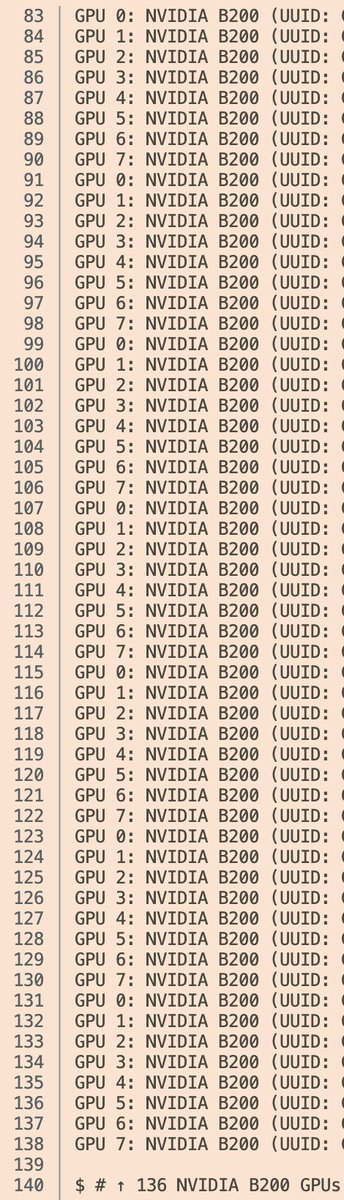
In case you wanted to know how to find a treasure: 🏴☠️
"Eighteen Bold letters Preserved In a clearing"
There are 18 gigantic concrete letters piled in a field near India Basin Park, remnants of a sign created by Michael Manwaring and removed in 2020. They're intended to eventually be repurposed as park signage. The physical letters are uppercase I, B, and P, lowercase the rest. This wouldn't be locatable from the Internet alone.
"a dark room's view..."
Camera Obscura and its view to surfers, and surf fisherman, reeling.
"dry ruin's gate"
Fleishhacker Pool. Only a meager doorway remains of this once great saltwater pool. For those looking at Sutro Baths, we'd note that those ruins are still quite wet.
"solar's tall mast"
The Point of Infinity on what is technically Yerba Buena Island, but colloquially referred to as Treasure(!) Island. The sculpture is billed as a quasi-sundial by artist Hiroshi Sugimoto. Yes, this clue is within the city of San Francisco.
"chart a historic cross"
Draw lines between these points and, in true treasure hunting fashion, X really does mark the spot. The X lands just off the Historic Trail in Mount Sutro Open Space Preserve.
"To trace the true route...night...pack a light"
From the X there are small indicators which glow under UV light directing you about 5 minutes down the trail and up a side trail to a rock outcropping.
"steadfast basin, where feet part and agree"
The chest was buried about 8 inches deep, in a hollow nested amid large boulders. The trail briefly and clearly splits in two, parting around the rocks.
But the quality of the model mattered a lot. In the simulated runs where Opus and Haiku models negotiated with one-another, the Opus models got substantially better deals.
Interestingly, though, participants in our survey didn’t pick up on this disparity.
We're missing (at least one) major paradigm for LLM learning. Not sure what to call it, possibly it has a name - system prompt learning?
Pretraining is for knowledge.
Finetuning (SL/RL) is for habitual behavior.
Both of these involve a change in parameters but a lot of human learning feels more like a change in system prompt. You encounter a problem, figure something out, then "remember" something in fairly explicit terms for the next time. E.g. "It seems when I encounter this and that kind of a problem, I should try this and that kind of an approach/solution". It feels more like taking notes for yourself, i.e. something like the "Memory" feature but not to store per-user random facts, but general/global problem solving knowledge and strategies. LLMs are quite literally like the guy in Memento, except we haven't given them their scratchpad yet. Note that this paradigm is also significantly more powerful and data efficient because a knowledge-guided "review" stage is a significantly higher dimensional feedback channel than a reward scaler.
I was prompted to jot down this shower of thoughts after reading through Claude's system prompt, which currently seems to be around 17,000 words, specifying not just basic behavior style/preferences (e.g. refuse various requests related to song lyrics) but also a large amount of general problem solving strategies, e.g.:
"If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step."
This is to help Claude solve 'r' in strawberry etc. Imo this is not the kind of problem solving knowledge that should be baked into weights via Reinforcement Learning, or least not immediately/exclusively. And it certainly shouldn't come from human engineers writing system prompts by hand. It should come from System Prompt learning, which resembles RL in the setup, with the exception of the learning algorithm (edits vs gradient descent). A large section of the LLM system prompt could be written via system prompt learning, it would look a bit like the LLM writing a book for itself on how to solve problems. If this works it would be a new/powerful learning paradigm. With a lot of details left to figure out (how do the edits work? can/should you learn the edit system? how do you gradually move knowledge from the explicit system text to habitual weights, as humans seem to do? etc.).