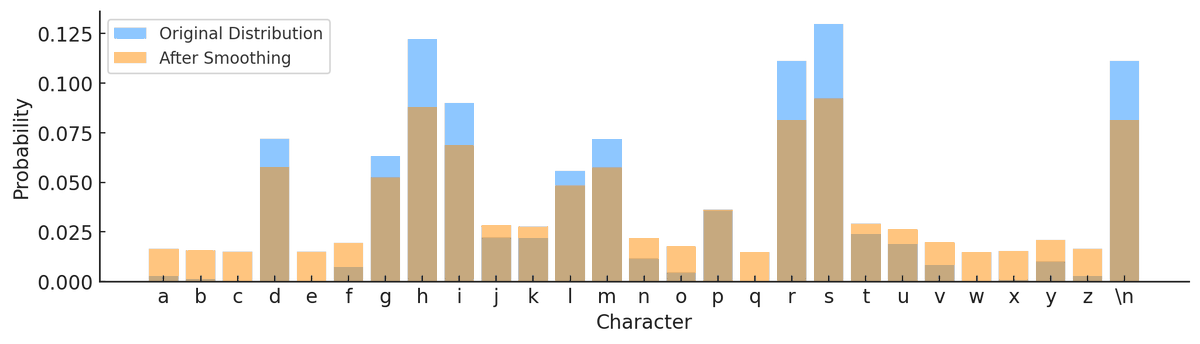LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
This github repo is a goldmine.
3.4K Starts ⭐️ in 4 days.
end-to-end, code-first tutorials covering every layer of production-grade GenAI agents, guiding you from spark to scale with proven patterns and reusable blueprints for real-world launches.
Today, we're releasing a new paper – One-Minute Video Generation with Test-Time Training.
We add TTT layers to a pre-trained Transformer and fine-tune it to generate one-minute Tom and Jerry cartoons with strong temporal consistency.
Every video below is produced directly by the model in a single shot, without editing, stitching, or post-processing. Every story is newly created.
Demos: https://t.co/BSHsucizoG
Paper: https://t.co/agJKUAExpz
@karpathy I tried to make a mock version of TikTok with Expo (without knowing react native) using Cursor.
Even better experience. I had to use Anthropic console to analyze the screenshot first, to provide design language and dir trees tho.
Today, we release several Moshi artifacts: a long technical report with all the details behind our model, weights for Moshi and its Mimi codec, along with streaming inference code in Pytorch, Rust and MLX. More details below 🧵 ⬇️
Paper: https://t.co/mMInmjiBIC
Repo: https://t.co/PFak47FMrm
HuggingFace: https://t.co/bqG4IS0ntg
# RLHF is just barely RL
Reinforcement Learning from Human Feedback (RLHF) is the third (and last) major stage of training an LLM, after pretraining and supervised finetuning (SFT). My rant on RLHF is that it is just barely RL, in a way that I think is not too widely appreciated. RL is powerful. RLHF is not. Let's take a look at the example of AlphaGo. AlphaGo was trained with actual RL. The computer played games of Go and trained on rollouts that maximized the reward function (winning the game), eventually surpassing the best human players at Go. AlphaGo was not trained with RLHF. If it were, it would not have worked nearly as well.
What would it look like to train AlphaGo with RLHF? Well first, you'd give human labelers two board states from Go, and ask them which one they like better:
Then you'd collect say 100,000 comparisons like this, and you'd train a "Reward Model" (RM) neural network to imitate this human "vibe check" of the board state. You'd train it to agree with the human judgement on average. Once we have a Reward Model vibe check, you run RL with respect to it, learning to play the moves that lead to good vibes. Clearly, this would not have led anywhere too interesting in Go. There are two fundamental, separate reasons for this:
1. The vibes could be misleading - this is not the actual reward (winning the game). This is a crappy proxy objective. But much worse,
2. You'd find that your RL optimization goes off rails as it quickly discovers board states that are adversarial examples to the Reward Model. Remember the RM is a massive neural net with billions of parameters imitating the vibe. There are board states are "out of distribution" to its training data, which are not actually good states, yet by chance they get a very high reward from the RM.
