🚨 SWE-rebench big March-May update!
SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub.
updates:
> we collected more fresh and complex tasks
> we ran 110 tasks × 5 for each model / scaffold
> the differences between models and scaffolds are now easier to distinguish
> we will update the task set every two months, with model updates in between
insights:
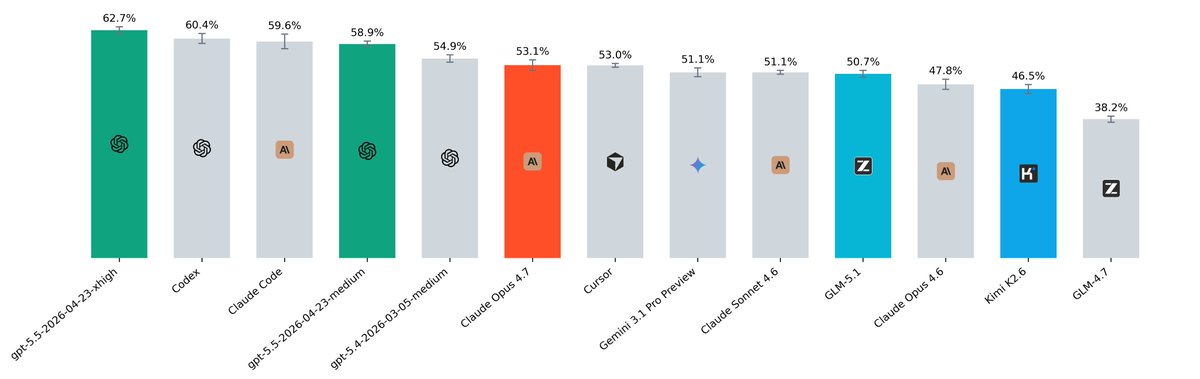
> GPT-5.5 xhigh takes #1 with 62.7% resolved and 70.0% pass@5
> Cursor with Composer 2.5 is very cheap and strong: around 8× cheaper than Claude Code and Codex, and scores higher than open-weight models! @leerob
Model updates will come in 1–2 weeks. Please send requests for models you want us to run!
🏆 Full leaderboard (check for price / tokens per problem, pass@5, scaffold params, etc):
https://t.co/9jL4lt4UGl
👾 Join our Discord:
https://t.co/cyWgceqqDa
We are back again :) After three weeks of quiet building.
Introducing Genesis World 1.0, our latest simulation platform, the second release in our full-stack suite. Open-sourced.
Robotics is still bottlenecked by the 1× speed of the physical world. Every model, checkpoint, and data recipe eventually needs to be tested on physical hardware, slowly, expensively, and with limited coverage.
One hour in reality can become 100 days in simulation. That is how robotics model iteration moves from a wall-clock bottleneck to a compute problem.
To make this work, simulation has to be both fast and trustworthy.
Over the past year, we rebuilt the entire stack: a GPU-accelerated cross-platform compiler, penetration-free multi-physics contact solvers, unified rigid and deformable physics, and a photo-realistic renderer purpose-built for physical AI applications.
We built Nyx, a high-performance path-traced rendering engine for robotics application.
Genesis World 1.0 achieves near realtime performance with our latest development for penetration-free IPC solver, supporting various types of deformables beyond rigid bodies. It supports contact-rich, dexterous manipulation simulation across different embodiments: unitree, sharpa, wuji, genesis hand and various types of grippers.
Under the hood is Quadrants, our effort in pushing forward cross-platform GPU-accelerated computation. Quadrants started as a fork of Taichi, and we rebuilt most of the critical parts for optimizing simulation workloads, giving 10x faster launch time and up to 4.6x runtime performance compared to the initial Genesis release.
Together, they bring us to an unprecedentedly low sim-to-real gap, enabling zero-shot real-to-sim model evaluation and much faster iteration of GENE.
All available today.
Genesis World 1.0: https://t.co/aknCM3eqws
Quadrants: https://t.co/uXqPNI4cb6
Nyx: https://t.co/R8j0djqGnV
We built a bipedal robot for about $2,500.
A real, mostly 3D-printed robot you can build, repair, simulate, train, and control.
Today we’re releasing LeRobot Humanoid: an open robot-learning platform with hardware, runtime, identification tools, and training environments.
Blog post: https://t.co/zu2etb1NZo
Repo: https://t.co/4myLRUtZ3W
There is nothing more powerful than well-informed optimism. It has to be well-informed though. The "everything will be fine" type of optimism may also be somewhat useful, but it's not as useful as the "Hmm, what if we tried x?" kind.
Software engineering isn’t dead
And in fact it might be more alive than ever
You can actually do engineering now
As opposed to being constrained by typing and a mythical man month
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
New Research💡: “The #Enterprise#AI Playbook — Lessons from 51 Successful Deployments”
Excited to share new research from Stanford @DigEconLab, I co-authored with @erikbryn and Elisa Pereira .
