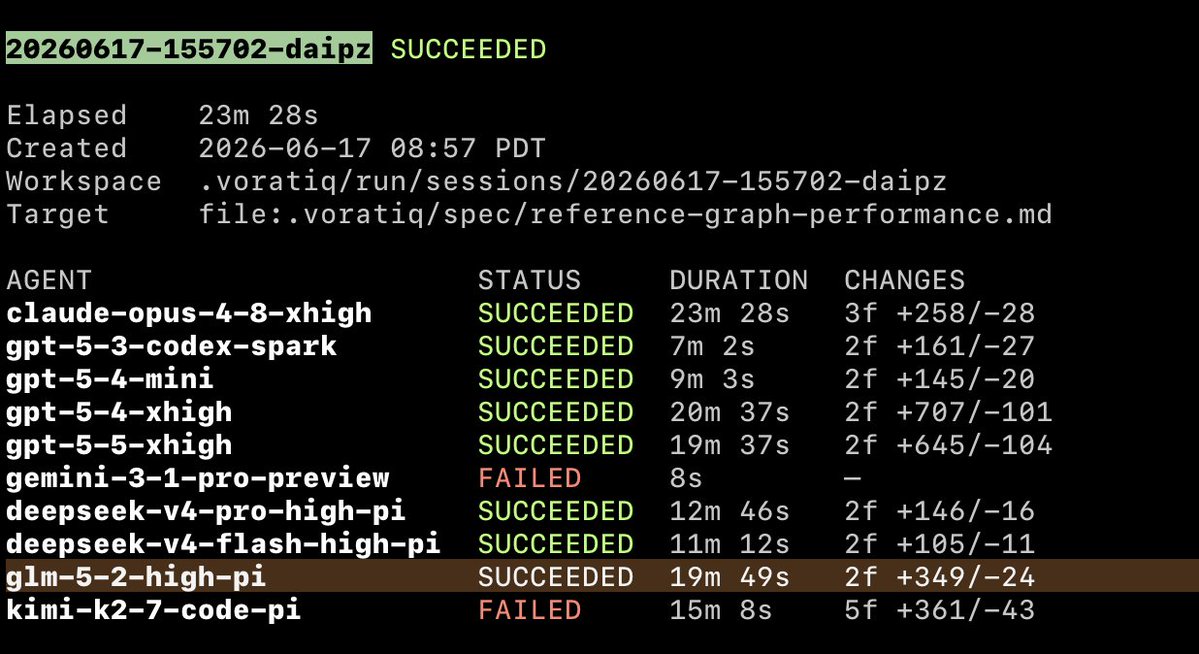
GLM 5.2 high just won head-to-head against Opus 4.8 xhigh and GPT 5.5 xhigh
The task was a tricky performance optimization in an internal code-analysis product
First time we've seen an open-weight agent outperform the top closed agents
Very interesting result...