For the exact same reasons, sometimes I'm a bit surprised RLHF works for LLMs at all. The RM we train for LLMs is just a vibe check in the exact same way. It gives high scores to the kinds of assistant responses that human raters statistically seem to like. It's not the "actual" objective of correctly solving problems, it's a proxy objective of what looks good to humans. Second, you can't even run RLHF for too long because your model quickly learns to respond in ways that game the reward model. These predictions can look really weird, e.g. you'll see that your LLM Assistant starts to respond with something non-sensical like "The the the the the the" to many prompts. Which looks ridiculous to you but then you look at the RM vibe check and see that for some reason the RM thinks these look excellent. Your LLM found an adversarial example. It's out of domain w.r.t. the RM's training data, in an undefined territory. Yes you can mitigate this by repeatedly adding these specific examples into the training set, but you'll find other adversarial examples next time around. For this reason, you can't even run RLHF for too many steps of optimization. You do a few hundred/thousand steps and then you have to call it because your optimization will start to game the RM. This is not RL like AlphaGo was.
And yet, RLHF is a net helpful step of building an LLM Assistant. I think there's a few subtle reasons but my favorite one to point to is that through it, the LLM Assistant benefits from the generator-discriminator gap. That is, for many problem types, it is a significantly easier task for a human labeler to select the best of few candidate answers, instead of writing the ideal answer from scratch. A good example is a prompt like "Generate a poem about paperclips" or something like that. An average human labeler will struggle to write a good poem from scratch as an SFT example, but they could select a good looking poem given a few candidates. So RLHF is a kind of way to benefit from this gap of "easiness" of human supervision. There's a few other reasons, e.g. RLHF is also helpful in mitigating hallucinations because if the RM is a strong enough model to catch the LLM making stuff up during training, it can learn to penalize this with a low reward, teaching the model an aversion to risking factual knowledge when it's not sure. But a satisfying treatment of hallucinations and their mitigations is a whole different post so I digress. All to say that RLHF *is* net useful, but it's not RL.
No production-grade *actual* RL on an LLM has so far been convincingly achieved and demonstrated in an open domain, at scale. And intuitively, this is because getting actual rewards (i.e. the equivalent of win the game) is really difficult in the open-ended problem solving tasks. It's all fun and games in a closed, game-like environment like Go where the dynamics are constrained and the reward function is cheap to evaluate and impossible to game. But how do you give an objective reward for summarizing an article? Or answering a slightly ambiguous question about some pip install issue? Or telling a joke? Or re-writing some Java code to Python? Going towards this is not in principle impossible but it's also not trivial and it requires some creative thinking. But whoever convincingly cracks this problem will be able to run actual RL. The kind of RL that led to AlphaGo beating humans in Go. Except this LLM would have a real shot of beating humans in open-domain problem solving.
STORM by @angelina_magr @MehdiAllahyari
Implementation of the paper STORM (Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking) -- uses Claude + sub-agents to write long-form articles.
https://t.co/ewIunYS2a6
Introducing MetaGPT's Data Interpreter: Open Source and Better "Devin".
Data Interpreter has achieved state-of-the-art scores in machine learning, mathematical reasoning, and open-ended tasks, and can analyze stocks, imitate websites, and train models.
Data Interpreter is an autonomous agent that uses notebook, browser, shell, stable diffusion, and any custom tool to complete tasks.
It can debug code by itself, fix failures by itself, and solve a large number of real-life problems by itself.
We open-source our code and provide a wealth of working examples to give everyone access to state-of-the-art AI capabilities.
📝 Paper: https://t.co/VcoeKc6A8S
🔗 Examples: https://t.co/mu3iULDZko
📚 Repo: https://t.co/BMJxhVwzn6
📖 How to use: https://t.co/CviB6jvQ49
#MetaGPT #github #interpreter #opensource
I compiled a prompt engineering "best practices and tricks" doc 😀
Created based on OpenAI @isafulf's prompt engineering talk at @NeurIPSConf and enriched with more details, examples, and tips.
I focused on making the document as comprehensive and concise as possible, and it covers:
> how to write clear/specific instructions
> giving the model time to think
> prompting multiple times
> guiding the model
> breaking down the prompt
> external tools
This document is a work in progress and ideally can become a helpful resource/reminder. Any feedback or additions are appreciated ❤️.
