Every traditional org chart makes the same assumption: all workers are human. The entire structure, departments, reporting lines, seniority levels, spans of control, exists to organize people.
Except that... AI agents don’t fit into that structure.
https://t.co/UELOVU162s
CEO of Microsoft AI Mustafa Suleyman joins FT editor Roula Khalaf to explain why most of the tasks accountants, lawyers and other professionals currently undertake will be fully automated by AI within the next 12 to 18 months https://t.co/yYKzS7NIOP
Every enterprise is buying AI tools. Almost none can tell you if they're working. That's the problem I'm solving at @olakai_ai, and the conversation I'll be having a lot more of here.
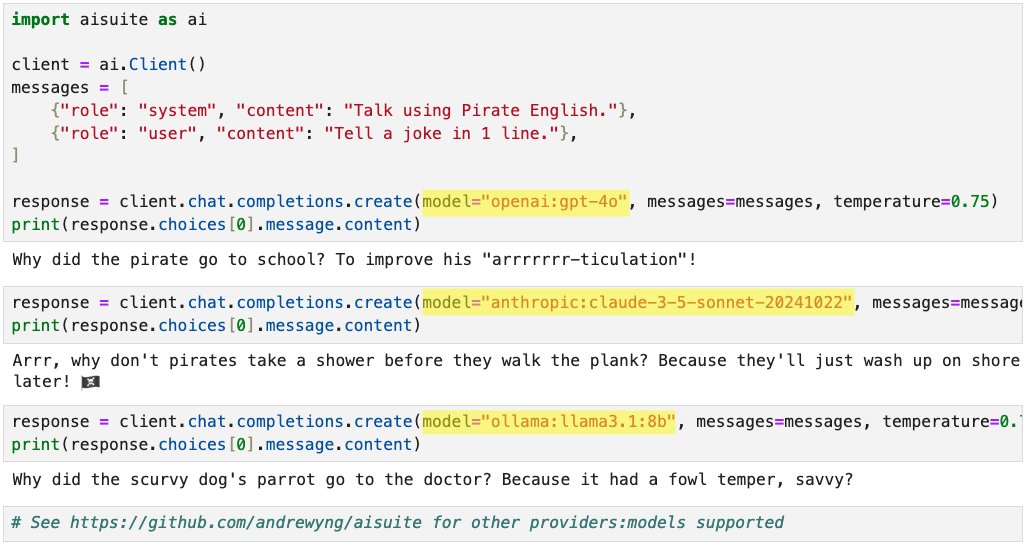
Announcing new open-source Python package: aisuite!
This makes it easy for developers to use large language models from multiple providers. When building applications I found it a hassle to integrate with multiple providers. Aisuite lets you pick a "provider:model" just by changing one string, like openai:gpt-4o, anthropic:claude-3-5-sonnet-20241022, ollama:llama3.1:8b, etc.
pip install aisuite
Open-source code with instructions: https://t.co/gwz9oKTCFx
Thanks to Rohit Prsad, Kevin Solorio, @standsleeping, Jeff Tang and @Johnsanterre for helping build this!
Large language models (LLMs) are typically optimized to answer peoples’ questions. But there is a trend toward models also being optimized to fit into agentic workflows. This will give a huge boost to agentic performance!
Following ChatGPT’s breakaway success at answering questions, a lot of LLM development focused on providing a good consumer experience. So LLMs were tuned to answer questions (“Why did Shakespeare write Macbeth?”) or follow human-provided instructions (“Explain why Shakespeare wrote Macbeth”). A large fraction of the datasets for instruction tuning guide models to provide more helpful responses to human-written questions and instructions of the sort one might ask a consumer-facing LLM like those offered by the web interfaces of ChatGPT, Claude, or Gemini.
But agentic workloads call on different behaviors. Rather than directly generating responses for consumers, AI software may use a model in part of an iterative workflow to reflect on its own output, use tools, write plans, and collaborate in a multi-agent setting. Major model makers are increasingly optimizing models to be used in AI agents as well.
Take tool use (or function calling). If an LLM is asked about the current weather, it won’t be able to derive the information needed from its training data. Instead, it might generate a request for an API call to get that information. Even before GPT-4 natively supported function calls, application developers were already using LLMs to generate function calls, but by writing more complex prompts (such as variations of ReAct prompts) that tell the LLM what functions are available and then have the LLM generate a string that a separate software routine parses (perhaps with regular expressions) to figure out if it wants to call a function.
Generating such calls became much more reliable after GPT-4 and then many other models natively supported function calling. Today, LLMs can decide to call functions to search for information for retrieval augmented generation (RAG), execute code, send emails, place orders online, and much more.
