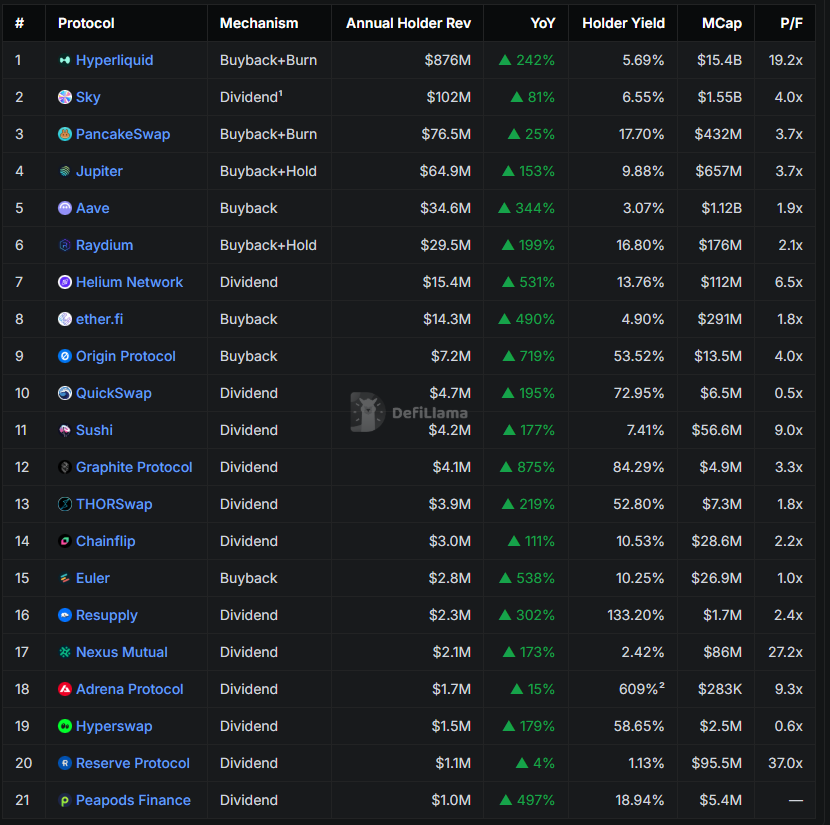
not just hyperliquid.
over 20 protocols have:
1) revenue that accrues to tokenholders
2) yoy revenue growth
3) either high holders rev in absolute terms or relative to mcap
The Bear Flag broke after the second major retest of the upper part of the channel, just as almost all of them have.
Take note of the swift moves to the downside after that happens. Usually price gets where it's going in 1 - 2 weeks.
Probably not the last one of these will see this bear market.
🚨JUST IN: Anthropic is set to give 150 organizations across 15+ countries access to its AI model Claude Mythos, per FT.
The expansion includes the US-led military alliance NATO, the US tech group Okta, the EU cybersecurity agency ENISA, and South Korean companies Samsung, SK Hynix and SK Telecom.
The hardest problem in physical AI has never been the model, it has been the data (Save this).
Language models had an extraordinary training advantage that almost no one appreciated at the time.
The entire written output of human civilization, books, articles, code, scientific papers, social media, legal documents was created by humans, from the human perspective, to be consumed by humans.
The data and the learner were perfectly aligned from day one.
Physical AI has no equivalent resource, robots experience the world from an embodied, first-person perspective sensing depth, force, position and environment from inside a physical body operating in three dimensional space.
The entire internet's video archive is almost entirely third person footage and none of it tells a robot how to orient a gripper, recalibrate on a new surface, or recover from an unexpected obstacle.
The world's largest robotics datasets combined contain roughly 5,000 hours of physical interaction data, GPT-4 trained on the equivalent of hundreds of millions of hours of text.
The data gap between language AI and physical AI is not a 10x problem but rather a 100,000x problem.
NVIDIA's answer is Cosmos 3 and it is the culmination of a three-year program specifically engineered to close that gap.
The progression Jensen described on stage mirrors exactly how reinforcement learning evolved for language models.
Teleoperation, humans physically demonstrating tasks to robots is the physical world's equivalent of RLHF.
High quality, but it scales linearly with human operators and physical robots, making it catastrophically expensive to replicate at the data volumes needed for general intelligence.
Omniverse simulation gave developers a way to generate synthetic training environments at scale, the physical world's equivalent of reinforcement learning with verifiable rewards.
