Time to set a new standard for code retrieval, read more in our blog https://t.co/0lL99O7eSR and https://t.co/107kJG2Rqx for evaluating code retrieval. Start building with @VoyageAI today - the first 200M tokens are on us!
Voyage created a total of 238 new high-quality reasoning-intensive code retrieval datasets that address the shortcomings of existing benchmarks (noisy labels, overly simplistic tasks, and data contamination)
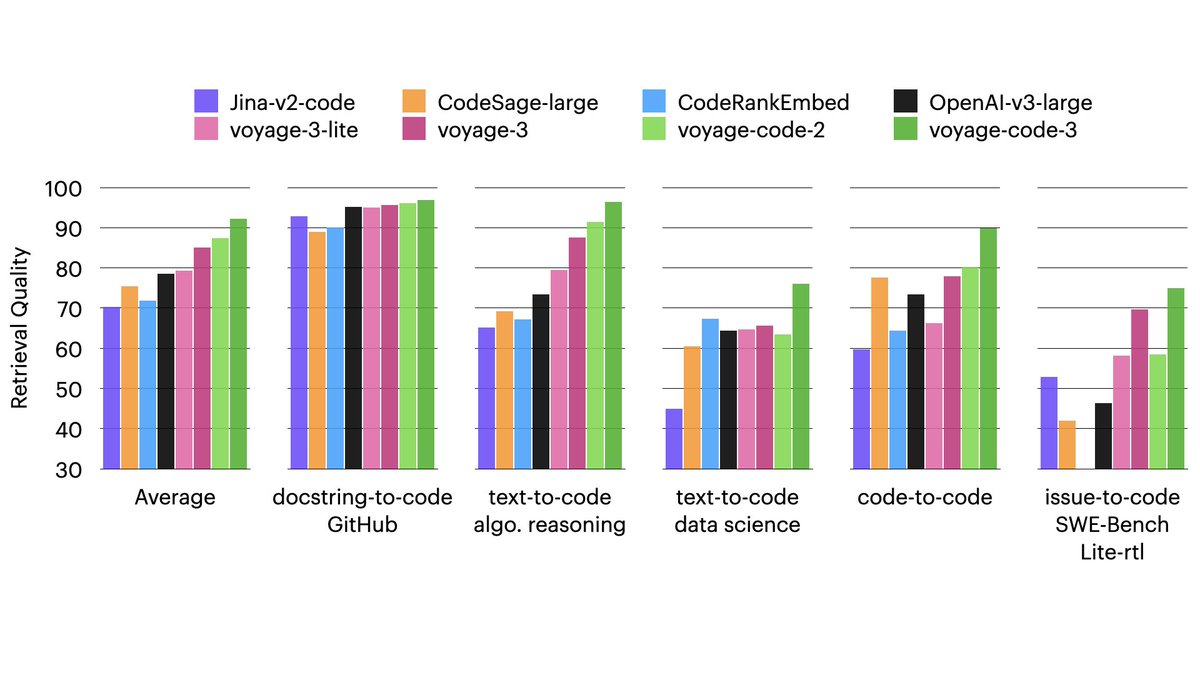
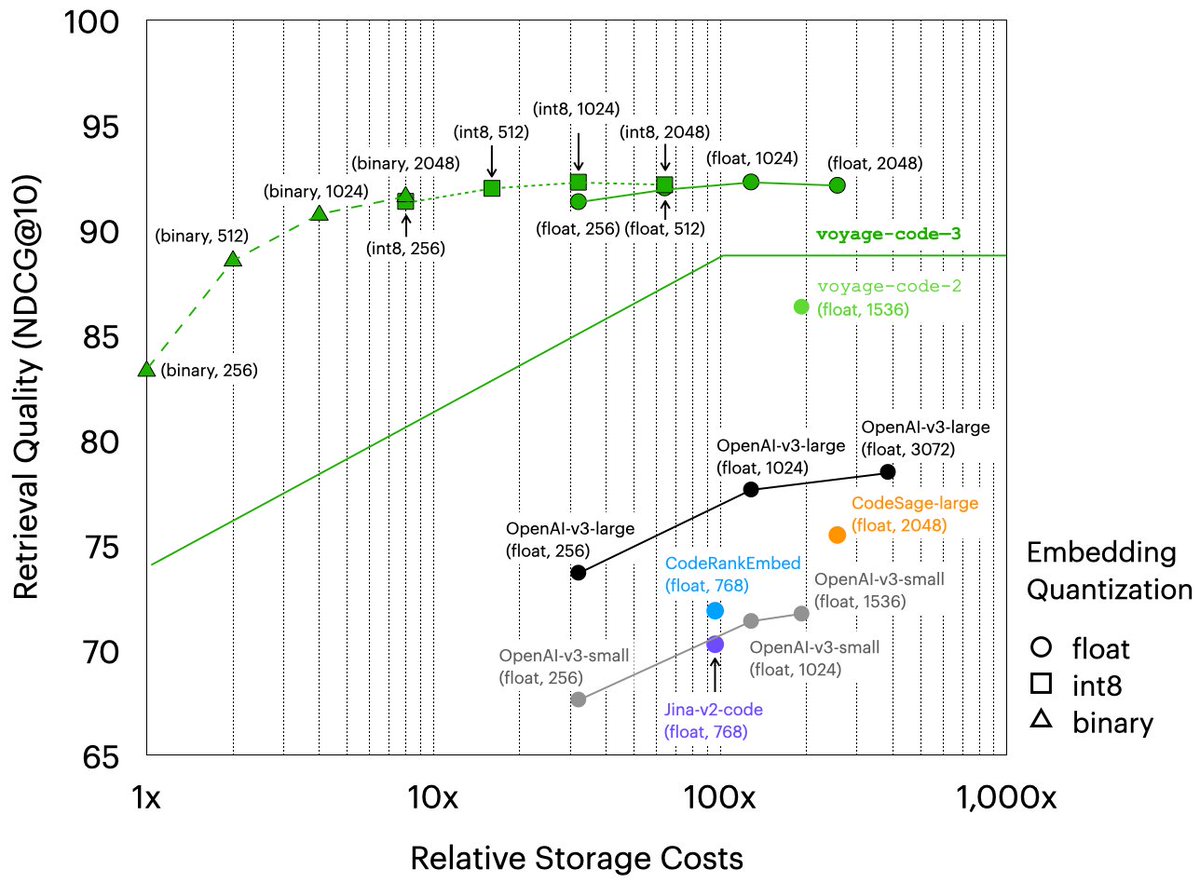
voyage-code-3 outperforms all other models in every group of datasets.
There's a new exciting reranking API from @Voyage_AI_!
It's already supported in `rerankers` v0.1.2, try it out in your pipelines!
`pip install --upgrade rerankers`
Voyage AI (@Voyage_AI_) is the newest giant in the embedding, reranking, and search model game! 🔥
I am SUPER excited to publish our latest Weaviate podcast with Tengyu Ma (@tengyuma), Co-Founder of Voyage AI and Assistant Professor at Stanford University! 🎙️
We began the interview with a deep dive into everything embedding model training and contrastive learning theory. Tengyu delivered a masterclass in all things from scaling laws to multi-vector representations, touching on ColBERT and Matryoshka embeddings, neural architectures, representation collapse, data augmentation, semantic similarity, and more! I am beyond impressed with Tengyu's extensive knowledge and explanations of all these topics. 🧠
The next chapter dives into a case study Voyage AI did fine-tuning an embedding model for the LangChain documentation. This is an absolutely fascinating example of the role of continual fine-tuning with very new concepts (for example, very few people were talking about chaining together LLM calls 2 years ago), as well as the data efficiency advances in fine-tuning. ⚙️
We concluded by discussing ML systems challenges in serving an embeddings API. Particularly the challenge of detecting if a request is for batch or query inference and the optimizations that go into either say ~100ms latency for a query embedding or maximizing throughput for batch embeddings. 🚀
YouTube: https://t.co/w5IbkqMprG
Spotify: https://t.co/YmGpnCH6y3
Rerankers refine the retrieval in RAG.