Recently, Anthropic released a version of its model that is capable of computer use, using mouse-clicks and keystrokes to operate a computer (usually a virtual machine). I’ve enjoyed playing with the demo. While other teams have been prompting LLMs to use computers to build a new generation of RPA (robotic process automation) applications, native support for computer use by a major LLM provider is a great step forward. This will help many developers!
As agentic workflows mature, here is what I am seeing:
- First, many developers are prompting LLMs to carry out the agentic behaviors they want. This allows for quick, rich exploration!
- In a much smaller number of cases, developers who are working on very valuable applications will fine-tune LLMs to carry out particular agentic functions more reliably. For example, even though many LLMs support function calling natively, they do so by taking as input a description of the functions available and then (hopefully) generating output tokens to request the right function call. For mission-critical applications where generating the right function call is important, fine-tuning a model for your application’s specific function calls significantly increases reliability. (But please avoid premature optimization! Today I still see too many teams fine-tuning when they should probably spend more time on prompting before they resort to this.)
- Finally, when a capability such as tool use or computer use appears valuable to many developers, major LLM providers are building these capabilities directly into their models. Even though OpenAI o1-preview’s advanced reasoning helps consumers, I expect that it will be even more useful for agentic reasoning and planning.
Most LLMs have been optimized for answering questions primarily to deliver a good consumer experience, and we’ve been able to “graft” them into complex agentic workflows to build valuable applications. The trend of LLMs built to support particular operations in agents natively will create a lot of lift for agentic performance. I’m confident that large agentic performance gains in this direction will be realized in the next few years.
[Original text: https://t.co/gginTyOgwe ]
Thank you Governor @GavinNewsom for vetoing SB-1047 -- your pro-innovation leadership is much appreciated!
And to the many people who've been pushing back on SB-1047, a huge thank you as well. Congratulations to all -- we won! 🎉
Looking ahead, lets keep on protecting AI open-source and innovation. We must make sure AI policy is based on science, not science fiction!
After a recent price reduction by OpenAI, GPT-4o tokens now cost $4 per million tokens (using a blended rate that assumes 80% input and 20% output tokens). GPT-4 cost $36 per million tokens at its initial release in March 2023. This price reduction over 17 months corresponds to about a 79% drop in price per year. (4/36 = (1 - p)^{17/12})
As you can see, token prices are falling rapidly! One force that’s driving prices down is the release of open weights models such as Llama 3.1. If API providers, including startups Anyscale, Fireworks, Together AI, and some large cloud companies, do not have to worry about recouping the cost of developing a model, they can compete directly on price and a few other factors such as speed.
Further, hardware innovations by companies such as Groq (a leading player in fast token generation), Samba Nova (which serves Llama 3.1 405B tokens at an impressive 114 tokens per second), and wafer-scale computation startup Cerebras (which just announced a new offering this week), as well as the semiconductor giants NVIDIA, AMD, Intel, and Qualcomm, will drive further price cuts.
When building applications, I find it useful to design to where the technology is going rather than only where it has been. Based on the technology roadmaps of multiple software and hardware companies — which include improved semiconductors, smaller models, and algorithmic innovation in inference architectures — I’m confident that token prices will continue to fall rapidly.
This means that even if you build an agentic workload that isn’t entirely economical, falling token prices might make it economical at some point. As I wrote previously, being able to process many tokens is particularly important for agentic workloads, which must call a model many times before generating a result. Further, even agentic workloads are already quite affordable for many applications. Let's say you build an application to assist a human worker, and it uses 100 tokens per second continuously: At $4/million tokens, you'd be spending only $1.44/hour – which is significantly lower than the minimum wage in the U.S. and many other countries.
So how can AI companies prepare?
- First, I continue to hear from teams that are surprised to find out how cheap LLM usage is when they actually work through cost calculations. For many applications, it isn’t worth too much effort to optimize the cost. So first and foremost, I advise teams to focus on building a useful application rather than on optimizing LLM costs.
- Second, even if an application is marginally too expensive to run today, it may be worth deploying in anticipation of lower prices.
- Finally, as new models get released, it might be worthwhile to periodically examine an application to decide whether to switch to a new model either from the same provider (such as switching from GPT-4 to the latest GPT-4o-2024-08-06) or a different provider, to take advantage of falling prices and/or increased capabilities.
Because multiple providers now host Llama 3.1 and other open-weight models, if you use one of these models, it might be possible to switch between providers without too much testing (though implementation details — specifically quantization, does mean that different offerings of the model do differ in performance). When switching between models, unfortunately, a major barrier is still the difficulty of implementing evals, so carrying out regression testing to make sure your application will still perform after you swap in a new model can be challenging. However, as the science of carrying out evals improves, I’m optimistic that this will become easier.