But Cosmos 3 goes beyond both.
It is a unified omnimodel built on a novel Mixture of Transformers architecture, two parallel towers, one autoregressive and one diffusion trained on 20 trillion tokens of multimodal data, nearly one billion images, 400 million real and synthetic videos, spatial audio, text, and action data from both humans and robots.
The critical breakthrough is perspective invariance.
Cosmos 3 can take third-person footage that exists in abundance and reproject it into first-person perception data that robots can actually learn from.
A security camera recording of someone picking up a box, filmed from above and at an angle, can now be translated into the first-person sensory experience a robot arm needs to learn that same task.
This is the removal of the single most fundamental constraint on physical AI scaling.
Cosmos 3 opens the door to general-purpose robotic intelligence trained cheaply, updated continuously, and deployed across the physical environments, factories, warehouses, hospitals, construction sites, agriculture that represent the overwhelming majority of global GDP output.
The data center buildout is wave one, physical AI is wave two and the GPU demand that wave two will generate as hundreds of billions of agentic systems come online is an order of magnitude larger than anything wave one has produced.
Come join Milk Road Pro and get our full framework for tracking the physical AI buildout including how we think about the Cosmos 3 ecosystem, which supply chain companies we believe will compound fastest as the data bottleneck breaks, and why we believe the GPU cycle is entering its most explosive phase, not approaching its peak.
Link below!
Artificial Analysis and IBM Research are launching ITBench-AA, the first in a new series of benchmarks evaluating models on agentic enterprise IT tasks, starting with Site Reliability Engineering tasks where frontier models score below 50%
ITBench-AA’s SRE tasks benchmark model performance on Kubernetes incident response, where models must diagnose live systems by reading logs, tracing dependencies, and identifying root-cause entities across complex infrastructure. The underlying ITBench dataset has been developed by @IBM's Software Innovation Lab, leveraging IBM’s deep expertise in enterprise IT operations
Artificial Analysis has worked closely with IBM over the last 6 months to develop a implementation of the dataset for frontier AI evaluation, beginning with Site Reliability Engineering (SRE) and expanding to Financial Operations (FinOps) and Chief Information Security Officer (CISO) tasks over time
ITBench-AA SRE overview:
➤ 59 SRE tasks in total: 40 public tasks and 19 brand new, held-out tasks
➤ Each task provides a Kubernetes incident snapshot containing alerts, events, traces, metrics, logs, and application topology. The model must identify the minimal set of independent root-cause Kubernetes entities responsible for the incident
➤ Faults span typical SRE failure modes including infrastructure, service, application, and chaos-injected incidents, such as resource quota exhaustion, rollout failures, connection pool exhaustion, and network partitions
Methodology details:
➤ Agentic harness: each task is solved by the model running in our open-source Stirrup reference harness, with shell access to a sandboxed file system containing the relevant logs and snapshots. 100-turn cap per task, 3 repeats per task
➤ Models submit a list of root-cause entities (Kubernetes Deployments, Services, Pods, etc.) they believe caused the incident. Each submission is compared against a ground-truth set of root causes provided by IBM Research
➤ Scoring uses average precision at full recall: if a model misses any of the ground-truth root causes, it scores 0.0 for that repeat. If it identifies all of them, it is awarded a score equal to its precision - the share of its submitted entities that are actual root causes, i.e. true positives / (true positives + false positives). The headline score is the average across 59 tasks × 3 repeats.
➤ The harness (Stirrup) is held constant across all evaluated models, allowing an apples-to-apples comparison between models.
Key findings:
➤ Claude Opus 4.7 (Adaptive Reasoning, Max Effort) leads at 47%, followed by GPT-5.5 (xhigh) at 46% and Qwen3.7 Max at 42%
➤ All frontier models score below 50%, making ITBench-AA SRE one of the least saturated agentic benchmarks in our suite. For context, frontier models score considerably higher on Terminal-Bench
➤ Turn counts vary nearly 3x and longer trajectories do not translate to higher accuracy. GPT-5.5 (xhigh) averages 31 turns per task at 46%, while Gemini 3.1 Pro Preview averages 83 turns at 30%. Models that over-investigate tend to surface upstream fault-injection mechanisms or co-occurring symptoms as false positives
➤ GLM-5.1 (Reasoning) leads open weights models at 40%, effectively tied with Gemini 3.5 Flash (high). DeepSeek V4 Pro (Reasoning, Max Effort) follows at 38%, with Gemma 4 31B (Reasoning) at 37%, ahead of Gemini 3.1 Pro Preview at 30%
Surplus Intelligence week 1
150 models. 2,400+ suppliers. 47K+ requests. 1.77B+ tokens routed.
