Started writing an open-source API that calculates macros/calories from a photo or text description, grounded in real food data (USDA, Australian AFCD, Open Food Facts), not LLM estimations for cal/macros.
Works with local LLMs and cloud providers.
Results are promising.
I keep finding that for the same codebase (2.5m LOC), same prompt (describing a bug), and same model (Opus 4.6 Thinking), Cursor goes in circles for minutes (about 10) while Claude Code completes the root cause analysis in 2 minutes.
Very interested in what the coming era of highly bespoke software might look like.
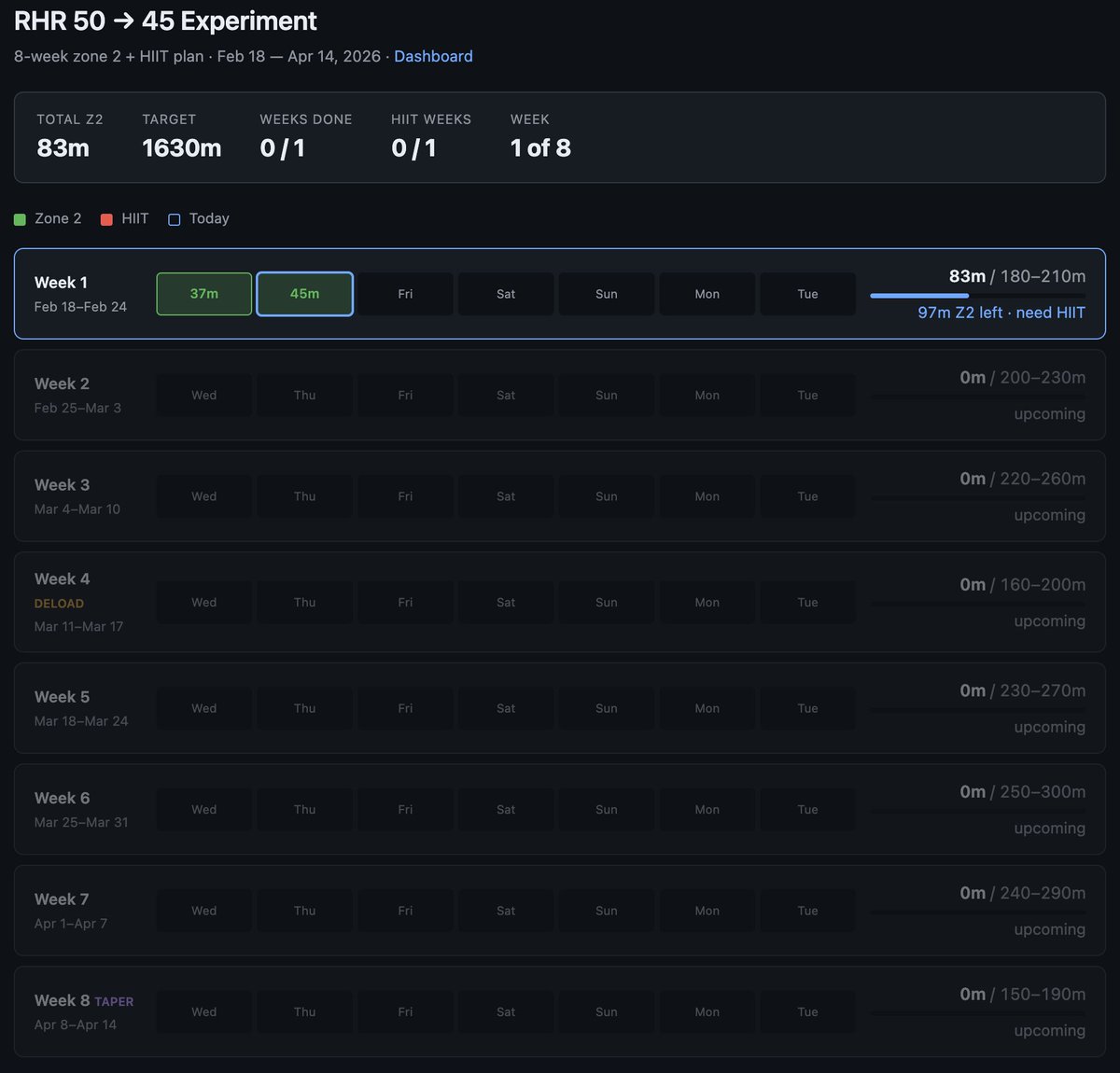
Example from this morning - I've become a bit loosy goosy with my cardio recently so I decided to do a more srs, regimented experiment to try to lower my Resting Heart Rate from 50 -> 45, over experiment duration of 8 weeks. The primary way to do this is to aspire to a certain sum total minute goals in Zone 2 cardio and 1 HIIT/week.