[Original text (with links): https://t.co/txk7q32EXn ]
I wrote last week about why working on a concrete startup or project idea — meaning a specific product envisioned in enough detail that we can build it for a specific target user — lets you go faster. In this letter, I’d like to share some best practices for identifying promising ideas.
AI Fund, which I lead, works with many corporate partners to identify ideas, often involving applications of AI to the company’s domain. Because AI is applicable to numerous sectors such as retail, energy, logistics and finance, I’ve found working with domain experts who know these areas well immensely helpful for identifying what applications are worth building in these areas.
Our brainstorming process starts with recommending that a large number of key contributors at our partner corporation (at least 10 but sometimes well over 100) gain a non-technical, business-level understanding of AI and what it can and can’t do. Taking https://t.co/zpIxRSuky4’s “Generative AI for Everyone” course is a popular option, after which a company is well positioned to assign a small team to coordinate a brainstorming process, followed by a prioritization exercise to pick what to work on. The brainstorming process can be supported by a task-based analysis of jobs in which we decompose employees’ jobs into tasks to identify which ones might be automated or augmented using AI.
Here are some best practices for these activities:
(i) Trust the domain expert’s gut. A domain expert who has worked for years in a particular sector will have well honed instincts that let them make leaps that would take a non-expert weeks of research.
Let’s say we’re working with a financial services expert and have developed a vague idea (“build a chatbot for financial advice”). To turn this into a concrete idea, we might need to answer questions such as what areas of finance to target (should we focus on budgeting, investing, or insurance?) and what types of user to serve (fresh graduates, mortgage applicants, new parents, or retirees?) Even a domain expert who has spent years giving financial advice might not know the best answer, but a choice made via their gut gives a quick way to get to one plausible concrete idea. Of course, if market-research data can be obtained quickly to support this decision, we should take advantage of it. But to avoid slowing down too much, we’ve found that experts’ gut reactions work well and are a quick way to make decisions.
So, if I’m handed a non-concrete idea, I often ask a domain expert to use their gut — and nothing else — to quickly make decisions as needed to make the idea concrete. The resulting idea is only a starting point to be tweaked over time. If, in the discussion, the domain expert picks one option but seems very hesitant to disregard a different option, then we can also keep the second option as a back-up that we can quickly pivot to if the initial one no longer looks promising.
(ii) Generate many ideas. I usually suggest coming up with at least 10 ideas; some will come up with over 100, which is even better. The usual brainstorming advice to go for volume rather than quality applies here. Having many ideas is particularly important when it comes to prioritization. If only one idea is seriously considered — sometimes this happens if a senior executive has an idea they really like and puts this forward as the “main” idea to be worked on — there’s a lot of pressure to make this idea work. Even if further investigation discovers problems with it — for example, market demand turns out to be weak or the technology is very expensive to build — the team will want to keep trying to make it work so we don’t end up with nothing.
In contrast, when a company has many ideas to choose from, if one starts to look less interesting, it’s easy to shift attention to a different one. When many ideas are considered, it’s easier to compare them to pick the superior ones. As explained in the book Ideaflow, teams that generate more ideas for evaluation and prioritization end up with better solutions.
Because of this, I’ve found it helpful to run a broad brainstorming process that involves many employees. Specifically, large companies have many people who collectively have a lot of wisdom regarding the business. Having a small core team coordinate the gathering of ideas from a large number of people lets us tap into this collective fountain of invention. Many times I’ve seen a broad effort (involving, say, ~100 people who are knowledgeable about the domain and have a basic understanding of AI) end up with better ideas than a narrow one (involving, say, a handful of top executives).
(iii) Make the evaluation criteria explicit. When evaluating and prioritizing, clear criteria for scoring and ranking ideas helps the team to judge ideas more consistently. Business value and technical feasibility are almost always included. Additionally, many companies will prioritize projects that can be a quick win (to build momentum for their overall AI efforts) or support certain strategic priorities such as growth in a particular part of the business. Making such criteria explicit can help during the idea-generation phase, and it’s critical when you evaluate and prioritize.
In large companies, it can take a few weeks to go through a process to gather and prioritize ideas, but this pays off well in identifying valuable, concrete ideas to pursue. AI isn’t useful unless we find appropriate ways to apply it, and I hope these best practices will help you to generate great AI application ideas to work on.
[Original text: https://t.co/7pwXMGEbpI ]
we think there is room to make search much better than it is today.
we are launching a new prototype called SearchGPT: https://t.co/A28Y03X1So
we will learn from the prototype, make it better, and then integrate the tech into ChatGPT to make it real-time and maximally helpful.