Inference now has a live orderbook.
Here's what the data says 👇🧵
Not $BASE, it's just @base launching its new AI MCP.
AI agents can now analyze, trade/swap/deposit, and interact with Base crypto apps.
If you're in the crypto markets, here's how to set up Base MCP with examples 🧵
Introducing Base MCP
Your agent's new gateway to Base
→ Connect an agent to your Base Account
→ Enable it to swap, trade, and manage your portfolio
→ Use plugins from leading apps on Base
The next stage of the agentic onchain economy
i have been incredibly humbled by the inability of fantasy top, friendtech and consumer crypto apps to cross the chasm. crypto in its most ambitious form (of ushering in a new era of user owned software and infrastructure) has failed.
we optimistically tried to blend the personas of investor (people allocating capital to production to receive more money than they put in) and consumer (people willing to pay more for a product than it costs to operate) and found ourselves serving the needs of neither.
where the strong form of crypto failed, the weak form (of commoditized ledger/database tech for financial transactions) has succeeded beyond anyone's expectation. the consequence is that crypto has been reduced to a vassal of traditional finance, both more impactful than any normie anticipated, and deeply disappointing in structure to crypto OGs. reducing global transaction costs as commoditized ledger/database technology reduces drag on global GDP, but this is a marginal improvement over the status quo and one where the value accrues in large part to incumbent intermediaries in reducing overhead and improving margins.
crypto was supposed to be the most egalitarian thing ever. it was insanely ambitious and, if it worked, could have really changed the fabric of society.
it didn't. it's over. we haven't found the right primitives, and, more importantly, the right culture for delivering the most ambitious version of crypto. it's time to question everything again.
99% of crypto tokens are worthless, but there's value onchain if you know where to look.
60 protocols have MCap/Revenue ratios below 15X both on 1Y revenue and annualized revenue.
Of those 60, only 32 pass on revenue to tokenholders.
Of those 32, only 6 have accelerating revenue growth.
The Bear Flag active since early February is now tied for the longest running since November 2021 at 100 days.
Price is rejecting from the top of the flag.
Again, the flag typically breaks down after the second major retest of the top, which is now complete.
The average drop after a bear flag breakdown is about 30%, but has been as low as 16% and as high as 40%.
A 30% correction from the current bear flag bottom would take Bitcoin to $50,000.
i dont think this got enough attn so reposting again.
"$GITLAWB went from $20k to $35M mcap and now has a $3.12M treasury with 53 ETH and 9.5B GITLAWB.
The founder is a talented engineer from Southeast Asia who'd probably never fit the YC profile.
The world is ready for a new YC where anyone can launch from anywhere."
read that again. no other time in history was this possible.
crypto + talent + the @bankrbot ecosystem made it possible.
Cerebras just IPO’d and the stock already ran up over 100% (Save this).
For the entire 70 year history of the semiconductor industry, every company on earth has followed the same process.
You take a dinner plate sized silicon wafer, put hundreds of tiny chips onto it, and dice it up like a pizza.
Nvidia does it this way, AMD does it this way, Intel has done it this way for six decades and everyone who tried to break that convention failed.
Until Cerebras asked the most annoyingly obvious question in the industry’s history, what if you just didn’t cut it?
The result is the Wafer Scale Engine, a single chip 56 times larger than Nvidia’s H100 and it fundamentally changes the physics of how AI inference works.
The reason this matters is not the size, it’s the bandwidth.
Every time an AI model generates a single word, it has to reach into memory, pull weights, multiply them together, and produce a prediction and when you’re running millions of concurrent sessions at once, the bottleneck is not raw processing power but how fast data moves between memory and compute.
Nvidia’s H100 moves data at roughly 3 terabytes per second, while Cerebras’ WSE-3 moves data at 21 petabytes per second, roughly 7,000 times faster because memory and compute live on the same enormous piece of silicon and data barely has to travel at all.
That gap is exactly why OpenAI went from 150 tokens per second on traditional GPUs to 2,000 tokens per second on Cerebras hardware, and why AWS integrated Cerebras into Bedrock to deliver roughly 5x more inference capacity in the same physical footprint.
