Offline Reinforcement Learning is a rapidly growing area of AI that studies how agents can learn optimal decision-making policies from previously collected data without further interaction with the environment. Unlike classical reinforcement learning, where an agent continuously explores and gathers new experiences, offline RL relies entirely on a static dataset of state-action-reward transitions.
This setting is particularly important when exploration is expensive, risky, or impossible. Examples include healthcare, autonomous driving, robotics, finance, and recommendation systems, where poor exploratory actions may have serious consequences.
In machine learning, offline RL combines ideas from supervised learning, sequential decision-making, and distributional estimation. In deep learning, large neural networks are used to learn value functions and policies from massive datasets. Modern algorithms such as Conservative Q-Learning (CQL) and Implicit Q-Learning (IQL) address the challenge of distributional shift, where the learned policy may choose actions rarely observed in the training data.
Offline RL is also becoming a foundation for data-driven AI systems trained from large historical datasets. The deeper insight is that intelligence can often be learned from experience that has already been collected. By transforming static data into sequential decision-making strategies, offline reinforcement learning bridges the gap between prediction and autonomous decision-making.
Image: https://t.co/pph5SAZGI8
Scientists have identified specific gut bacteria that appear to trigger multiple sclerosis (MS).
In a groundbreaking study conducted at Ludwig Maximilian University of Munich, researchers examined 81 pairs of identical twins in which only one sibling had MS. This unique design allowed them to control for genetic and environmental factors, isolating the role of the microbiome.
The team found that two bacterial species, Eisenbergiella tayi and Lachnoclostridium, were significantly more abundant in the twins with MS. When these microbes were transferred into mouse models, they directly induced MS-like autoimmune symptoms, providing strong causal evidence.
This is the most precise identification of microbial triggers for MS to date and adds powerful support to the gut-brain axis in autoimmune disease. The discovery raises hope for new approaches to early detection, prevention, and treatment — potentially by targeting or modulating these specific bacteria before symptoms appear.
While human clinical trials are still needed, the findings represent a major step toward microbiome-based therapies for MS and other autoimmune conditions.
[Yoon, H., Gerdes, L. A., Beigel, F., Sun, Y., Kövilein, J., Wang, J., Kuhlmann, T., Flierl-Hecht, A., Haller, D., Hohlfeld, R., Baranzini, S. E., Wekerle, H., & Peters, A. (2025). Multiple sclerosis and gut microbiota: Lachnospiraceae from the ileum of MS twins trigger MS-like disease in germfree transgenic mice—An unbiased functional study. Proceedings of the National Academy of Sciences, 122(18), e2419689122. DOI: 10.1073/pnas.2419689122]
🧡🧠 En el Día Mundial de la Esclerosis Múltiple, promovemos la comprensión y sensibilización sobre esta condición que afecta el sistema nervioso central y puede impactar distintas áreas de la vida de quienes la padecen.
La detección temprana, el seguimiento médico y el acceso oportuno a la atención pueden contribuir a mejorar la calidad de vida. 💙✨
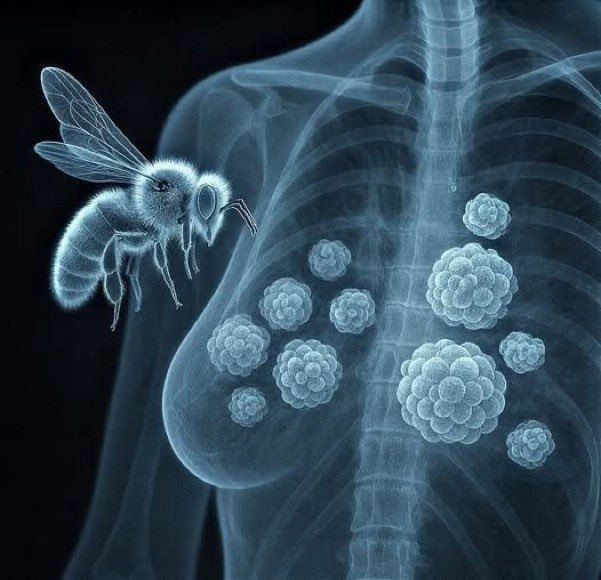
"Cancer de mama"
Porque descubrieron que el veneno de la abeja melífera puede destruir el 100% de las células de cáncer de mama en menos de 60 minutos.
One theorem every ML engineer should know:
The Bellman Optimality Principle.
It states that the optimal solution to a decision problem can be constructed recursively from optimal subproblems.
In reinforcement learning, this becomes:
Why it matters:
• Foundation of Q-learning and dynamic programming
• Enables sequential decision-making under uncertainty
• Central to robotics, game AI, and autonomous systems
• Connects optimization with learning
The profound idea:
Intelligence can emerge from recursively improving future decisions.
Almost every modern RL algorithm —
from DQN to AlphaGo —
builds on Bellman’s insight.
Reinforcement learning is ultimately the mathematics of long-term consequences.
Image: https://t.co/0kcXLNdthF
-Soy un Nazgül, uno de los Jinetes Negros, Espectro del Anillo y servidor de Sauron, el Señor Oscuro…
- ¿Ok, y el perrito?
- Ah, él es Firulais, pero no tenía con quien dejarlo y no le gusta quedarse solito…
Taylor Series aren’t just a calculus topic, they’re foundational to ML optimization. My latest video with @Cohere_Labs breaks down how local approximations of loss functions lead to Gradient Descent and Newton’s Method.
Watch here: https://t.co/EI5rbTK5lm
#MachineLearning#AI



































![Rainmaker1973's tweet photo. Scientists have identified specific gut bacteria that appear to trigger multiple sclerosis (MS).
In a groundbreaking study conducted at Ludwig Maximilian University of Munich, researchers examined 81 pairs of identical twins in which only one sibling had MS. This unique design allowed them to control for genetic and environmental factors, isolating the role of the microbiome.
The team found that two bacterial species, Eisenbergiella tayi and Lachnoclostridium, were significantly more abundant in the twins with MS. When these microbes were transferred into mouse models, they directly induced MS-like autoimmune symptoms, providing strong causal evidence.
This is the most precise identification of microbial triggers for MS to date and adds powerful support to the gut-brain axis in autoimmune disease. The discovery raises hope for new approaches to early detection, prevention, and treatment — potentially by targeting or modulating these specific bacteria before symptoms appear.
While human clinical trials are still needed, the findings represent a major step toward microbiome-based therapies for MS and other autoimmune conditions.
[Yoon, H., Gerdes, L. A., Beigel, F., Sun, Y., Kövilein, J., Wang, J., Kuhlmann, T., Flierl-Hecht, A., Haller, D., Hohlfeld, R., Baranzini, S. E., Wekerle, H., & Peters, A. (2025). Multiple sclerosis and gut microbiota: Lachnospiraceae from the ileum of MS twins trigger MS-like disease in germfree transgenic mice—An unbiased functional study. Proceedings of the National Academy of Sciences, 122(18), e2419689122. DOI: 10.1073/pnas.2419689122]](https://pbs.twimg.com/media/HKIT6zTWsAAuP-_.jpg)






![KirkDBorne's tweet photo. Linear Algebra and Optimization for Machine Learning [516-page textbook]: https://t.co/62bWLNwzd4
—————
#DataScience #DataScientist #ML #Mathematics #ORMS https://t.co/qjuogyrQg8](https://pbs.twimg.com/media/HH7u-t8XQAAlx7J.jpg)





















