On the Job Market📍Santa Clara | PhDone @UCR_CSE | interpretability, alignment, compositionality of diffusion models | EX - @AdobeFirefly, @SonyAI_global
Most diffusion research today asks: How can we sample faster?
But I think another question is equally important: Are we training diffusion models in the right way?
https://t.co/WYHNXJamhi
This is my first time turning some of my research thoughts into a blog post, so it may contain errors or unclear arguments. Any suggestions, comments, or feedback would be greatly appreciated🙌
Most diffusion research today asks: How can we sample faster?
But I think another question is equally important: Are we training diffusion models in the right way?
https://t.co/WYHNXJamhi
Today we're releasing ZAYA1-74B-Preview, a major milestone in scaling pretraining on @AMD.
ZAYA1-74B-Preview is a 4B active / 74B total MoE.
This preview model is a strong pre-RL base checkpoint. The final post-trained reasoning model is coming soon. 🧵
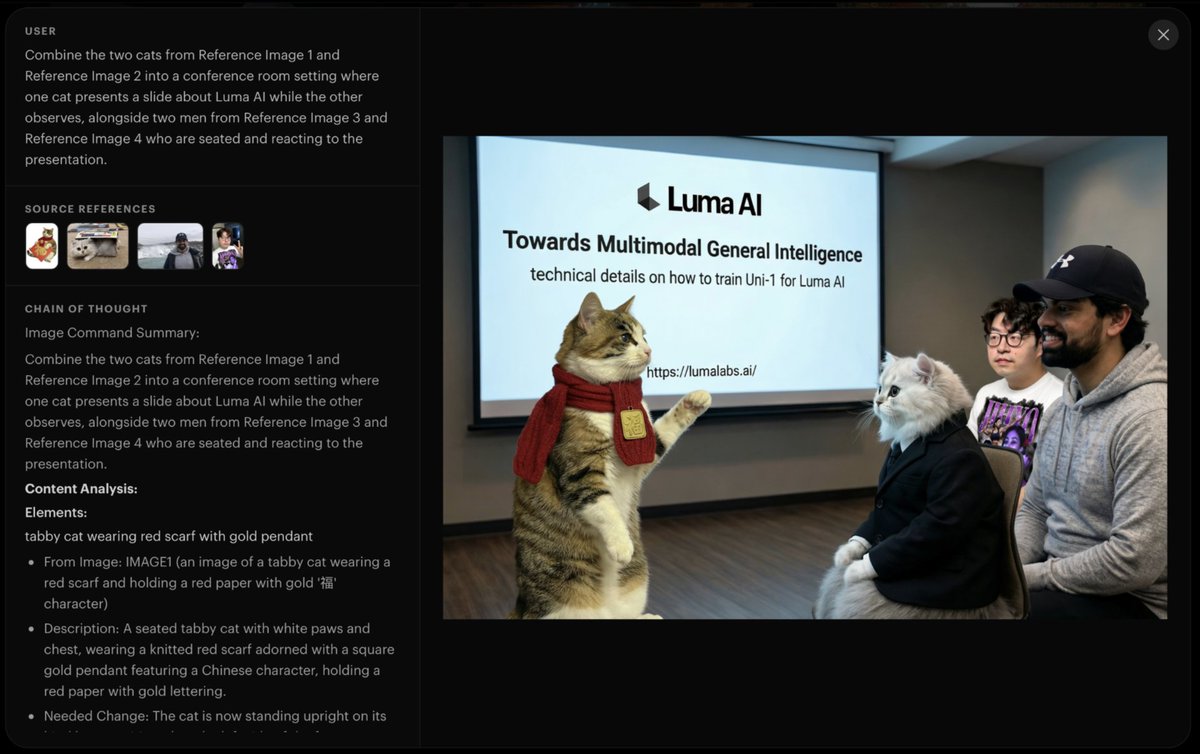
Really excited to see Uni-1 out in the world 🔥Our first unified model.
