It also has "Claude Tag"-style interactivity and multiplayer features, but built for Discord and optimized for keeping up with AI news. Check it out here:
https://t.co/E8YTwdBZgv
I got tired of trying to keep up with AI.
So I built 𝗸𝗲𝗲𝗽-𝘂𝗽-𝘄𝗶𝘁𝗵 to have Codex do it for me
It turns Codex into your personal assistant that doomscrolls socials for you, researches each post, and keeps you updated on the stories that matter.
In my first week running it, Codex processed over 3,000 events and turned them into 248 updates, 72 research threads, and 511 thread posts.
It did most of the reading and deep diving so I didn’t have to, saving me hours of time.
The goal is to support autoresearch-like workflows with more flexible, evolutionary-like branching and lightweight experiment management, without adding heavy external deps, services, or databases.
Example: https://t.co/cTyEIKftMO
Repo: https://t.co/yIPNZDsnfI
I wanted to extend Karpathy's autoresearch with branching + memory while still keeping it simple. I call it autoevolve.
The idea: just use git to track experiments too: each commit can include the code changes + EXPERIMENT.json (metrics/metadata) + JOURNAL.md (notes/learnings).
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
As a test, I ran Codex with GPT-5.4 xhigh + autoevolve on the circle packing (n=26) problem, and it found a solution matching the best-known (afaik) sum radii of 2.635983084917.
Claude Code and Gemini CLI were able to reach similar results with the same setup as well.
@himbodhisattva@MistralAI Hey, these results were obtained using temperature=0 and max_tokens=1280. I ran these after helping migrate the eval to EleutherAI's LM evaluation harness, you can see the config for the eval here: https://t.co/RUx6L95ENW. Feel free to dm me if you have further questions!
Running IFEval (Instruction Following Evaluation) on multiple models to test their ability to follow "verifiable instructions" per https://t.co/heAkayUpUC.
Findings: Mixtral 8x7b-instruct (@MistralAI) leads, closely approaching GPT-3.5's performance. Among 7b models, OpenHermes 2.5 (@teknium, @NousResearch) performs really well, with OpenChat 3.5 (@openchatdev) right behind.
Good point! I’m using lm-evaluation-harness for running these evals though and idk if it supports benchmarking APIs like Mistral yet. But yeah, would be interesting to see the performance for mistral-medium as well as e.g. gemini. Also want to run some evals for the 34b models and see where they’re at.
Trying to keep up with all of @_akhaliq's daily paper updates, so I built a @Gradio app to help turn papers into threads 🧵 that I can quickly skim.
LayoutParser to extract figures and GPT-4 via the Assistant API to generate threads.
🤗Spaces: https://t.co/EM6EzMBfIF
🔗Code: https://t.co/K8TZ61eV4N
A quick look at 𝗣𝗮𝗽𝗲𝗿 𝗧𝗵𝗿𝗲𝗮𝗱𝗼𝗼𝗿 GPT 🧵
A custom GPT designed to write threads from academic papers.
Simply upload your PDF, and 𝗣𝗮𝗽𝗲𝗿 𝗧𝗵𝗿𝗲𝗮𝗱𝗼𝗼𝗿 will write a thread to showcase its key points and insights, including relevant figures and tables. 📄✨
If you want to explore the study further, or contribute to the ongoing research, you can check out the following resources:
🔗 Repo: https://t.co/Q5lBuhf0lO
📓 Notebook: https://t.co/7IuLB3kxTK
(7/n)
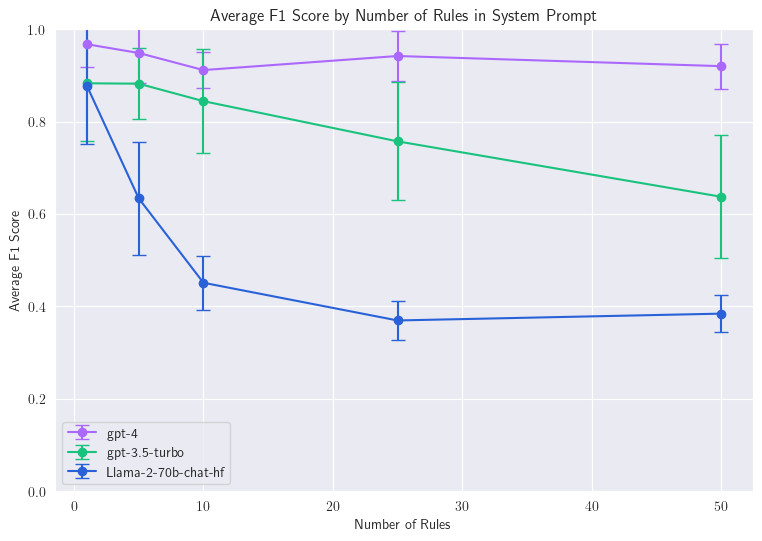
Ever wonder how many rules LLMs can follow before they're overwhelmed❓
🔍 Study Results
🥇 GPT-4 easily takes on an impressive 50 rules!
🥈 GPT-3.5 starts to struggle after 10
🥉 LLAMA-2-70b-chat stumbles even at 5
As we add more rules, the models vary in resilience
🧵 (1/n)
Prompt engineering steers LLMs using system messages. As business demands evolve, encoding complex & abstract rules becomes essential for chatbots. LLMs vary significantly in their ability to adhere to large sets of instructions, which heavily impacts their reliability.
(6/n)