One reason for machine learning’s success is that our field welcomes a wide range of work. I can’t think of even one example where someone developed what they called a machine learning algorithm and senior members of our community criticized it saying, “that’s not machine learning!” Indeed, linear regression using a least-squares cost function was used by mathematicians Legendre and Gauss in the early 1800s — long before the invention of computers — yet machine learning has embraced these algorithms, and we routinely call them “machine learning” in introductory courses!
In contrast, about 20 years ago, I saw statistics departments at a number of universities look at developments in machine learning and say, “that’s not really statistics.” This is one reason why machine learning grew much more in computer science than statistics departments. (Fortunately, since then, most statistics departments have become much more open to machine learning.)
This contrast came to mind a few months ago, as I thought about how to talk about agentic systems that use design patterns such as reflection, tool use, planning, and multi-agent collaboration to produce better results than zero-shot prompting. I had been involved in conversations about whether certain systems should count as “agents.” Rather than having to choose whether or not something is an agent in a binary way, I thought, it would be more useful to think of systems as being agent-like to different degrees. Unlike the noun “agent,” the adjective “agentic” allows us to contemplate such systems and include all of them in this growing movement.
More and more people are building systems that prompt a large language model multiple times using agent-like design patterns. But there’s a gray zone between what clearly is not an agent (prompting a model once) and what clearly is (say, an autonomous agent that, given high-level instructions, plans, uses tools, and carries out multiple, iterative steps of processing).
Rather than arguing over which work to include or exclude as being a true agent, we can acknowledge that there are different degrees to which systems can be agentic. Then we can more easily include everyone who wants to work on agentic systems. We can also encourage newcomers to start by building simple agentic workflows and iteratively make their systems more sophisticated.
In the past few weeks, I’ve noticed that, while technical people and non-technical people alike sometimes use the word “agent,” mainly only technical people use the word “agentic” (for now!). So when I see an article that talks about “agentic” workflows, I’m more likely to read it, since it’s less likely to be marketing fluff and more likely to have been written by someone who understands the technology.
Let’s keep working on agentic systems and keep welcoming anyone who wants to join our field!
[Original text: https://t.co/4izf1hsv9P ]
Retail is facing a multi-$100B problem:
• Excess inventory is up 23%
• Sales growth is down 5.8%
• Foot traffic is down 2.3% YoY at malls…on Black Friday
But it gets even worse.
Let me explain:
@heykahn He's missing the point. The emphasis on math isn't due to the French or the Russians (??) but because math is fundamental to all STEM subjects.






























![AndrewYNg's tweet photo. One reason for machine learning’s success is that our field welcomes a wide range of work. I can’t think of even one example where someone developed what they called a machine learning algorithm and senior members of our community criticized it saying, “that’s not machine learning!” Indeed, linear regression using a least-squares cost function was used by mathematicians Legendre and Gauss in the early 1800s — long before the invention of computers — yet machine learning has embraced these algorithms, and we routinely call them “machine learning” in introductory courses!
In contrast, about 20 years ago, I saw statistics departments at a number of universities look at developments in machine learning and say, “that’s not really statistics.” This is one reason why machine learning grew much more in computer science than statistics departments. (Fortunately, since then, most statistics departments have become much more open to machine learning.)
This contrast came to mind a few months ago, as I thought about how to talk about agentic systems that use design patterns such as reflection, tool use, planning, and multi-agent collaboration to produce better results than zero-shot prompting. I had been involved in conversations about whether certain systems should count as “agents.” Rather than having to choose whether or not something is an agent in a binary way, I thought, it would be more useful to think of systems as being agent-like to different degrees. Unlike the noun “agent,” the adjective “agentic” allows us to contemplate such systems and include all of them in this growing movement.
More and more people are building systems that prompt a large language model multiple times using agent-like design patterns. But there’s a gray zone between what clearly is not an agent (prompting a model once) and what clearly is (say, an autonomous agent that, given high-level instructions, plans, uses tools, and carries out multiple, iterative steps of processing).
Rather than arguing over which work to include or exclude as being a true agent, we can acknowledge that there are different degrees to which systems can be agentic. Then we can more easily include everyone who wants to work on agentic systems. We can also encourage newcomers to start by building simple agentic workflows and iteratively make their systems more sophisticated.
In the past few weeks, I’ve noticed that, while technical people and non-technical people alike sometimes use the word “agent,” mainly only technical people use the word “agentic” (for now!). So when I see an article that talks about “agentic” workflows, I’m more likely to read it, since it’s less likely to be marketing fluff and more likely to have been written by someone who understands the technology.
Let’s keep working on agentic systems and keep welcoming anyone who wants to join our field!
[Original text: https://t.co/4izf1hsv9P ]](https://pbs.twimg.com/media/GP98LglbEAMeQBC.jpg)



