We spent 5 months interviewing executives across 41 organizations, 9 industries, and 7 countries — focusing exclusively on AI deployments that actually delivered measurable value. Not hype. Not predictions. What’s working right now, and why.
A few findings that challenged even our assumptions:
The hard part isn’t the AI. 77% of the toughest challenges were invisible costs — change management, data quality, process redesign. Technology was consistently described as the easiest part.
Same use case, wildly different timelines. One company deployed AI customer support in weeks. Another took years. Same models. The difference was always the #organization — its #leadership, processes, and willingness to fail.
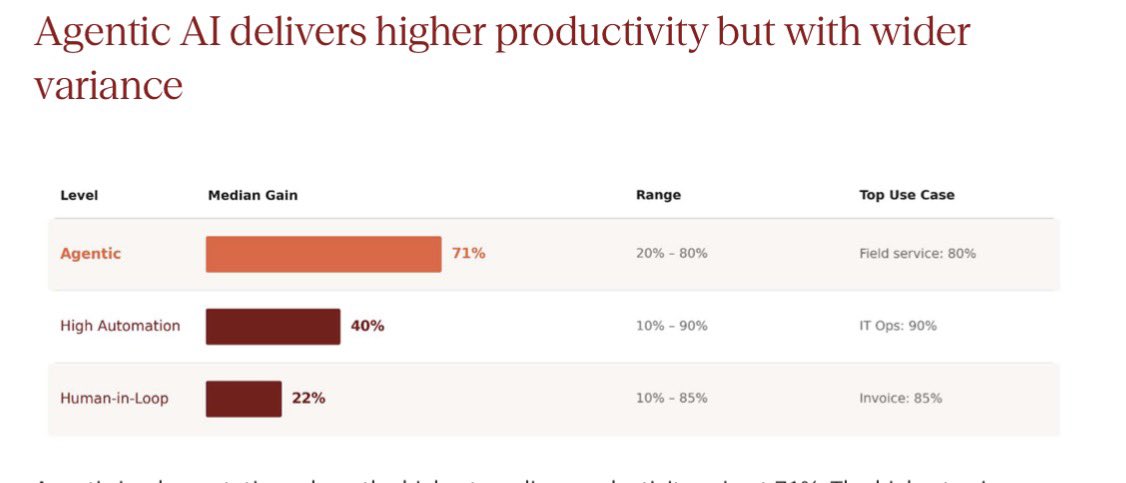
#Agentic AI works — but most firms haven’t tried it yet. Only 20% of our cases were agentic, but they delivered 71% median gains vs. 40% for high-automation. This gap will widen fast.
The model is increasingly a #commodity. For 42% of implementations, model choice was fully interchangeable. The durable advantage is in orchestration, data, and process — not the foundation model.
With productivity increase, headcount #reduction is common (45%), but not the majority outcome. Redeployment, hiring avoidance, and acceleration strategies accounted for 55% of cases.🚨
The window for experimentation is closing. This is no longer a question of whether AI delivers value. It’s whether organizations can evolve fast enough to capture it — and whether leaders will take responsibility for smoothing the transition for workers and communities along the way.
Full report (free): https://t.co/G9eRzG9ugD
@StanfordHAI
Introducing Chroma Context-1, a 20B parameter search agent.
> pushes the pareto frontier of agentic search
> order of magnitude faster
> order of magnitude cheaper
> Apache 2.0, open-source
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
You can now enable Claude to use your computer to complete tasks.
It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk.
Research preview in Claude Cowork and Claude Code, macOS only.
This robotic hand can be 3D printed by anyone and assembled in under 8 hours.
Researchers at ETH Zurich created the Orca hand, fully open-sourced with artificial bones and tendons.
For context, advanced robotic hands cost over $100,000 and require constant maintenance...
Orca costs under $2,000. 50x less (!)
A self-calibration system maps every motor to every joint, eliminating the manual tuning that tendon-driven hands usually need.
Each fingertip has built-in tactile sensors covered by silicone skin.
The hand can actually feel when it touches something, giving it feedback to grip objects without crushing them or letting them slip.
It can hold over 20 lbs, learn tasks by watching human demonstrations, and transfer skills trained in simulation directly to the real world.
The team proved its durability by having it pick up and place a cube over 2,000 times across 7 hours with no human intervention.
The full design files and source code are open source, so any robotics lab in the world can start building one today.
Prof. Donald Knuth opened his new paper with "Shock! Shock!"
Claude Opus 4.6 had just solved an open problem he'd been working on for weeks — a graph decomposition conjecture from The Art of Computer Programming.
He named the paper "Claude's Cycles."
31 explorations. ~1 hour. Knuth read the output, wrote the formal proof, and closed with: "It seems I'll have to revise my opinions about generative AI one of these days."
The man who wrote the bible of computer science just said that. In a paper named after an AI.
Paper: https://t.co/juSOmK9vOt