Special thanks to @swyx, @brianryhuang, and @jerryjliu0 for their feedback and additions.
** note: these are good tips for regular human communication as well 😉
full doc: https://t.co/gNaCwuPAYo
Apple finally open-sourced σReparam.
stabilizes transformer training in PyTorch and JAX.
fantastic work by the whole team. and thanks @jramapuram for chasing this up!
https://t.co/5rMORzceiB
There's too much happening right now, so here's just a bunch of links
GPT-4 + Medprompt -> SOTA MMLU
https://t.co/Jkp96izfec
Mixtral 8x7B @ MLX nice and clean
https://t.co/75StzY5AHe
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
https://t.co/gOCWjfY7ec
Phi-2 (2.7B), the smallest most impressive model
https://t.co/Fps8tI5QVi
LLM360: Towards Fully Transparent Open-Source LLMs
https://t.co/l6E16GfdIN
Honorable mentions
https://t.co/7GQqiCGHRH
https://t.co/3GZrYPp9KP
https://t.co/Su8iiDksMZ
Happy to OSS gpt-fast, a fast and hackable implementation of transformer inference in <1000 lines of native PyTorch with support for quantization, speculative decoding, TP, Nvidia/AMD support, and more!
Code: https://t.co/REjeKUUwjF
Blog: https://t.co/esIhj2ioT4
(1/12)
There’s a single formula that makes all of your diffusion models possible: Tweedie's
Say 𝐱 is a noisy version of 𝐮 with 𝐞 ∼ 𝒩(𝟎, σ² 𝐈)
𝐱 = 𝐮 + 𝐞
MMSE estimate of 𝐮 is 𝔼[𝐮 | 𝐱] and would seem to require P(𝐮|𝐱). Yet Tweedie says P(𝐱) is all you need
1/3
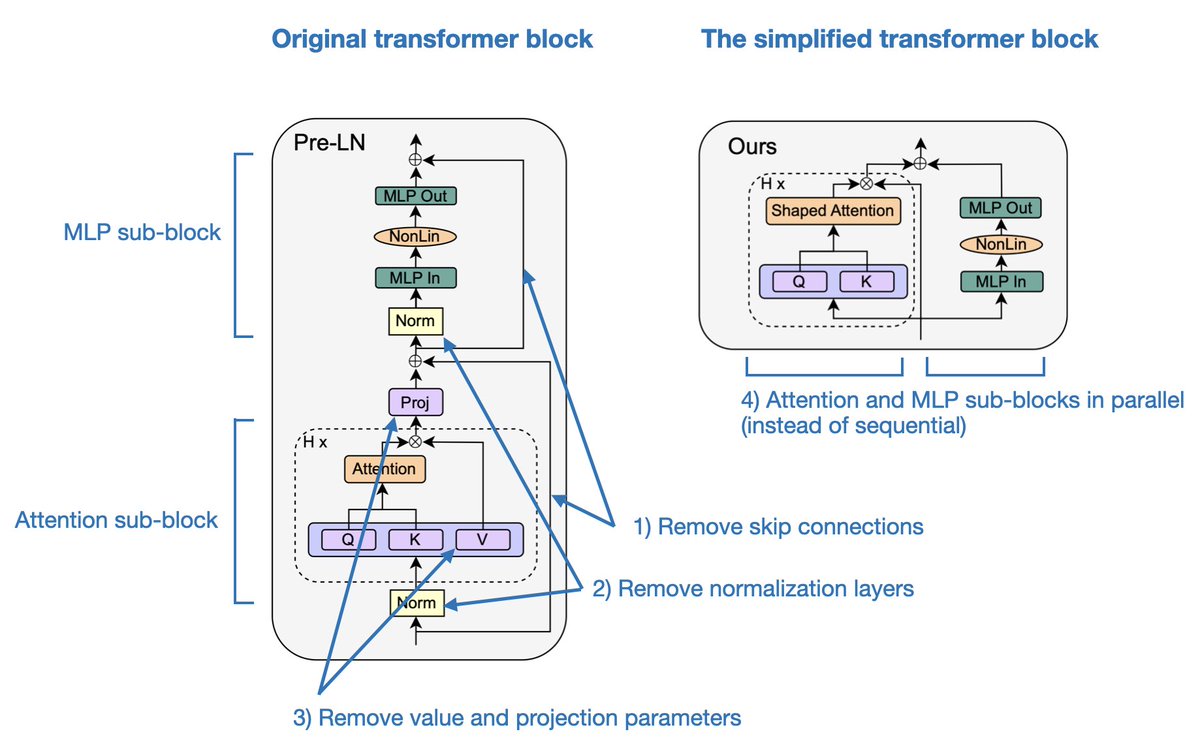
"Simplifying Transformer Blocks" ranks easily among my favorite research papers that I've read this year.
