Dear Italy,
Your PM just defended Pope and lost an ally in Washington — the Commander in Grief, yet the most 'powerfool'man on earth.
We'd like to apply for the vacancy.
Our qualifications: 7,000 years of civilization, a shared love of poetry, architecture, and food that takes longer to prepare than Trump's attention span.
The only thing Iran and Italy have ever fought over is who invented ice cream. Faloodeh came first. Gelato came louder. We've been in a 'cold' war over this for 2,000 years.
🚨🇮🇷🇦🇪🇸🇦 BREAKING: CNN claims the UAE & Saudi Arabia had asked Iran to designate a spot in the Iranian desert to bomb and declare it as a response to Iran’s attacks—which Iran reportedly rejected.
lol
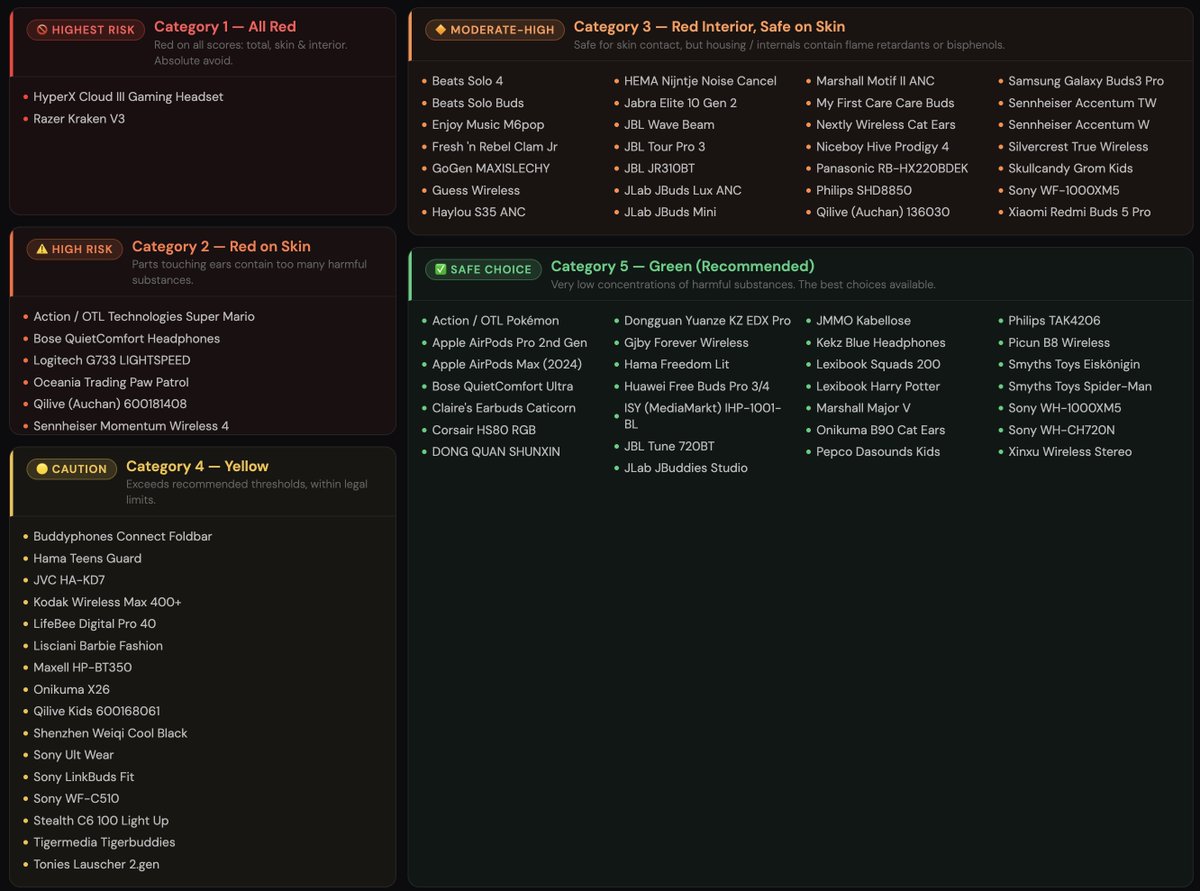
Dutch scientists: Your headphones are making you gay.
A lab in the Netherlands performed tests on numerous headphones and found them to possess endocrine-disrupting chemicals, which mimic hormones, that can cause neurodevelopmental problems and the feminization of males.
Leading products from Bose, Panasonic, Samsung and some Sennheiser headphones and other companies are now being pulled off the shelves.
Notable on the list of headphones possessing dangerous levels of these chemicals are gaming headphones from Razer.
“Daily use – especially during exercise when heat and sweat are present – accelerates this migration directly to the skin.”
From the study: Bisfenol A (BPA). Easy to enter your body through your skin when you wear the headphones for long or when you sweat while having them on. Even small quantities can weaken your immune system, cause fertility issues and allergic rashes.
NVIDIA just removed one of the biggest friction points in Voice AI.
PersonaPlex-7B is an open-source, full-duplex conversational model.
Free, open source (MIT), with open model weights on @huggingface 🤗
Links to repo and weights in 🧵↓
The traditional ASR → LLM → TTS pipeline forces rigid turn-taking.
It’s efficient, but it never feels natural.
PersonaPlex-7B changes that.
This @nvidia model can listen and speak at the same time.
It runs directly on continuous audio tokens with a dual-stream transformer, generating text and audio in parallel instead of passing control between components.
That unlocks:
→ instant back-channel responses
→ interruptions that feel human
→ real conversational rhythm
Persona control is fully zero-shot!
If you’re building low-latency assistants or support agents, this is a big step forward 🔥
We’re launching full-length, on demand practice exams for standardized tests in @GeminiApp, starting with the SAT, available now at no cost.
Practice SATs are grounded in rigorously vetted content in partnership with @ThePrincetonRev, and Gemini will provide immediate feedback highlighting where you excelled and where you might need to study more.
To try it out, tell Gemini, “I want to take a practice SAT test.”
Repeating your prompt can make LLMs significantly more accurate.
Google just showed a trivial change that wins 47 of 70 tests.
No extra tokens. No added latency. Zero losses reported.
𝗣𝗿𝗼𝗺𝗽𝘁 𝗿𝗲𝗽𝗲𝘁𝗶𝘁𝗶𝗼𝗻 𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝘀 𝗮𝗰𝗰𝘂𝗿𝗮𝗰𝘆
The method is simple. Send the exact same input twice, back to back.
Language models read tokens in order.
Early parts get processed without full context.
On the second pass, the full picture already exists.
Predictions become more stable and more accurate.
𝗜𝘁 𝘄𝗼𝗿𝗸𝘀 𝗮𝗰𝗿𝗼𝘀𝘀 𝗺𝗮𝗷𝗼𝗿 𝗺𝗼𝗱𝗲𝗹𝘀
The paper tests popular systems at scale.
Every evaluated model improves without reasoning enabled.
Key results:
> 47 wins out of 70 benchmarks
> Zero accuracy regressions
> No increase in output length
> No measurable latency cost
𝗜𝘁 𝗮𝗹𝗹𝗼𝘄𝘀 𝗱𝗿𝗼𝗽-𝗶𝗻 𝗱𝗲𝗽𝗹𝗼𝘆𝗺𝗲𝗻𝘁
Outputs keep the same format. Existing pipelines stay unchanged.
You get higher accuracy by copying and pasting once.