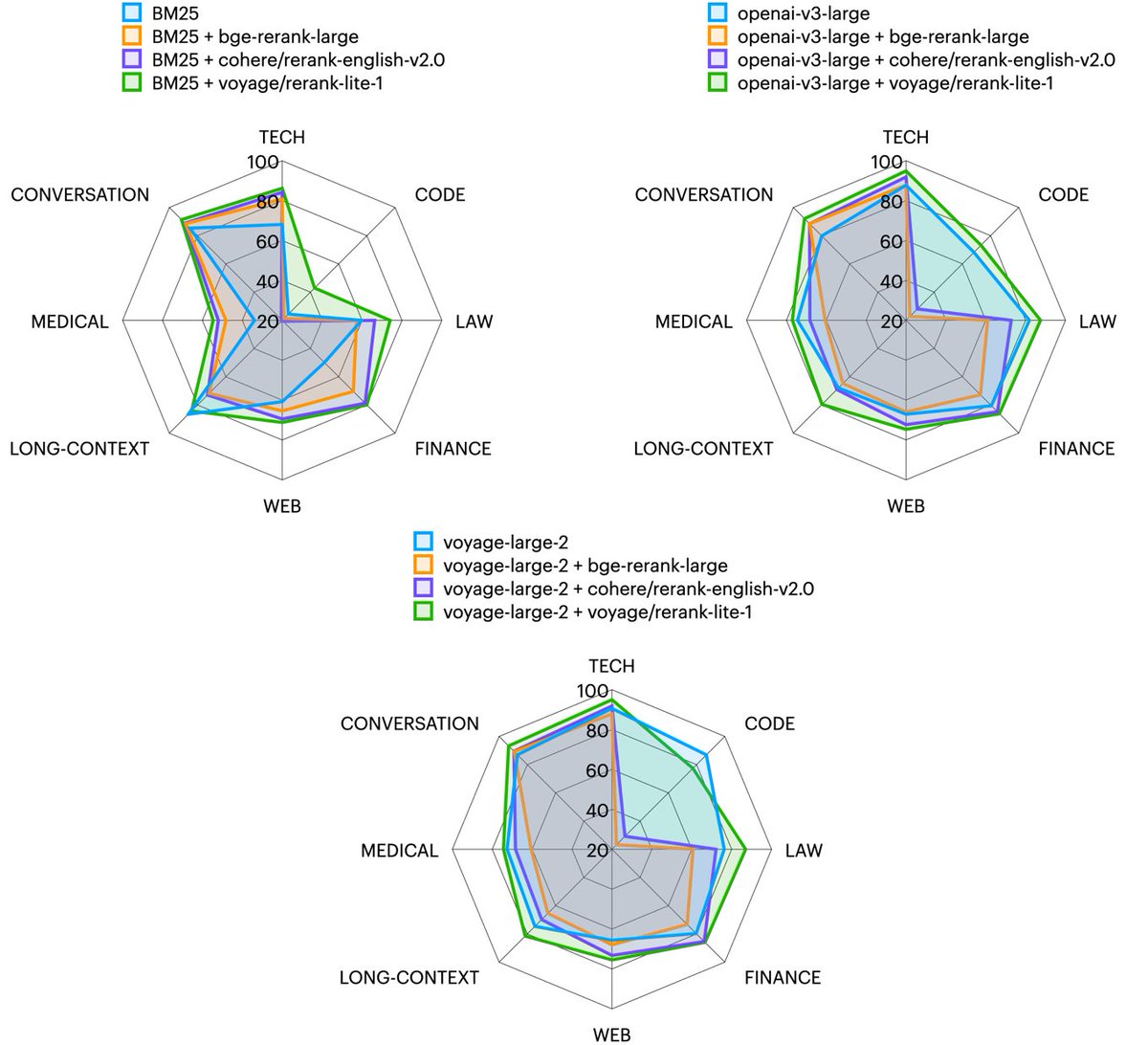
🆕📢 Excited to announce our first reranker, rerank-lite-1: state-of-the-art in retrieval accuracy on 27 datasets across domains (law, finance, tech, long docs, etc.), enhancing various search methods, vector-based or lexical. 🧵
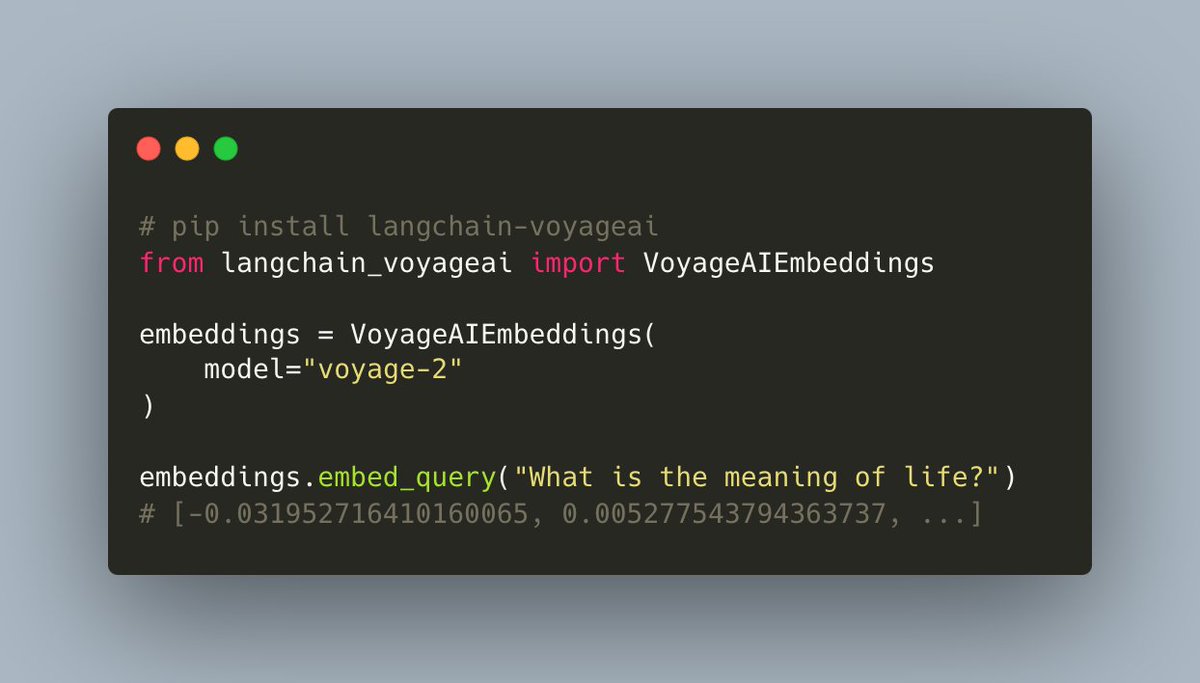
⛵ @Voyage_AI_ Embedding Integration Package ↗️
Use the same custom embeddings that power Chat LangChain via the new langchain-voyageai package! Recommended by @AnthropicAI as their preferred embedding provider, Voyage AI builds custom embedding models for your company or domain, improving retrieval quality over your document types.
ChatLangChain: https://t.co/EsAAjrpHgB
Python Docs: https://t.co/ClpxYF9NDQ
My colleague and friend, Leland Wilkinson, passed away on Friday. It was such an honor to work with Lee, and to be his friend. He was brilliant, he made incredible contributions to visualization and statistical computing, and on top of all that he was a genuinely kind person.
Some folks still seem confused about what deep learning is. Here is a definition:
DL is constructing networks of parameterized functional modules & training them from examples using gradient-based optimization.... https://t.co/jmHpWZOMH8