Here, the authors look into how the standard transformer block, essential to LLMs, can be simplified without compromising convergence properties and downstream task performance.
Based on signal propagation theory and empirical evidence, they find that many parts can be removed to simplify GPT-like decoder architectures as well as encoder-style BERT models:
skip connections
normalization layers (LayerNorm)
projection and value parameters
sequential attention and MLP sub-blocks (in favor of a parallel layout)
The authors also did a great job referencing tons of related work motivating their experiments. I definitely recommend reading this paper just for the references alone: https://t.co/9nDvsW0yoj
You thought that you can go to sleep now??
Orca 2 Just dropped.
Paper: https://t.co/6AFP3I6WWa
Results:
Orca 2 13B beats LLaMA-Chat-70B
TL;DR:
Training smaller model to reason by using multiple techniques:
step-by-step, recall then generate, recall-reason-generate, direct answer
And determining the most effective solution strategy for each task.
ChatGPT "Advanced Data Analysis" (which doesn't really have anything to do with data specifically) is an awesome tool for creating diagrams. I could probably code these diagrams myself, but it's soo much better to just sit back, and iterate in English.
In this example, I was experimenting with a possible diagram to explain Supervised Finetuning in LLMs. The "document" at the origin (0,0) is the empty document, and eminating outwards are token streams. Highlighted in black are the high probability token streams of the base model. In red are the token streams corresponding to the conversational finetuning data. When we finetune, we are increasing the probabilities of the red paths and suppressing the black paths. I like this view because it emphasizes LLMs as "token simulators", with their own kind of statistical physics backed by datasets, bouncing around in the discrete token space.
The conversation where we built it in a few minutes:
https://t.co/BPYipeQWws
(Sadly I just remembered that ChatGPT sharing doesn't support images, but at least the text is there, of me iterating with the diagram in plain language, and needing to touch no code. Such a vibe of the future.)
I had a similar experience yesterday, was trying to create a plot that shows smoothing in n-gram language models. Again I could just have coded this manually, but this was 10X faster and so easy.
Conversation:
https://t.co/MTxD2YH6Kv
Posting because during these chats I was struck again by that feeling of what must be the future, where you just sit back and say stuff, and the computer is doing the hard work. And in some narrow pockets of tasks, you can already get that feeling today.
🥳Detecting Everything in the Open World: Towards Universal Object Detection @CVPR#CVPR2023
🤗Paper: https://t.co/tqz8vkUPPj
🤗Code: https://t.co/ExnlahaFEa
☺️Based on #MMDetection
🔥MoCap Anybody🔥
#NeurIPS2023 We propose *SMPLer-X*, the first generalist foundation model for 3D/4D human motion capture from monocular inputs.
- Project: https://t.co/c9Ee60UUyk
- Paper: https://t.co/84iGK1wmVg
- Code: https://t.co/VWcxxhh3Gt
- Demo: https://t.co/aLV4l4WsoX











































![docmilanfar's tweet photo. There’s a single formula that makes all of your diffusion models possible: Tweedie's
Say 𝐱 is a noisy version of 𝐮 with 𝐞 ∼ 𝒩(𝟎, σ² 𝐈)
𝐱 = 𝐮 + 𝐞
MMSE estimate of 𝐮 is 𝔼[𝐮 | 𝐱] and would seem to require P(𝐮|𝐱). Yet Tweedie says P(𝐱) is all you need
1/3 https://t.co/aW7dHdjTed](https://pbs.twimg.com/media/F_2BtqgbcAARVyO.jpg)