The macro setup is making the trade even more urgent.
South Korea DRAM export prices recently jumped 35%, flash memory surged 47%, and SSD pricing spiked nearly 140% and every single one of those increases hits Nvidia-based infrastructure directly, because the H100 requires 80GB of the most expensive, most contested memory in the AI supply chain.
Cerebras’ WSE-3 uses zero external HBM memory, baking 44GB of SRAM directly into the wafer itself which means as memory pricing goes parabolic, every CFO evaluating AI infrastructure is suddenly looking much more seriously at the architecture that sidesteps that cost entirely.
The demand is already showing up in the backlog.
Cerebras ended 2025 with $24.6 billion in remaining performance obligations for a company doing just over $500 million in annual revenue, that is a number that implies years of contracted growth already sitting on the books.
The IPO was 20x oversubscribed, the price range was raised twice before listing, and shares opened 89% above their listing price on a $5.55 billion raise that made it the largest semiconductor IPO in history.
The risks are real and worth naming.
86% of 2025 revenue came from two entities with UAE ties, U.S. revenue actually fell 34% to $187 million, and the $20 billion OpenAI contract is conditional, if Cerebras misses delivery milestones, OpenAI can terminate and trigger repayment demands on a $1 billion loan facility.
And yet the market is valuing Cerebras at roughly 91x trailing revenue, richer than Nvidia, AMD, and Arm combined.
What investors are betting on is not that Cerebras beats Nvidia, it is that the inference supercycle is large enough to support an entirely different architecture optimized for a different workload, and that $24.6 billion in contracted backlog converts to diversified revenue before the market starts asking harder questions.
CEO Andrew Feldman said this took a decade of late nights to get right, everyone who tried to copy it failed and given that the entire inference economy is now running through exactly the bottleneck Cerebras was built to eliminate, the market is starting to believe him.
In 2026, $NVDA put $15,000,000,000 in 7 AI super companies so far.
Here's exactly why they partnered with these companies:
$MRVL Marvell → AI scaling is now bottlenecked by networking and custom silicon. Marvell solves critical data movement problems between GPUs, memory, and hyperscale systems.
$LITE Lumentum → As GPU clusters grow, optical interconnect demand explodes. Lumentum’s photonics technology helps AI systems transfer massive amounts of data with lower latency and power consumption.
$COHR Coherent → Coherent enables next-generation optical communications and advanced semiconductor materials. AI factories cannot scale efficiently without faster optical transmission technologies.
$GLW Corning
→ AI data centers need massive fiber density and ultra-fast optical connectivity. Corning supplies the backbone glass and fiber infrastructure enabling hyperscale AI clusters to communicate at scale.
$IREN IREN Limited
→ AI requires enormous amounts of cheap power and scalable compute infrastructure. IREN gives NVIDIA exposure to next-generation AI data centers with energy advantages most competitors can’t replicate.
$CRWV CoreWeave
→ CoreWeave became one of NVIDIA’s most important AI cloud partners because it aggressively buys NVDA GPUs faster than traditional hyperscalers. This expands NVIDIA’s AI compute dominance globally.
$NBIS Nebius
→ Nebius is building AI-native cloud infrastructure optimized specifically for high-performance training and inference workloads. NVIDIA benefits from another rapidly scaling ecosystem partner consuming massive GPU capacity.
3 extremely likely future NVDA partnerships:
1. $ANET Arista Networks → AI networking demand is exploding. NVIDIA + Arista together could dominate hyperscale AI traffic infrastructure.
2. $VRT Vertiv → AI data centers are running into cooling and power bottlenecks. Vertiv solves one of the biggest scaling problems for AI globally.
3. $ETN Eaton → AI power demand is becoming the next trillion-dollar bottleneck. Eaton provides the electrical infrastructure needed to sustain hyperscale AI expansion.
They’re building the entire AI empire infrastructure stack from silicon → photonics → networking → power → data centers.
PRIVACY IS MORE THAN MONEY
This is what the Kohaku project is, straight from its core contributors, @VitalikButerin and @ncsgy.
TLDR: it is a serious attempt to rethink online safety and privacy across money, AI, and life.
Let’s dive in.
🔥"CLARITY IS CLOSER THAN EVER. MARK IT UP!"
Coinbase CEO Brian Armstrong says the latest draft of the CLARITY Act is stronger than ever, with key issues from earlier versions now addressed as momentum builds around the bill.