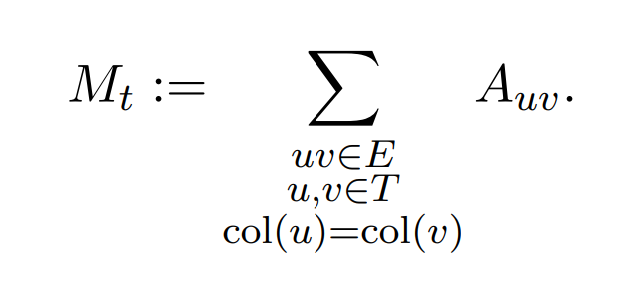@sushnt@rpeng233 Very nice! This feels like the "right proof" for the problem, and I fully expect that many more results of a similar style will be found by current and future models.
1/ Technical thread on #1stProof Problem 6: finding “spectrally light” vertex subsets in a graph, and how its solution fits into the landscape of spectral sparsification + restricted invertibility.
Original thread: https://t.co/c9Z9RH2Ont
My thoughts on #1stProof Problem 6 (closely related to areas I've worked in): OpenAI’s solution is essentially correct, and the difficulty feels consistent with AI capabilities over the past several months. More detail in the thread.
I don't personally want to rate the proof vs. human researchers. More concretely, I feel that current models so far are quite strong at proving self-contained statements whose solutions we believe are based on ideas in the literature (or are sufficiently short). To me, this framework captures the advances we've seen on both the IMO/competition side and the math research side.
Just for intuition: the official proof informally says that as long as a set does not have too much "mass" on its neighboring edges, then it's possible to add a new vertex to it. So if I have many sets, then by an averaging argument, one of them must have less mass than average, so we can safely add a vertex to it.
@TFWNicholson Yes, it should be the pseudoinverse. If the graph is connected (for these problems, this can be assumed without loss of generality), the only vector in the nullspace is (1, 1, ..., 1) so it's easy to get a handle on the pseudoinverse.
1/ Technical thread on #1stProof Problem 6: finding “spectrally light” vertex subsets in a graph, and how its solution fits into the landscape of spectral sparsification + restricted invertibility.
Original thread: https://t.co/c9Z9RH2Ont
My thoughts on #1stProof Problem 6 (closely related to areas I've worked in): OpenAI’s solution is essentially correct, and the difficulty feels consistent with AI capabilities over the past several months. More detail in the thread.
Still, I’m genuinely impressed by how far AI-for-math has come in the past few years, and I’m excited to see what’s next. If people want, I’m happy to write up more about the problem, the solution, and how it fits in the context of prior results.
End/ Overall Comparison: In my opinion, the problem and solution cleanly fall within the scope of previous methods, but one does have to nontrivially adapt the method to handle the subtlety described above. In terms of comparing the solutions, both give equally clean fixes to the issue. Worth noting that the OpenAI solution proves something slightly stronger than is asked by the problem statement: if proves that a constant fraction of the vertices can be partitioned into O(1/ε) groups, so that the induced Laplacian on every group is spectrally at most ε*L, while the problem only asks for a single group of size ≥ ε*n.
Finally, I want to mention an open problem in this direction. You can ask whether there are other natural objectives that can be sparsified down to size O(n/ε^2). Concretely, consider the function f(x) = |Ax|_1 where A is a m x n matrix. Is there a matrix A’ which is n’ x n, whose rows are reweightings of rows of A, and 0.5 * |Ax|_1 ≤ |A’ x|_1 ≤ 2 |Ax|_1, and n’ ≤ O(n)? The best known bound on n’ is O(n log n) by random sampling + chaining techniques.
10/ OpenAI solution: it maintains r ≈ 1/ε different sets S_1, …, S_r, whose total size eventually is a constant fraction of n. The solution proves that you can always find one of the sets to add a new vertex to without increasing the potential: this makes sense, because on average some set should be “light’’. In the screenshots below, M_t is the sum of Laplacians of each color class, and as you can see, the solution maintains a barrier function over M_t, and does not need to maintain any property of the leverage scores of S.