When multimodal AI meets real-world expertise, reasoning gets harder, deeper, and much more exciting.
Join us at KnowledgeMR @ #CVPR2026 to push this frontier forward!
🗓️Thu June 4 | 8am | Room 704/706
Speakers: @thoma_gu@huang_biwei@pliang279@MengdiWang10@xwang_lk
🔥 Excited to share my new preprint: Can LLMs Use Linguistic Uncertainty Markers to Reliably Reflect Intrinsic Confidence? 🔥
When an LLM says "I think" or "probably," does it actually mean something consistent internally? The answer: not really 😬
Check out details in 🧵(1/n):
Traveling to #EMNLP2025 to present our work “MetaFaith: Faithful Natural Language Uncertainty Expression in LLMs” this week! 🇨🇳
Come by & let's chat about LLM faithfulness / uncertainty / calibration!
📍Poster Session 7 @ Hall C3
🗓Fri, Nov 7 @ 2-3:30p
🔗https://t.co/0PfY9FczhZ
📢 Our recent work - NLPBench: Evaluating Large Language Models on Solving NLP Problems
https://t.co/ggOhmx4Cup
🤔 Could LLMs answer college-level NLP questions like a human?
We introduce NLPBench, which consists of 378 college-level NLP questions spanning various NLP topics.
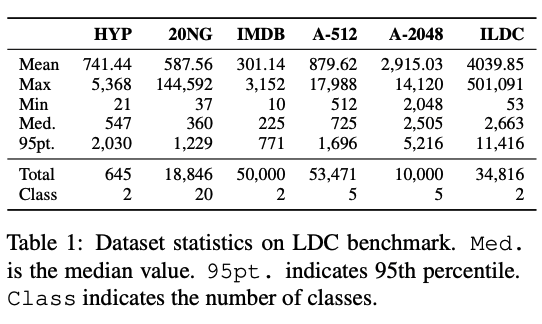
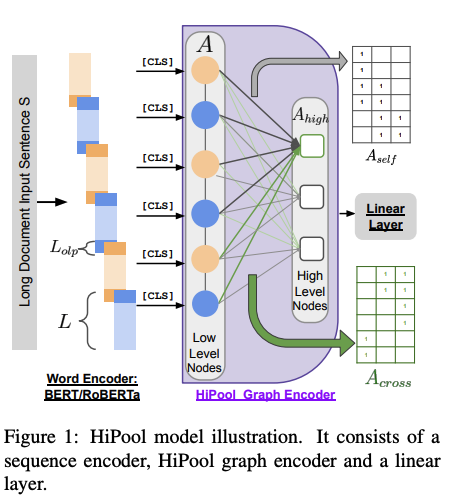
🎉@RexYing0923 AosongFeng @dragomir_radev Our recent work accepted at #ACL2023, a hierarchical model for long document classification. We also standardized the benchmark with six existing ones.
paper link: https://t.co/cobtU7Bw2Q
code link: https://t.co/6kFjHAGqRD
Lastly, I want to thank everyone that I’ve shared a meal, a coffee/drink or even just a conversation. I’m like 96.2% sure that I’m the only one from Yale that’s attending in person this year. Thanks for keeping me company and making me feel I’m not alone. 4/n,n=4
It’s also amazing how people from different countries and backgrounds can just meet up for the common passion for the local food or hikes, and became friends overnight. 3/n
I got to speak with people whose work had huge impact on mine, and ask about their opinions on my ongoing work. I also remember the joy I had when researchers I constantly cite came to my poster and told me they knew me and my work as well. 2/n
#ICLR2023 is my first in-person conference post-covid and it’s the most rewarding experience ever. I reunited with my friends, collaborators, mentors… some of which I haven’t seen in years and some I actually met in person for the first time. 1/n
Finding 3. The LM "curse of multilinguality" which causes per-language performance to drop as they cover more languages is minimal and inconsistent!
They conclude: some of the literature on the curse of multilinguality may need to be revisited using more diverse benchmarks.
4/5
Background: The Palm paper (https://t.co/lUxfbz3O3P) found parallel attention+MLP to be 15% faster but degrades quality at models with <8B parameters.
3/5
These findings from the Pythia paper (https://t.co/Vcbd1w8xv9) by @BlancheMinerva@haileysch__ et al., are fascinating:👇
Finding 1- Deduplication of training data shows no clear benefit, contrary to literature.
1/5 🧵
Our LongEval paper just received an outstanding paper award at #EACL2023 🏆
LongEval provides a way to improve inter annotator agreement while minimizing annotator workload in challenging task of long form summarization
Great work by @kalpeshk2011 and the team! Details below👇
Sending these tweets on my way to Kigali 🇷🇼! Hope to see everyone there! Feel free to DM me if you’d like to chat about program synthesis, LLM + Code, neuro-symbolic methods, and many more! 7/7
While the same NL specs can often be satisfied by different programs, most datasets only provides one for learning. This could easily lead to overfitting as the figure shown below.
In our new #ICLR2023 paper, we show how we can mitigate this issue with self-sampling 🧵1/7
My friend Drago just passed away. He left behind his wife, Axinia, and daughters, Laura and Victoria, who has a disability and requires care. We set up a GoFundMe so that Axinia can provide Victoria with the care she needs. If you can, please contribute: https://t.co/VSbLXBeCm7