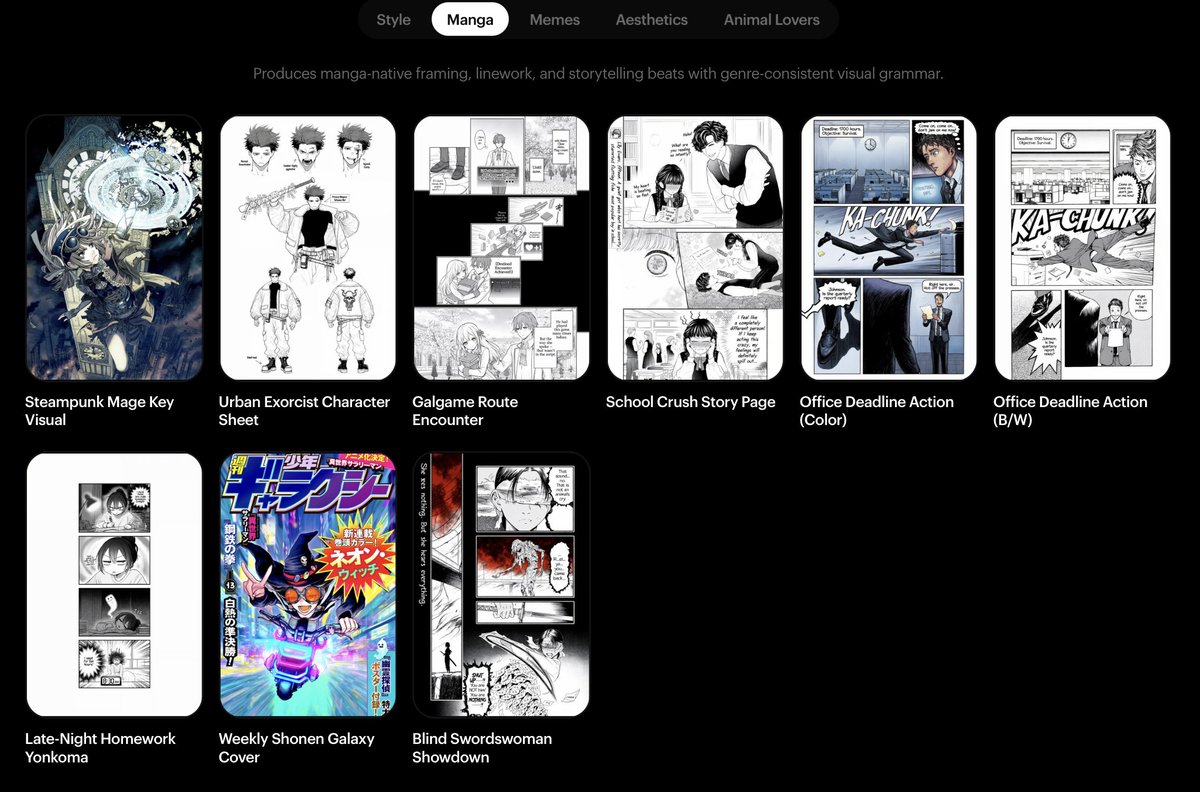
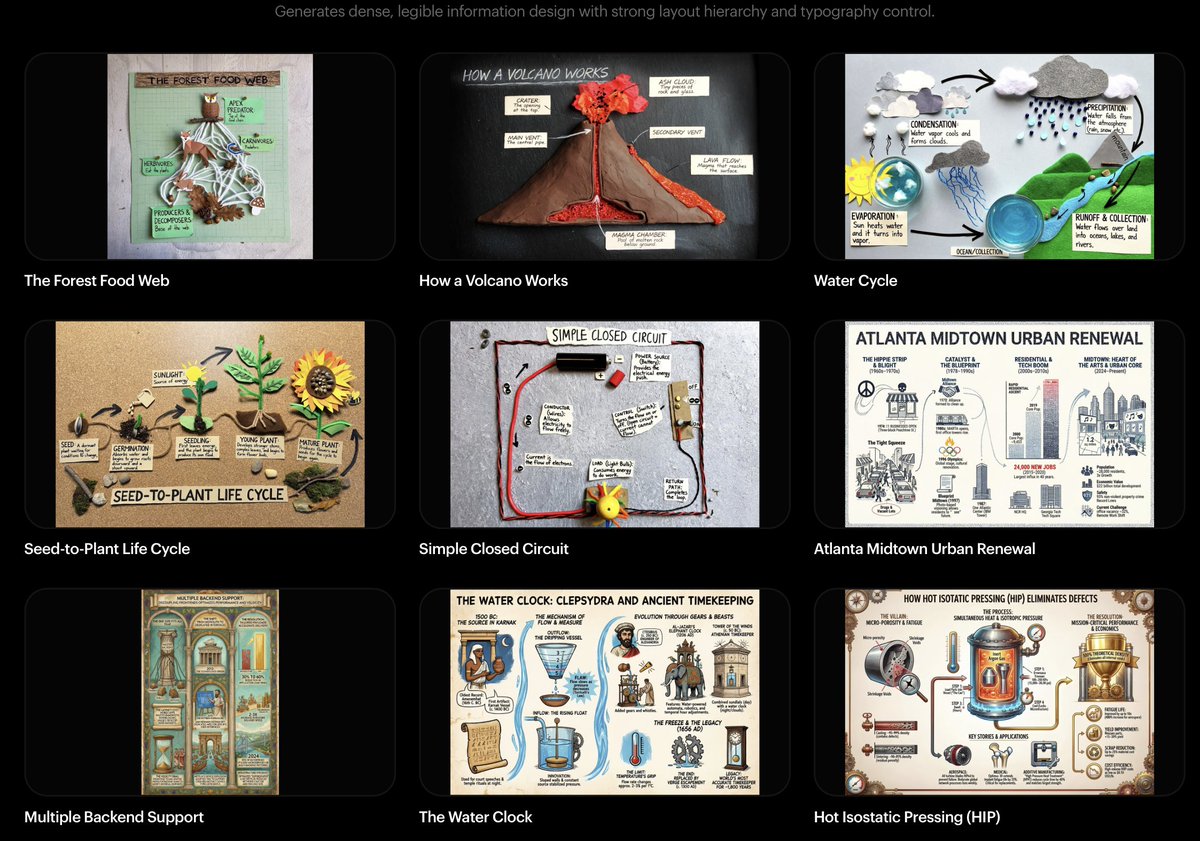
The range of things this model can do is wild: image-to-~100 styles, manga generation, multi-ref with strong identity preservation, temporal storytelling, sketch-to-image, spatial reasoning, multilingual infographics, layering… the capability range is honestly unreal. this is just the start 🫡 check out the blog to learn more https://t.co/B8Nedl86Dk
Proud of the team and what we’re building at @LumaLabsAI 🚀
@hudsonyeoce Cool cool! We’ve mastered alignment for nouns in image/video models, but verbs (or more abstract terms) are the real challenge in video. Seeing this kind of motion control proves Runway’s cracking the code on abstract concepts🔥
I’m currently in transit to San Diego for NeurIPS. If you’re also killing time, feel free to check out a 2-minute-30-second horror sci-fi short film Michael and I recently created. We’d love any comments or likes:
https://t.co/MW9h7PIHah
Looking forward to catching up at the venue! 🎥
I feel the debate shouldn’t only be about whether DiT is effective, but also about how information preservation is the key to accelerating diffusion training. Our MicroDiT (https://t.co/uRWJRzAJRp) paper showed this: by letting masked token info mix into unmasked ones, we can cut down a lot of tokens with only minor performance loss.
Interestingly, two months ago, when I caught up with @StefanABaumann at #CVPR, we discussed how TREAD and MicroDiT are conceptually similar from info perspective. Maybe it’s time to look at diffusion through an information-theoretic lens: from post-training (for the better alignment) to latent space curation, I believe this could lead to some really exciting discoveries!
Introducing Look Studio.
Style looks from scratch with 1M+ products from designer brands - including shoes, multiple layers and more.
Reply for an invite.
Excited to introduce Reka Vision, an agentic visual understanding and search platform. Transform your unstructured multimodal data into insights and actions.
Introducing our V1 Video Model. It's fun, easy, and beautiful. Available at 10$/month, it's the first video model for *everyone* and it's available now.
Heading to Nashville 🎸 for @CVPR (06/11 - 06/16)!
Always excited to catch up with old friends and make new connections. Let’s grab a coffee ☕️ or chat about diffusion models, post-training, or just life!
#CVPR2025#Diffusion#GenerativeAI#Nashville