1 hour later I vibe coded this super custom dashboard for this very specific experiment that shows me how I'm tracking. Claude had to reverse engineer the Woodway treadmill cloud API to pull raw data, process, filter, debug it and create a web UI frontend to track the experiment. It wasn't a fully smooth experience and I had to notice and ask to fix bugs e.g. it screwed up metric vs. imperial system units and it screwed up on the calendar matching up days to dates etc.
But I still feel like the overall direction is clear:
1) There will never be (and shouldn't be) a specific app on the app store for this kind of thing. I shouldn't have to look for, download and use some kind of a "Cardio experiment tracker", when this thing is ~300 lines of code that an LLM agent will give you in seconds. The idea of an "app store" of a long tail of discrete set of apps you choose from feels somehow wrong and outdated when LLM agents can improvise the app on the spot and just for you.
2) Second, the industry has to reconfigure into a set of services of sensors and actuators with agent native ergonomics. My Woodway treadmill is a sensor - it turns physical state into digital knowledge. It shouldn't maintain some human-readable frontend and my LLM agent shouldn't have to reverse engineer it, it should be an API/CLI easily usable by my agent. I'm a little bit disappointed (and my timelines are correspondingly slower) with how slowly this progression is happening in the industry overall. 99% of products/services still don't have an AI-native CLI yet. 99% of products/services maintain .html/.css docs like I won't immediately look for how to copy paste the whole thing to my agent to get something done. They give you a list of instructions on a webpage to open this or that url and click here or there to do a thing. In 2026. What am I a computer? You do it. Or have my agent do it.
So anyway today I am impressed that this random thing took 1 hour (it would have been ~10 hours 2 years ago). But what excites me more is thinking through how this really should have been 1 minute tops. What has to be in place so that it would be 1 minute? So that I could simply say "Hi can you help me track my cardio over the next 8 weeks", and after a very brief Q&A the app would be up. The AI would already have a lot personal context, it would gather the extra needed data, it would reference and search related skill libraries, and maintain all my little apps/automations.
TLDR the "app store" of a set of discrete apps that you choose from is an increasingly outdated concept all by itself. The future are services of AI-native sensors & actuators orchestrated via LLM glue into highly custom, ephemeral apps. It's just not here yet.
yes things are changing fast, but also I see companies (even faang) way behind the frontier for no reason.
you are guaranteed to lose if you fall behind.
the no unforced-errors ai leader playbook:
For your team:
- use coding agents. give all engineers their pick of harnesses, models, background agents: Claude code, Cursor, Devin, with closed/open models. Hearing Meta engineers are forced to use Llama 4. Opus 4.5 is the baseline now.
- give your agents tools to ALL dev tooling: Linear, GitHub, Datadog, Sentry, any Internal tooling. If agents are being held back because of lack of context that’s your fault.
- invest in your codebase specific agent docs. stop saying “doesn’t do X well”. If that’s an issue, try better prompting, https://t.co/SOjpn47yxo, linting, and code rules. Tell it how you want things. Every manual edit you make is an opportunity for https://t.co/S1ZvtYQwta improvement
- invest in robust background agent infra - get a full development stack working on VM/sandboxes. yes it’s hard to set up but it will be worth it, your engineers can run multiple in parallel. Code review will be the bottleneck soon.
- figure out security issues. stop being risk averse and do what is needed to unblock access to tools.
in your product:
- always use the latest generation models in your features (move things off of last gen models asap, unless robust evals indicate otherwise). Requires changes every 1-2 weeks - eg: GitHub copilot mobile still offers code review with gpt 4.1 and Sonnet 3.5 @jaredpalmer. You are leaving money on the table by being on Sonnet 4, or gpt 4o
- Use embedding semantic search instead of fuzzy search. Any general embedding model will do better than Levenshtein / fuzzy heuristics.
