@dpatil I'm following up on my tweet, LinkedIn message, and email about your intern idea. I've been engaged in this space for 6 years, delivered meaningful results, and would love to help program manage it.
@dpatil I saw your exciting INTERN idea on LinkedIn, and I'm curious if you need help running the project? (ceo, chief-of-staff, or program manager).
https://t.co/Yf8Y6talgw
@karenfinerman you @timseymour are my favorite panelists. Do y'all follow @benthompson or his close friends, the best tech analysts IMHO? Would love to see him interact with y'all, and next to Dan Ives, Gene Munster, any of the other regulars.
🚀 Today we’re launching a brand new @relay! If you want an AI team that works for you, now’s the time to start.
Here’s what makes our AI agents different:
Anyone can create agents. You work with AI agents just like you work with people. You ask your agent to do things for you and give it feedback to get better. No code, JSON, terminal, or MCP needed.
Agents are predictable and reliable. You teach your agent skills with simple prompts, and it turns those into easily understandable, consistent workflows. Plus, your agent can keep a human-in-the-loop for anything high stakes. No random actions you can’t explain.
To try it out, head over to @relay and get started for free. I can’t wait to hear your feedback.
p.s. like and RT to get a bonus code for 500 extra AI credits per month for a year. 🙏
@XcelEnergyCO powers out in Greenwood village, as is your phone system, website, and outtage map. Running a world class operation over there. When will this be fixed?
@lyft I have 2 Chase Sapphire promos this month that weren't applied to recent rides. Your AI support wasted my time. Now I'm waiting for 10 minutes for a terrible agent experience. Can you please dm me to expedite fixing this error, and helping prevent it from happening again?
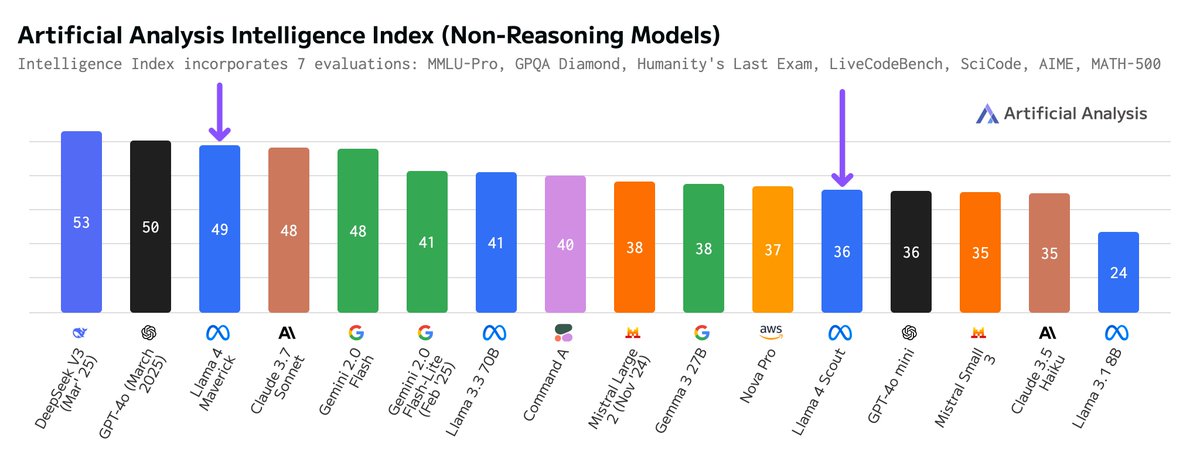
Llama 4 independent evals: Maverick (402B total, 17B active) beats Claude 3.7 Sonnet, trails DeepSeek V3 but more efficient; Scout (109B total, 17B active) in-line with GPT-4o mini, ahead of Mistral Small 3.1
We have independently benchmarked Scout and Maverick as scoring 36 and 49 in Artificial Analysis Intelligence Index respectively. Key results:
➤ Maverick sits ahead of Claude 3.7 Sonnet but behind DeepSeek’s recent V3 0324
➤ Scout sits in line with GPT-4o mini, ahead of Claude 3.5 Sonnet and Mistral Small 3.1
➤ Compared to DeepSeek V3, Llama 4 Maverick has ~half the active parameters (17B vs 37B), and ~60% of the total parameters (402B vs 671B). This means that Maverick achieves its score much more efficiently than DeepSeek V3. Maverick also supports image inputs, while DeepSeek V3 does not
➤ Both Maverick and Scout place consistently across evals, with no obvious weaknesses across general reasoning, coding and maths
Key model details:
➤ The Llama 4 ‘herd’ includes Scout, Maverick and Behemoth; all are large Mixture of Experts (MoE) models - the first time that Meta has released MoE models
➤ Behemoth (2T total, 288B active) is not being released today but Meta discloses that it was used for co-distillation into Scout and Maverick
➤ Multimodal: All three models take Text and Image input, natively trained on image inputs (this likely varies from Meta’s adapter approach in Llama 3.2). They can take multiple images, and Meta claims they should work well with up to 8 images - stay tuned for visual reasoning benchmarks next week!
➤ Pricing: We’re tracking 6 providers and are benchmarking a median price $0.24/$0.77 per million input/output tokens for Maverick, and $0.15/$0.4 for Scout lower than DeepSeek v3 and >10X cheaper than OpenAI’s leading GPT-4o endpoint
➤ Long context: Maverick supports a 1M token context window, Scout supports a 10M token context window - we will be monitoring availability of long context capabilities across providers and testing in greater detail in the coming days
➤ Style: In our early testing we have noticed responses are a lot more structured and uniform in their approach across prompts
Key training details:
➤ Pre-training: Maverick is trained on ~22T tokens, and Scout on ~40T; Meta also shared the overall training dataset was >30T tokens (more than double Llama 3’s 15T, Llama 2 was only 1.8T) of more diverse data than previously (text, images, video stills)
➤ Post-training: Involved supervised fine-tuning, online reinforcement learning (RL), and direct preference optimization techniques to optimize performance. Meta shared that they achieved “a step change in performance” by filtering the dataset to focus on ‘hard’ prompts which improved coding, math and scientific reasoning capabilities
➤ Meta disclosed training consumed 1,999 tons of CO2, this represents ~99,950 oak tree-years 🌲
One note from our evals: we note that our results for multi-choice evals (MMLU Pro and GPQA Diamond) are materially lower than Meta’s claimed results. The key driver of the difference appears to be that Scout and Maverick frequently fail to follow our answer formatting instruction. We request an answer format of ‘Answer: A’.
Full details of our prompts and answer extraction techniques are available in our methodology disclosure.
Further analysis below 👇