Black Friday sales begins! 20% off on all products at https://t.co/eIkI80XsCQ. RT this message and you will have a chance to get EverDrive or FXPAK for free! Winner will be chosen 02.12.2025 #GIVEAWAY
Congrats to @MSFTResearch on AesCoder-4B, a tiny model that introduces GRPO-AR to jointly optimize functionality and code aesthetics, holding its own against models 100x its size
Our team is proud to see SOTA cite Design Arena as baseline
Official Design Arena results coming soon
Thrilled to introduce #PART, a new method to protect LLM reasoning from unauthorized distillation while keeping it transparent for users. By removing self-talk and reordering conclusions, we disrupt illicit training and preserve valuable information.
https://t.co/HE1vzFOfeZ
Beyond just text quality! We're introducing #DocReward, a model that evaluates and improves the visual structure and style of documents. In our tests, DOCREWARD achieved a 60.8% win rate in generating human-preferred documents, compared to GPT-5's 37.7%.
https://t.co/ChY9z0X05f
KOSMOS 2.5 by @Microsoft has finally been integrated into @huggingface Transformers 🙌🔥
End-to-end document AI model similar to Donut/Pix2Struct, pre-trained on 357.4 million documents
Handles image-to-markdown, OCR with spatial coordinates and chatting with documents!
How do you stop an LLM from getting “thrown off” by a few wild tokens?
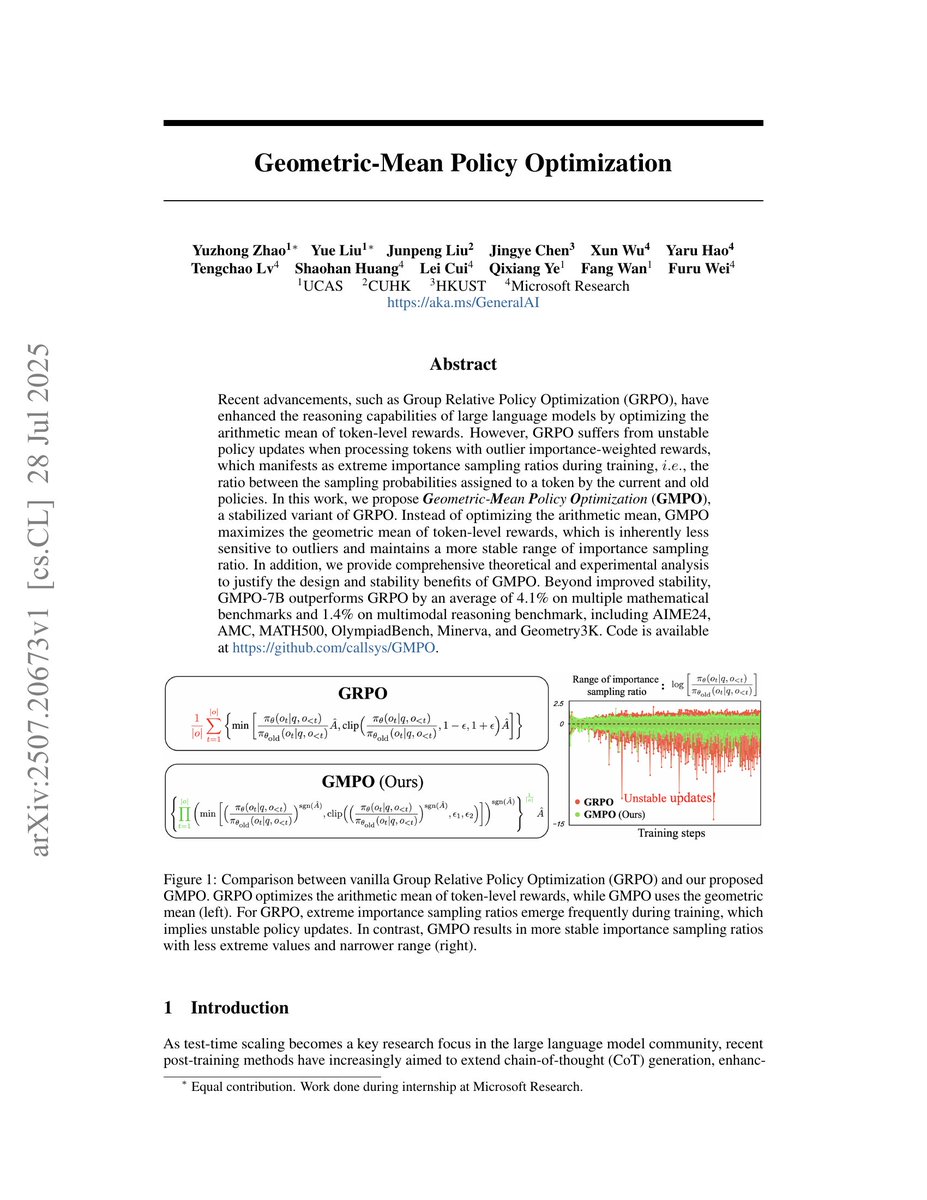
UCAS, CUHK, HKUST, and Microsoft Research researchers think they’ve cracked it with Geometric-Mean Policy Optimization (GMPO) — a twist on GRPO that tames outliers by optimizing the geometric mean of token-level rewards.