- leave no form unfilled. use structured outputs and whatever context you have on the user to do a best-effort pre-fill
- allow unstructured inputs on all product surfaces - must accept freeform text and documents. Forms are dead.
- custom finetuning is dead. Stop wasting time on it. Frontier is moving too fast to invest 8 weeks into finetuning. Costs are dropping too quickly for price to matter. Better prompting will take you very far and this will only become more true as instruction following improves
- build evals to make quick model-upgrade decisions. they don’t need to be perfect but at least need to allow you to compare models relative to each other. most decisions become clear on a Pareto cost vs benchmark perf plot
- encourage all engineers to build with ai: build primitives to call models from all code bases / models: structured output, semantic similarity endpoints, sandbox code execution. etc
What else am I missing?
@candymachineatr Yes, definetely.
For now I have added a practice section in the App, which allows you to practice (by speaking out loud) the words you have saved with real world sentences.
It will also analyse your pronunciation and give a feedback.
I built the Vocabulary manager I wish I had 5 years ago.
If you read in English, you know the drill
Find a new word/ phrase
Google it
Forget it 10 minutes later 🤦♂️
Voqi breaks that loop. Search, translate, and organize your vocabulary into word lists.
#BuildInPublic#Vocabulary
@helderbuilds Yes, definetely.
For now I have added a practice section in the App, which allows you to practice (by speaking out loud) the words you have saved with real world sentences.
It will also analyse your pronunciation and give a feedback.
Big fan of @HevyApp 💪
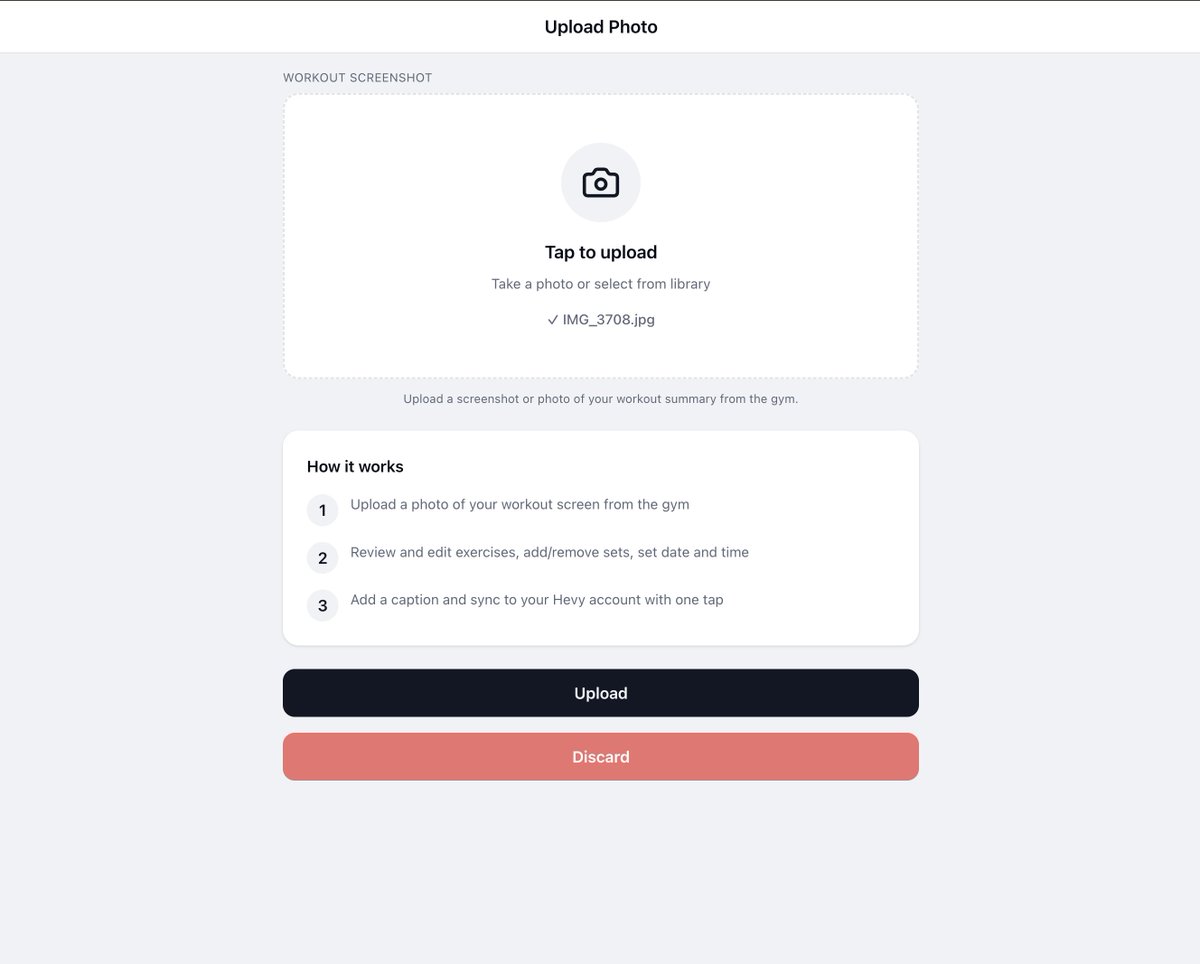
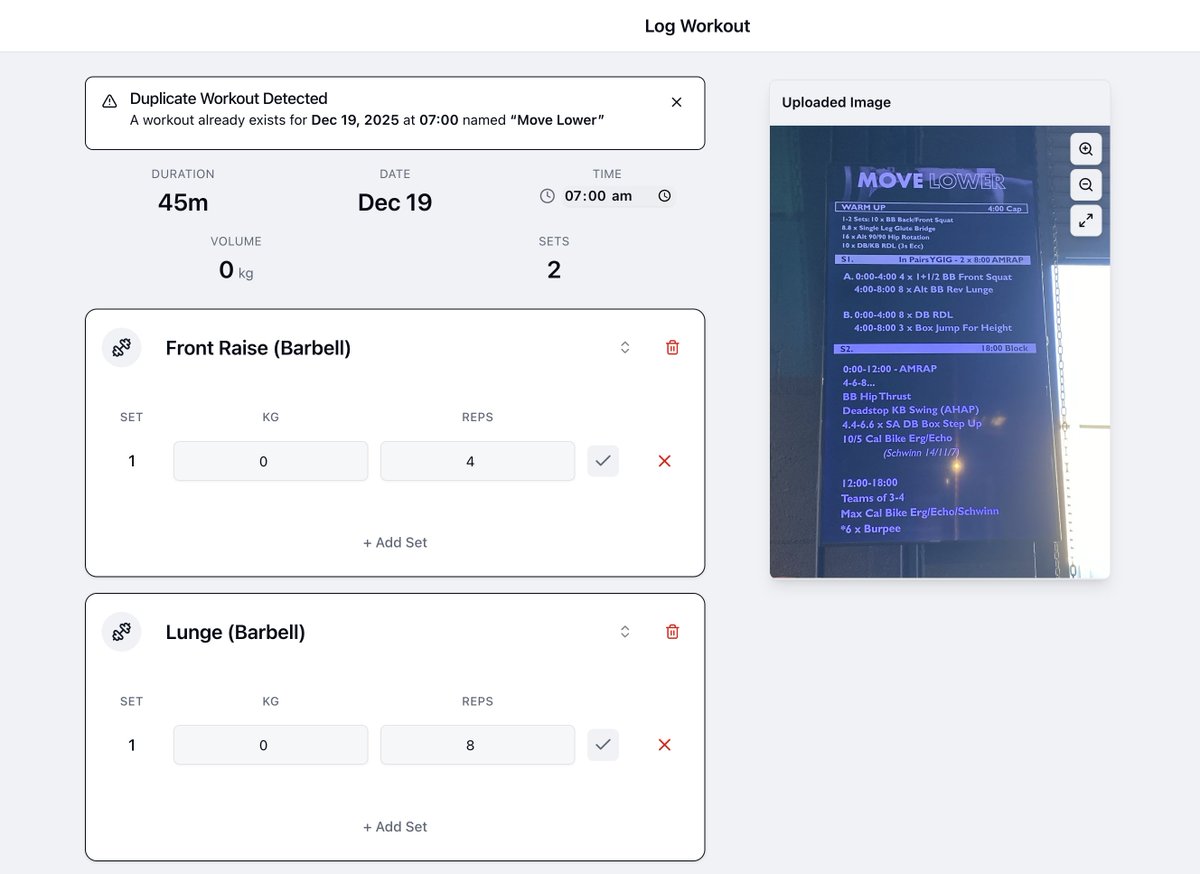
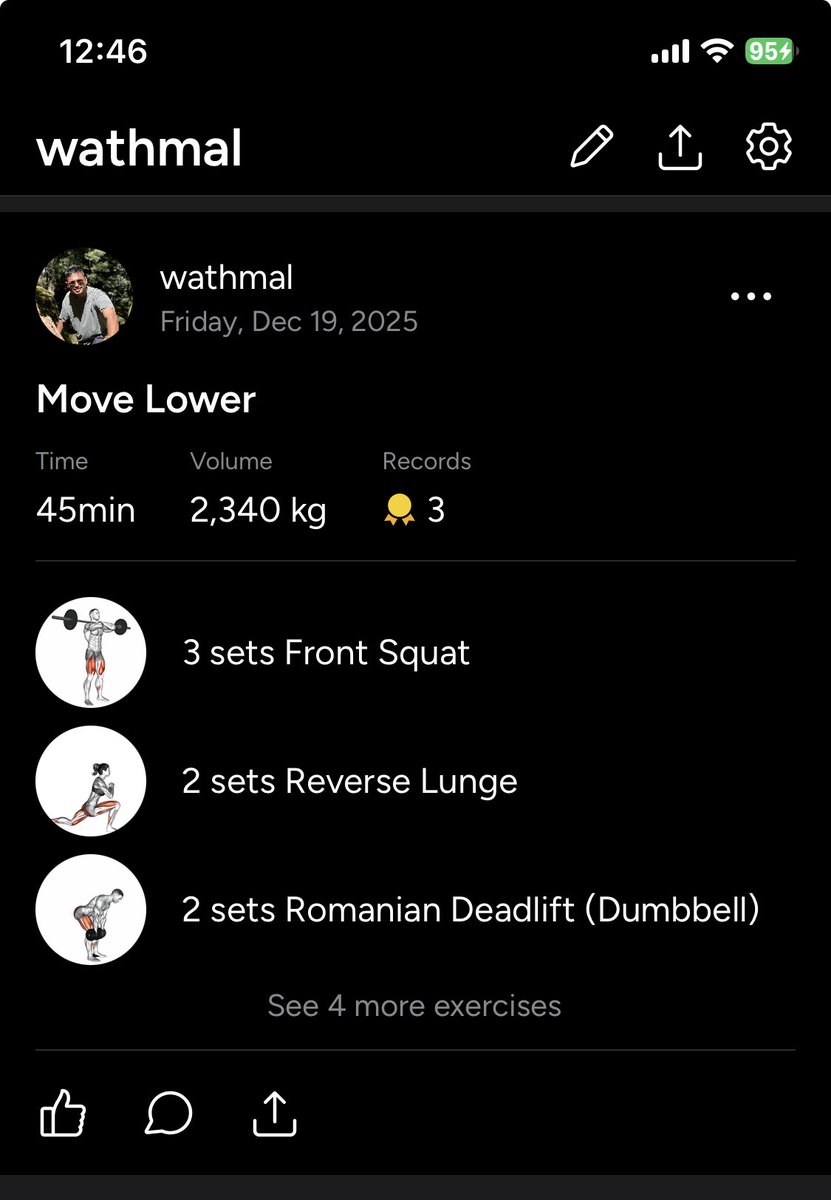
My gym shares workouts only on a TV screen when you arrive, been photographing them and logging later for years.
Built a small app that reads the image, matches the workouts, and syncs it to Hevy (weights still manual).
Scratched my own itch 🧑💻