Good evening.
I’m getting a lot of questions about whether my conviction has been impaired or my thesis has changed about Bitcoin with its recent price weakness. The answer is an emphatic no. Why? Because I like to keep it simple and focus on first principles. While other assets are enjoying the warmth of the hot ball of money, Bitcoin will simply continue to reflect the debasement of all government sponsored currencies over the long run. Nothing more. Nothing less. Hope this helps.
Have a great night.
I see you train up to 2017 and then use 2018-2026 as hold out data. This might be very conservative, but maybe that’s a plus. BTC crosses different adoption/growth regimes and if one uses walk forward while testing out of sample it allows sampling more regimes when fitting and testing. In this case you have a single cutoff point and this will be more demanding for any prediction model tested. I browsed the 170 pages PDF, don’t know a thing about option markets, but I wonder if a more compact version would work better. Just my 2 cents, Carlos.
42 slides, background for my discussion with @timevalueofbtc this week
Bitcoin as a Logarithmic Time Standard: Power Laws, Network Dynamics, and Eco... by @Perrenod #bitcoin https://t.co/M95d93BdIJ via @Slideshare@ScientificBTC
AIDDA 2026 June 9 & 10
Two days on AI-driven algorithm discovery:
Talks
Panels
Workshops
Live automated discovery experiment
The focus: AI systems that search, test, mutate, and improve algorithms.
I can't believe this works, but I got DeepSeek-V4-Flash (284B params) running on a Raspberry Pi 5 (8GB edition) at >1tok/s @ ~8W during full-tilt inference! It uses an untouched copy of @antirez's GGUF. Took 160+ experiments over 5 days between GPT-5.5 xhigh and Opus 4.8 max.
I was able to reproduce (with Claude) most of your PL+LP model on my data; the match was almost perfect, so I think I got the correct parameters. So far, the combination PL+LP1 is the best out of sample, and the LP1 λ is very stable along cutoffs. The report states all details. https://t.co/L6voLjA6pH
While everyone if freeking out with the price action of BTC and with MSTR selling 32 coins, some lone researchers (me included) are deep into the weeds of digging if there are mathematical rules that bring sense to all this.
@originalafterx@moneyordebt I am currently reproducing log-periodic, on my evaluation framework, and have confirmed that while PL+LP3 wins in sample, the simpler version PL+LP1 is the best for out of sample prediction.
We will adopt new social norms.
An AI can generate an endless stream of code changes. I cannot read them all.
Sometimes it does not matter. If I am working on a web app for myself or a simple tool, I do not care. I can delegate to the AI.
If I am working on a software library that production systems rely on (like simdutf, simdjson, Roaring, etc.), then I am fully responsible for what I merge. This means I must fully comprehend the code—and yes, even the documentation.
I have been burned many times in the last 25 years. Someone proposes code; you review it quickly without fully understanding the change and merge it. Weeks, months, or years later, you regret it. You inherit technical debt and create trouble.
In mission-critical code, you are almost always better off not merging when in doubt.
For my open-source work, my reputation is on the line. And when you think about it, your reputation is all you have.
People proposing code, either with AI or without, often do not see it this way. Why won’t he take my code? Isn’t it just a power trip?
No, it is not. I dislike turning down code that people have worked hard on. I have empathy. I know how it feels to have your proposal rejected. It is not a great feeling.
But AI is something else.
I am not stupid. I know you can set up your AI to automatically write changes and submit them. You may even review them somewhat.
But you can easily overwhelm me. I am just one guy. I can only read code or documentation so fast.
“But Daniel, don’t you use AI? Try Claude Code!”
Yes. Yes. Yes. I have all the AIs. I have tried all the AIs. I use all the AIs.
Claude Code and Grok Build are better than the average coder in my view. But that is also because the average coder is not that great.
Coding is hard.
Simple puzzles like FizzBuzz can be difficult, and yes, they can still confuse Claude and other AIs.
“But it will get better!”