Result: more stable training, +4.1% on math benchmarks, +1.4% on multimodal reasoning.
Top AI Papers of The Week (July 28 - August 3):
- GEPA
- Graph-R1
- AlphaEarth
- Self-Evolving Agents
- Hierarchical Reasoning Model
- Efficient Attention Mechanisms
- Geometric-Mean Policy Optimization
Read on for more:
Microsoft Research introduces Geometric-Mean Policy Optimization (GMPO)!
A new RL method that stabilizes LLM reasoning by maximizing the geometric mean of token-level rewards.
No more unstable updates!
GMPO outperforms GRPO by 4.1% on math & 1.4% on multimodal reasoning benchmarks.
It achieves better stability and performance, moving us closer to reliable AI.
Learn more & get the code:
Paper: https://t.co/Mh8kJjLeV0
Code: https://t.co/eDEGGiCCPF
RL(LLM) - Pisałem ostatnio o GSPO. A dzisiaj publikacje na temat -> GMPO - Geometric-Mean Policy Optimization, ARPO - Agentic Reinforced Policy Optimization, IRL - Inverse RL … Chyba najbardziej kwitnący obszar treningowy LLM.
U nas Bielik-v3 też już trenowany RL (GRPO, DR-GRPO, DAPO, GSPO - przygotowane) … czekamy na nową bazę. Wczoraj zakończyłem pracować nad największym polskim matematycznym datasetem treningowym RL - blisko 500k unikalnych i weryfikowalnych polskich zdań. Będzie moc 😁
Team - Krzysiek Ociepa @ChrisOciepa , Łukasz Flis, Adrian Gwoździej, Krzysiek Wróbel i moje wsparcie - pracuje teraz na pełnych obrotach. Dream team🤩Praca sama idzie. Nowe pomysły wdrażane w kilka minut, nie trzeba za wiele mówić - delivery najważniejsze. Ekstra pracuje się w takiej ekipie. Codziennie mamy postęp!
Ogromne wsparcie @Cyfronet ❤️🔥
8. Geometric-Mean Policy Optimization
🔑 Keywords: Geometric-Mean Policy Optimization, Policy Updates, Token-Level Rewards, Multimodal Reasoning, AI Native
💡 Category: Natural Language Processing
🌟 Research Objective:
- The research aims to stabilize policy updates in large language models through Geometric-Mean Policy Optimization (GMPO), enhancing the performance on mathematical and multimodal reasoning benchmarks.
🛠️ Research Methods:
- GMPO introduces the use of geometric mean for token-level rewards to provide a less sensitive approach to outliers and maintain stable importance sampling ratios. Comprehensive theoretical and experimental analyses are conducted to validate GMPO's design and stability benefits.
💬 Research Conclusions:
- GMPO demonstrates improved stability and a performance increase, surpassing GRPO by 4.1% on mathematical benchmarks and 1.4% on multimodal reasoning benchmarks like AIME24, AMC, MATH500, OlympiadBench, Minerva, and Geometry3K.
👉 Paper link: https://t.co/rGre3jOZJI












![fly51fly's tweet photo. [CL] Geometric-Mean Policy Optimization
Y Zhao, Y Liu, J Liu, J Chen... [Microsoft Research] (2025)
https://t.co/PninMQ9mD0 https://t.co/yYqOjpMcSB](https://pbs.twimg.com/media/GxDnGaPbUAAwOSb.jpg)
![fly51fly's tweet photo. [CL] Geometric-Mean Policy Optimization
Y Zhao, Y Liu, J Liu, J Chen... [Microsoft Research] (2025)
https://t.co/PninMQ9mD0 https://t.co/yYqOjpMcSB](https://pbs.twimg.com/media/GxDnGS_acAAKjJ8.jpg)
![fly51fly's tweet photo. [CL] Geometric-Mean Policy Optimization
Y Zhao, Y Liu, J Liu, J Chen... [Microsoft Research] (2025)
https://t.co/PninMQ9mD0 https://t.co/yYqOjpMcSB](https://pbs.twimg.com/media/GxDnF1sbUAA1tTG.jpg)
















![fly51fly's tweet photo. [CL] Geometric-Mean Policy Optimization
Y Zhao, Y Liu, J Liu, J Chen... [Microsoft Research] (2025)
https://t.co/PninMQ9mD0 https://t.co/yYqOjpMcSB](https://pbs.twimg.com/media/GxDnGzHbUAAr6JM.jpg)