That does not really matter. Even if Linus Torvalds sent me C code, I would still need to understand it before merging it into mission-critical code. It is fine because Linus is one man and he won't be sending me 1000 code proposals.
So we will need new social norms very quickly.
Your AI contributions are welcome, but they must be produced in a way that respects whoever is responsible.
We have a scaling problem and it is not going away soon.
Maybe @elonmusk can create a neuralink device that allows me to review and understand code 100 x faster. Great if it happens. Thus far, I have not found a way to review code faster.
@HodlYourFuture@moneyordebt It might look overfitting, but they do out of sample evaluation with walk-forward forecasts. To me, that shows it is not overfitting. Support graph from Stephen Perrenod substack.
Bitcoin’s Not-so-Hidden Structure, by @moneyordebt https://t.co/dISENrh7ZJ
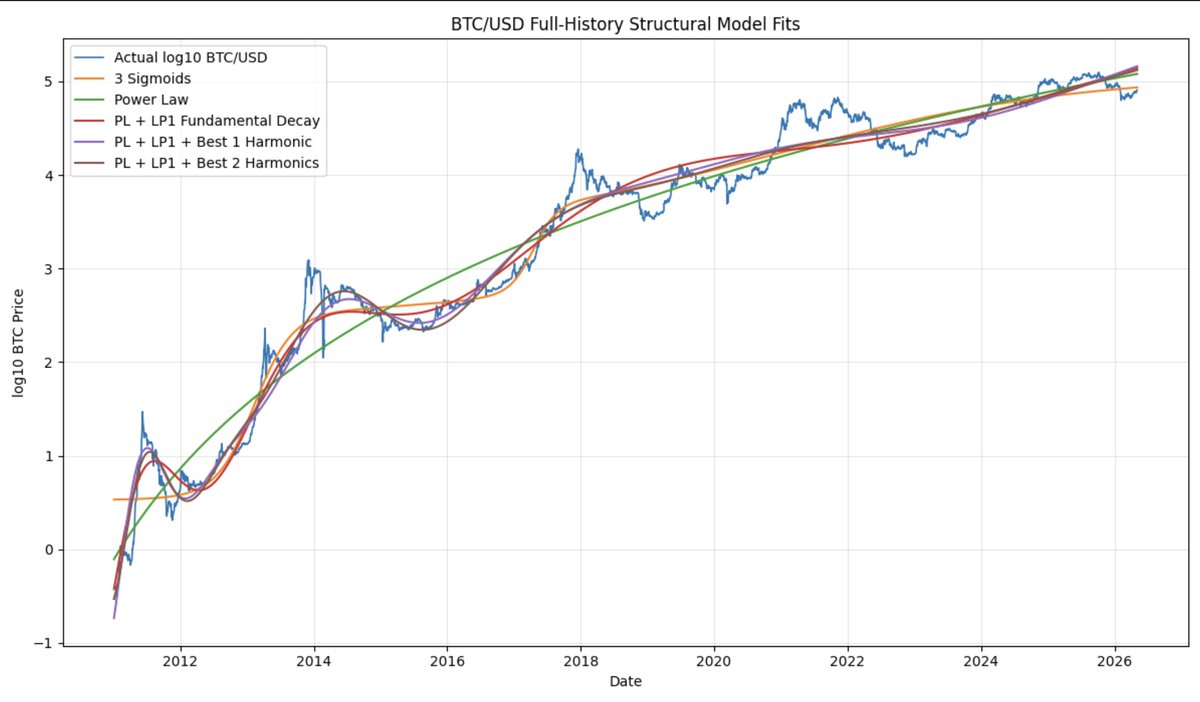
A paper by Baquero and Menezes found a better structural fit to Bitcoin price history with three superimposed sigmoid functions in comparison to the power law. However they required 10 parameters to do so, while the power law has only 2 parameters. They also found the power law to be better for longer-term forecasting.
In this article I demonstrate that the power law plus the fundamental log-periodic mode provide a better structural fit than three sigmoids, using only 5 parameters.
Forecasting is also enhanced relative to the power law, over intermediate timeframes.